ChartQA-MLLM 소개
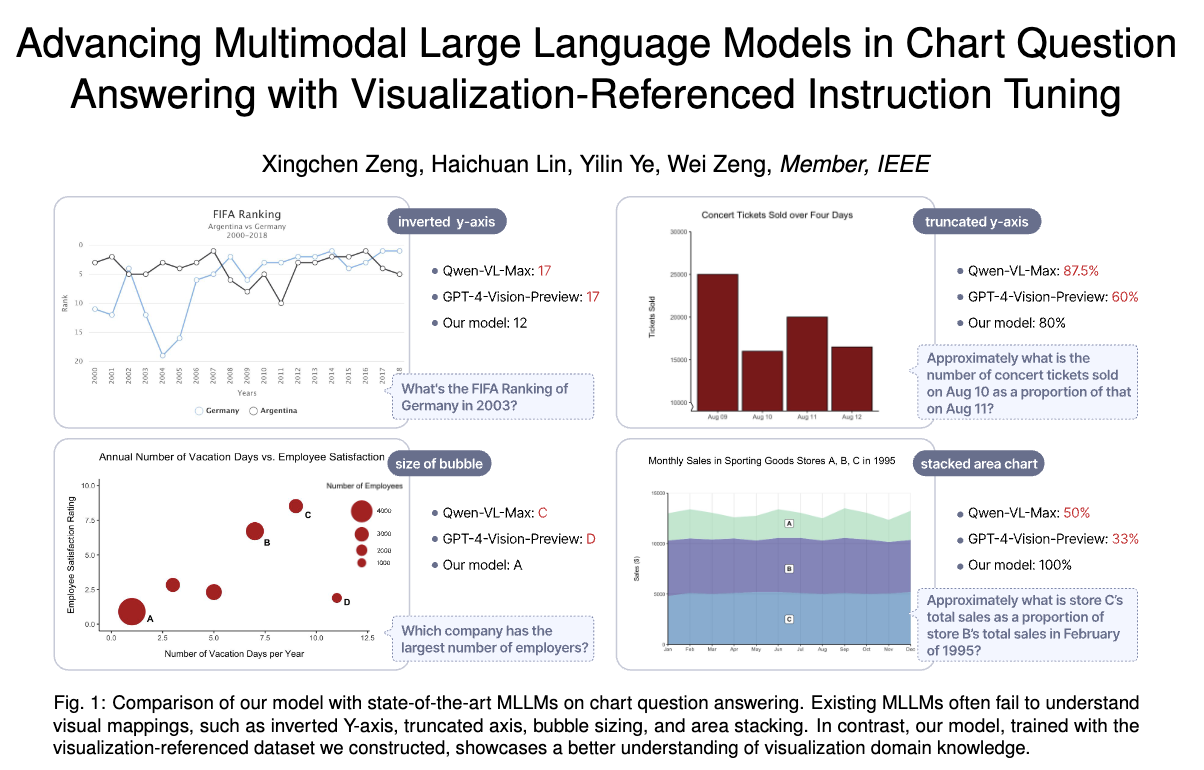
데이터 시각화는 복잡한 데이터 집합을 보다 쉽게 이해할 수 있도록 도와주는 강력한 도구입니다. 차트는 이러한 시각화의 대표적인 형태로, 숫자나 텍스트만으로는 파악하기 어려운 정보를 명확하게 표현합니다. 그러나 차트를 해석하고 관련 질문에 답변하는 것은 인간에게도 종종 까다로운 작업일 수 있습니다. 이러한 문제를 해결하기 위해 Zeng Xingchen과 연구팀은 ChartQA라는 다중 모달 언어 모델을 개발하였습니다. ChartQA는 차트 이미지를 분석하고 이에 대한 자연어 질문을 처리하여 정확한 답변을 제공합니다. 이는 교육, 비즈니스 인텔리전스, 리서치 등 여러 분야에서 매우 유용하게 활용될 수 있는 기술입니다.
ChartQA는 다양한 차트 유형을 처리할 수 있는 점에서 특히 두드러집니다. 기존의 모델은 주로 특정 유형의 차트만 처리하거나 제한된 기능만을 제공하는 경우가 많았는데요. 반면, ChartQA는 범용적인 접근 방식을 채택하여 바 차트, 라인 차트, 파이 차트 등 다양한 차트를 인식하고 해석할 수 있습니다. 이러한 점은 복잡한 시각적 데이터를 다루어야 하는 실제 응용 분야에서 큰 장점으로 작용합니다.
또한, ChartQA는 오픈AI의 GPT 시리즈와 같은 기존의 언어 모델과 비교할 때, 이미지 이해 능력이 크게 향상되었습니다. 특히 차트 내에서 텍스트와 시각적 요소를 함께 고려하여 보다 정확한 컨텍스트 이해를 가능하게 합니다. 이는 모델의 정밀도와 활용 가능성을 한층 높이는 요소로 작용합니다.
ChartQA-MLLM 프로젝트에 대한 자세한 내용을 다룬 연구 논문은 "Advancing Multimodal Large Language Models in Chart Question Answering with Visualization-Referenced Instruction Tuning"에서 확인할 수 있습니다. 이 논문은 프로젝트의 이론적 배경, 실험 설정, 결과 및 분석을 포함하여 차트 질문 응답에서 멀티모달 대형 언어 모델의 사용을 탐구합니다. 연구에서는 차트를 효과적으로 이해하고 분석하는 데 필요한 고급 기법을 설명하며, 이를 통해 차트의 시각적 요소와 텍스트 요소를 결합한 접근 방식을 제안합니다.
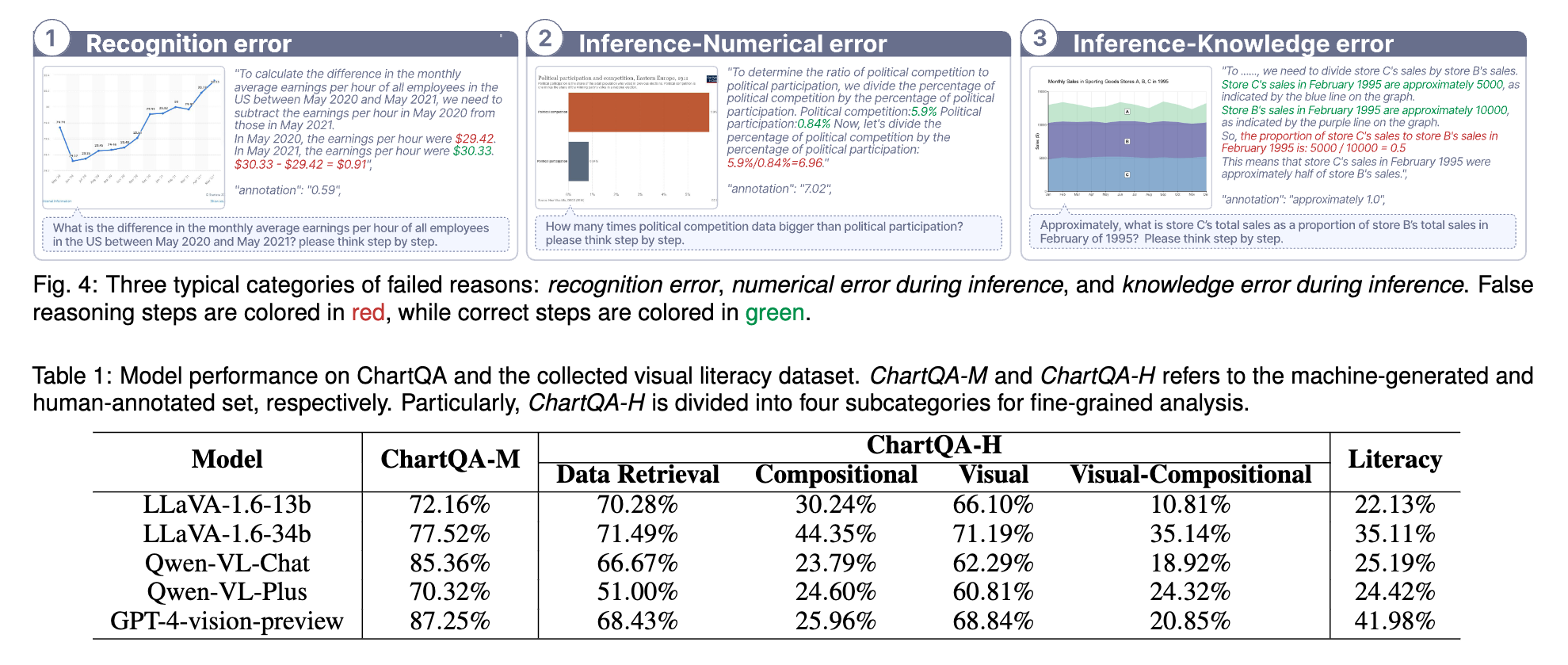
논문은 시각화 참조 명령어 튜닝 기법의 사용을 중점적으로 다루며, 이 기법은 모델이 차트의 시각적 정보를 더 잘 이해할 수 있도록 돕습니다. 연구자들은 이 기법을 통해 모델의 성능이 향상되는 것을 실험적으로 증명하였으며, 다양한 차트 유형과 복잡한 데이터 구조를 처리하는 데 효과적임을 보여주었습니다. 이 논문은 차트 데이터의 구조적 특성과 시각적 요소의 조화를 통해 모델의 학습 과정을 최적화하는 방법을 제시합니다.
또한, 논문에서는 ChartQA-MLLM의 성능을 평가하기 위한 다양한 실험 결과를 제공합니다. 실험에서는 다양한 데이터셋과 차트 유형을 사용하여 모델의 정확성과 효율성을 검증하였으며, 결과적으로 기존의 접근 방식보다 더 높은 성능을 달성하였음을 보여줍니다.
주요 특징
ChartQA의 핵심 기능은 다음과 같습니다:
-
다중 모달 입력 처리: ChartQA는 차트 이미지를 입력으로 받아들이며, 이를 자연어 질문과 결합하여 통합적으로 처리합니다.
-
차트 유형 인식: 다양한 차트 유형을 인식하여 각 유형에 맞는 해석 방법을 적용합니다.
-
정확한 질의응답: 차트에서 추출한 데이터를 기반으로 질문에 대한 정확하고 신뢰성 있는 답변을 제공합니다.
-
데이터 추론 능력: 단순히 차트에 있는 정보를 제공하는 데 그치지 않고, 이를 기반으로 추가적인 추론을 수행합니다.
-
사용자 친화적 인터페이스: 개발자와 사용자가 쉽게 접근하고 활용할 수 있는 인터페이스를 제공합니다.
 ChartQA-MLLM GitHub 저장소
ChartQA-MLLM GitHub 저장소
https://github.com/zengxingchen/chartqa-mllm
 ChartQA-MLLM 모델 가중치 다운로드
ChartQA-MLLM 모델 가중치 다운로드
 논문 읽기: Advancing Multimodal Large Language Models in Chart Question Answering with Visualization-Referenced Instruction Tuning
논문 읽기: Advancing Multimodal Large Language Models in Chart Question Answering with Visualization-Referenced Instruction Tuning
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()