Chandra OCR 소개
Chandra OCR는 기존 OCR(Optical Character Recognition) 기술의 한계를 넘어서, 문서의 레이아웃 구조 , 시각적 관계 , 의미적 구성 을 모두 복원할 수 있는 차세대 AI 기반 문서 인식 시스템 입니다.이 모델은 Datalab 팀(창립자: Vik Paruchuri)에 의해 2025년 10월 공개되었으며, Hugging Face, GitHub, Datalab Playground 를 통해 오픈소스로 배포되고 있습니다.
Chandra는 단순한 OCR 모델을 넘어, 복잡한 레이아웃의 PDF 파일이나 손글씨가 섞인 양식, 수식이나 표가 포함된 문서 이미지들도 정확하게 인식합니다. 또한, 신문이나 논문과 같이 여러 단(column)으로 구성된 텍스트 및 이미지와 차트 등의 시각적 요소들까지 추출하여 구조화할 수 있습니다.
즉, Chandra는 단순히 텍스트를 읽기만 하는 OCR이 아니라, **“문서를 이해하고 재구성하는 AI 엔진”**이라고 표현할 수 있습니다.
기존의 전통적인 OCR 모델(예: Tesseract, EasyOCR, PaddleOCR 등)은 문자 단위 인식에 강점을 보였으나, 문서의 시각적 레이아웃과 구조적 정보를 완전하게 복원하는 데에는 한계가 있었습니다.
이와 달리 Chandra는 transformer 기반의 멀티모달 모델 구조 를 채택하여, 문서 내의 텍스트, 도형, 표, 이미지 등의 시각적 관계를 이해하고, 이를 Markdown, HTML, JSON 형태로 구조화된 출력으로 제공합니다.
Chandra OCR의 주요 특징
-
다중 포맷 출력 지원: Chandra는 PDF나 이미지 파일을 단순 텍스트로 변환하는 것이 아니라, 문서의 원본 구조를 최대한 유지하면서 Markdown, HTML, JSON 형태로 변환합니다. 이 덕분에 개발자는 문서의 구조적 정보(표, 이미지, 섹션, 수식 등)를 그대로 활용할 수 있습니다.
-
손글씨 및 폼(Form) 복원: 의료 문서, 설문지, 계약서 등에서 나타나는 손글씨 입력, 체크박스, 라벨-값 구조를 정확히 복원합니다. 특히 손글씨 인식(Handwriting Recognition) 성능은 기존 오픈소스 OCR 모델 중 가장 높은 수준으로 평가됩니다.
-
복잡한 레이아웃 처리: 신문이나 논문처럼 다단(Column) 구조, 머리말/꼬리말, 주석 등을 가진 문서도 정확히 분석합니다. Chandra는 페이지 전체의 시각적 관계를 모델링하여, **레이아웃 보존율(layout fidelity)**이 매우 높습니다.
-
이미지·다이어그램 추출 및 캡션 생성: 문서 내의 도표, 그래프, 이미지, 차트를 인식하여 별도로 추출하고, 각각의 이미지에 대해 **자동 캡션(설명문)**을 생성합니다. 이는 데이터 보고서, 연구 논문, 과학 문서 등에서 유용합니다.
-
수식(Math) 및 표(Table) 인식: Chandra는 수학식의 시각적 구조를 이해하고, LaTeX 형태로 변환할 수 있습니다. 또한 표(Table) 데이터의 셀, 행, 열 구성을 정확히 파악하여 Markdown/HTML로 변환합니다.
-
멀티랭귀지 지원: Surya 모델의 언어 커버리지를 계승하여 40개 이상의 언어를 지원합니다. 영어, 프랑스어, 일본어, 한국어 등 주요 언어 외에도 다양한 문자를 인식할 수 있습니다.
Chandra OCR 사용 방법
Chandra OCR 설치는 매우 간단합니다. 다음과 같은 pip install 명령어로 바로 설치할 수 있습니다:
pip install chandra-ocr
이후, CLI 도구를 사용하거나, Python 코드에서 Chandra OCR 모델을 불러와 사용할 수 있습니다.
먼저 Chandra OCR을 CLI로 실행 및 사용하는 방법은 다음과 같습니다:
# vLLM 서버 기반 추론
chandra_vllm
chandra input.pdf ./output
# Hugging Face 로컬 모델
chandra input.pdf ./output --method hf
위와 같이 실행 시, 출력은 다음과 같은 구조로 저장됩니다.
./output/
└─ input/
├─ input.md
├─ input.html
├─ input_metadata.json
└─ images/
기존의 Python 코드에 포함하는 예시는 다음과 같습니다:
from chandra.model import InferenceManager
from chandra.model.schema import BatchInputItem
manager = InferenceManager(method="vllm")
batch = [BatchInputItem(image=PIL_IMAGE, prompt_type="ocr_layout")]
result = manager.generate(batch)
print(result.markdown)
또는, 다음과 같이 Hugging Face Transformers 라이브러리로부터 Chandra OCR 모델을 직접 호출하여 사용할 수도 있습니다:
from transformers import AutoModel, AutoProcessor
from chandra.model.hf import generate_hf
from chandra.model.schema import BatchInputItem
from chandra.output import parse_markdown
model = AutoModel.from_pretrained("datalab-to/chandra").cuda()
model.processor = AutoProcessor.from_pretrained("datalab-to/chandra")
batch = [BatchInputItem(image=PIL_IMAGE, prompt_type="ocr_layout")]
result = generate_hf(batch, model)
markdown = parse_markdown(result.raw)
마지막으로, Streamlit 기반의 Web UI도 지원합니다. 단일 페이지 처리를 위한 대화형 데모는 다음과 같이 실행하면 됩니다:
# Streamlit 기반 웹 UI
chandra_app
Chandra OCR의 벤치마크 성능 분석
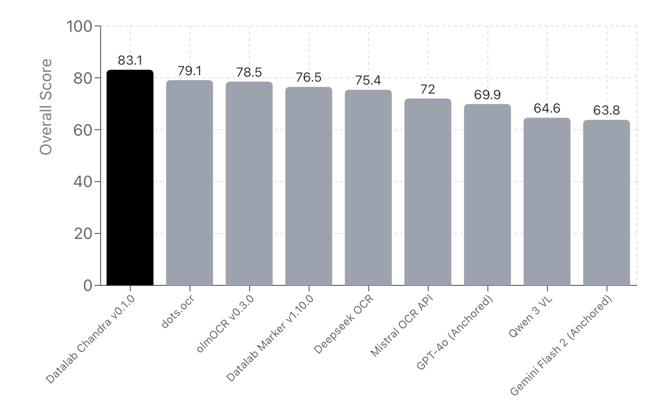
Chandra는 **olmOCR 벤치마크(Allen AI)**를 기준으로 한 평가에서 DeepSeek-OCR을 비롯하여, Marker, GPT-4o, Gemini Flash 2, Qwen 3-VL 등과 같은 경쟁 모델들 대비 더 나은 성능을 보였습니다:
| 모델 | arXiv | 수식 | 표 | 스캔본 | 다단 문서 | 손글씨 | 전체 점수 | 출처 |
|---|---|---|---|---|---|---|---|---|
| Chandra v0.1.0 | 82.2 | 80.3 | 88.0 | 50.4 | 81.2 | 92.3 | 83.1 ± 0.9 | Datalab |
| Marker v1.10.0 | 83.8 | 69.7 | 74.8 | 32.3 | 79.4 | 85.7 | 76.5 ± 1.0 | Datalab |
| DeepSeek OCR | 75.2 | 72.3 | 79.7 | 33.3 | 66.7 | 80.1 | 75.4 ± 1.0 | Datalab |
| olmOCR (Allen AI) | 78.6 | 79.9 | 72.9 | 43.9 | 77.3 | 81.2 | 78.5 ± 1.1 | Allen AI |
| dots.ocr | 82.1 | 64.2 | 88.3 | 40.9 | 82.4 | 81.2 | 79.1 ± 1.0 | dots.ocr repo |
특히 수식, 테이블, 손글씨 인식 부문에서는 오픈소스 모델 중 가장 높은 점수를 기록했습니다.
Chandra OCR의 인식 예시
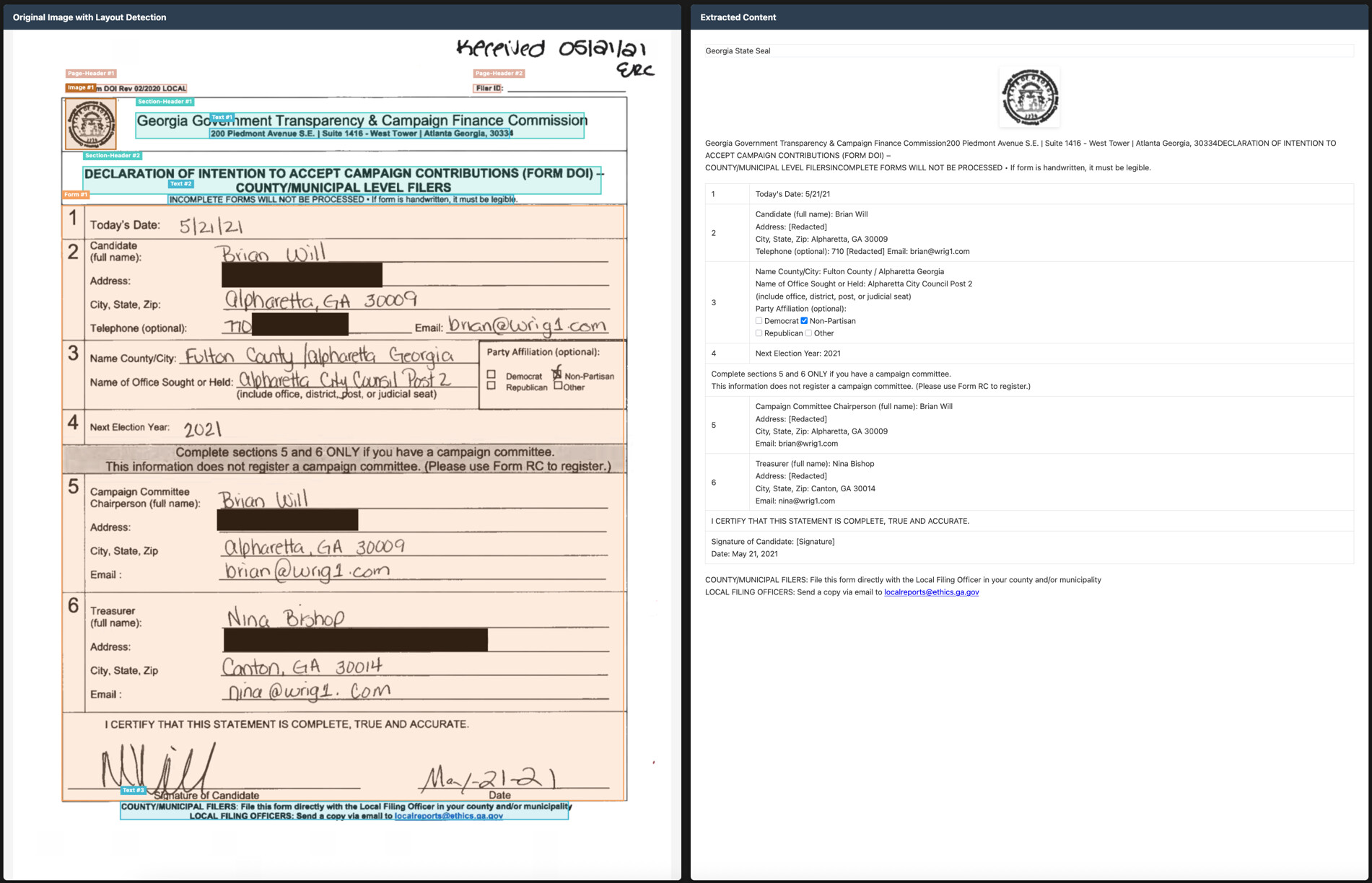
Chandra는 전통적인 OCR 시스템이 어려움을 겪던 복잡한 문서 구조, 손글씨, 수식, 표, 다단 뉴스, 스캔 이미지 등 다양한 형태의 데이터를 정교하게 처리할 수 있습니다. 다음은 GitHub 저장소(datalab-to/chandra)에 공개된 실제 예제 목록과 각 유형별 설명입니다.
| 유형(Type) | 예시 문서 이름(Name) | 미리보기(View) | 설명 |
|---|---|---|---|
| Tables | Water Damage Form | 보기 | 보험 청구서 형태의 양식으로, 여러 열(column)과 행(row)이 혼합된 표를 포함. Chandra는 표 구조와 셀 관계를 Markdown 형태로 정확히 복원함. |
| Tables | 10K Filing | 보기 | 기업의 SEC 보고서 일부로, 복잡한 재무 데이터 표가 포함된 문서. Chandra는 숫자 서식과 헤더/푸터를 유지하며 HTML 테이블로 출력 가능. |
| Forms | Handwritten Form | 보기 | 사람이 손으로 작성한 입력란이 포함된 문서. 체크박스, 서명란 등까지 정확히 인식해 JSON 구조로 변환. |
| Forms | Lease Agreement | 보기 | 임대차 계약서 예시. 각 조항 번호, 문단 구분, 입력 필드 등이 유지된 형태로 Markdown 출력 가능. |
| Handwriting | Doctor Note | 보기 | 의사 처방전처럼 손글씨가 많은 문서. 일반 OCR이 어려워하는 부분도 안정적으로 인식하며, 문맥별 줄 단위 재구성 수행. |
| Handwriting | Math Homework | 보기 | 수학 숙제 이미지로, 손글씨와 수식이 함께 존재. 수학식과 필기 텍스트를 분리하여 정확히 추출 가능. |
| Books | Geography Textbook | 보기 | 교과서 페이지 예시. 다단 텍스트, 이미지 캡션, 인용문, 그래픽 요소가 혼재되어 있으나 구조를 유지한 HTML 변환이 가능. |
| Books | Exercise Problems | 보기 | 문제집 페이지 예시. 번호 매김, 문항 구분, 표 형식의 문제 구성 등을 정확히 식별하여 Markdown 재현. |
| Math | Attention Diagram | 보기 | AI 논문 내 “Attention Mechanism” 다이어그램을 포함한 페이지. 다이어그램과 수식의 관계를 인식해 이미지+캡션 구조로 출력. |
| Math | Worksheet | 보기 | 수학 연습지 문서. 수식, 답안란, 텍스트 주석을 구분하여 포맷화된 HTML 생성. |
| Math | EGA Page | 보기 | 대수기하학 교재(EGA) 페이지. LaTeX 표현식으로 수학식 복원이 가능함. |
| Newspapers | New York Times | 보기 | 신문 기사 페이지. 다단 구성과 이미지, 제목, 캡션을 인식하여 구조화된 결과 제공. |
| Newspapers | LA Times | 보기 | 신문 지면 복원 예시. 문단 순서, 섹션 제목, 광고 영역을 구분하여 HTML 구조로 재현. |
| Other | Transcript | 보기 | 대학 성적표 문서. 표 형식의 과목/점수 정보 및 메타데이터를 포함하며 JSON 출력 지원. |
| Other | Flowchart | 보기 | 흐름도(Flowchart) 포함 문서. 도형과 화살표 구조를 인식하고, 각 노드 관계를 구조화된 데이터로 변환. |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 Chandra OCR의 개발사 Datalab 홈페이지
Chandra OCR의 개발사 Datalab 홈페이지
 Chandra OCR 프로젝트 GitHub 저장소
Chandra OCR 프로젝트 GitHub 저장소
https://github.com/datalab-to/chandra
 Chandra OCR 모델 다운로드
Chandra OCR 모델 다운로드
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()