
CharGraph 소개
CharGraph는 Gemini 2.0 Flash Exp 모델을 활용하여 책의 전체 내용을 LLM의 컨텍스트 윈도우에 입력한 후, 어떠한 등장인물이 존재하는지와 등장인물들 간의 관계, 그리고 외형적 특징 등을 추출하는 실험적인 프로젝트입니다. 이렇게 추출한 데이터는 캐릭터 이미지를 생성하는데 활용할 수도 있으며, 특정 작품의 캐릭터 관계도를 탐색하는데 유용합니다.
CharGraph는 특히 Gemini 2.0 Flash 모델을 사용하였는데, 이는 함수 호출과 구조화된 출력(Structured Output)을 지원할 뿐만 아니라 컨텍스트 윈도우의 크기가 1M 토큰까지 지원하여 레미제라블과 같은 대작도 입력이 가능하기 때문입니다. 또한, Google AI Studio에서 API 키를 발급하여 무료로 사용 가능한 것도 이유입니다.
현재 Project Gutenberg에 공개된 《톰 소여의 모험》, 《피터 팬》, 《백치》, 《안나 카레니나》, 《레미제라블》 등의 고전 문학을 분석했으며, 분석 결과는 여기에서 확인할 수 있습니다. 분석한 도서들의 전체 길이(Token)는 다음과 같습니다:
| Book Title | Author | Tokens |
|---|---|---|
| The Adventures of Tom Sawyer | Mark Twain | 102,181 |
| Peter Pan | J. M. Barrie | 65,530 |
| The Idiot | Fyodor Dostoyevsky | 339,041 |
| Anna Karenina | Leo Tolstoy | 486,537 |
| Les Misérables | Victor Hugo | 783,912 |
기존의 NLP 기반 접근법은 책의 문장을 개별적으로 분석해 등장인물을 추출하는 방식이지만, CharGraph는 LLM을 활용해 한 번에 전체 컨텍스트를 이해하고 관계까지 분석하는 것이 차별점입니다.
CharGraph 주요 기능
-
캐릭터 및 관계 추출:
chargraph.py스크립트를 실행하면 등장인물과 관계를 JSON 파일로 저장합니다.- Gemini API 또는 OpenRouter API를 지원합니다.
-
캐릭터 이미지 생성 (선택 사항):
- 추출된 JSON 데이터를 활용하여 Stable Diffusion 등의 모델을 이용해 등장인물의 초상화를 생성할 수 있습니다.
- 실제 구현 예시는 Google Colab에서 Stable Diffusion 3.5를 이용한
Peter Pan과Tom Sawyer이미지 생성 예제입니다. - 프롬프트에서 캐릭터나 책 제목을 제외하여 LLM의 사전 학습된 특정 이미지 편향을 방지합니다.
-
HTML/JS를 활용한 시각화:
- D3.js 기반 인터페이스를 사용해 추출된 데이터를 네트워크 그래프로 표현합니다.
- 새로운 책을 추가하고 시각화하는 방법은 문서를 참고하세요.
한계점 및 개선 가능성
- 출력 한계: LLM의 최대 출력 토큰(8K)이 한계로 작용하며, 특히 등장인물이 많은 책에서는 일부 데이터가 누락될 수 있음
- 반복 개선: 기존 JSON 데이터를 입력하여 보완하는 반복적인 접근법이 유용함
- 추가 실험 가능성: 법률 문서(선서 진술서, 기소장)나 영화/드라마 대본에도 적용 가능
 CharGraph GitHub 저장소
CharGraph GitHub 저장소
https://github.com/suvakov/chargraph
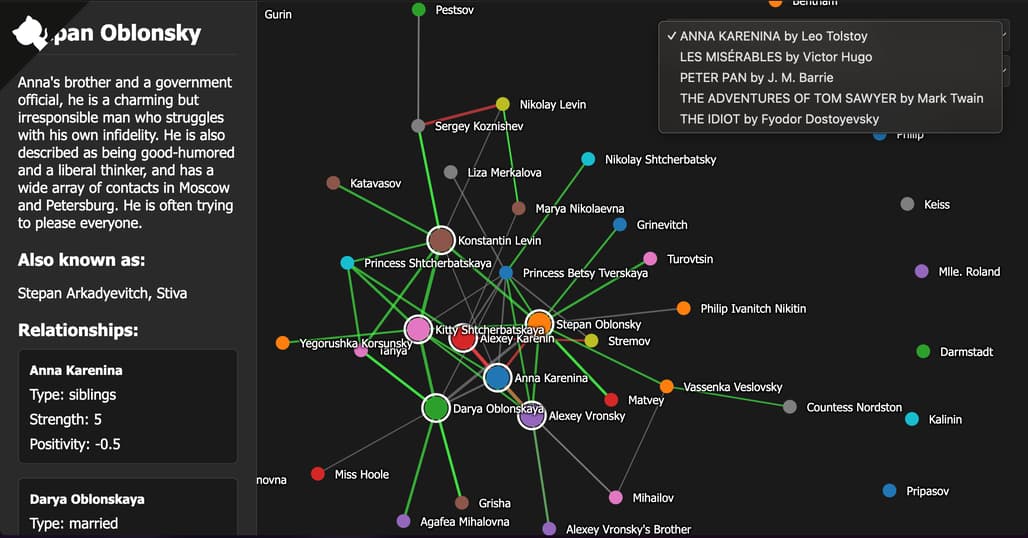
 CharGraph로 분석한 결과 예시
CharGraph로 분석한 결과 예시
 Project Gutenberg 홈페이지
Project Gutenberg 홈페이지
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()