- 이 글은 GPT 모델로 자동 요약한 설명으로, 잘못된 내용이 있을 수 있으니 원문을 참고해주세요!

- 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다!

소개
이 논문은 다중 모달 요약에 대한 새로운 접근법을 제시합니다. 다중 모달 요약은 텍스트와 이미지와 같은 여러 모달리티를 사용하여 요약을 생성하는 작업입니다. 이 작업은 텍스트만을 사용하는 전통적인 요약 작업보다 더 복잡하며, 이미지가 요약에 어떻게 기여하는지 이해하는 것이 중요합니다.
요약
이 논문은 Coarse-to-Fine Contribution Network (CFSum)라는 새로운 다중 모달 요약 모델을 제안합니다. 이 모델은 이미지가 텍스트 요약에 어떻게 기여하는지를 평가하고, 이를 통해 더 효과적인 요약을 생성합니다.
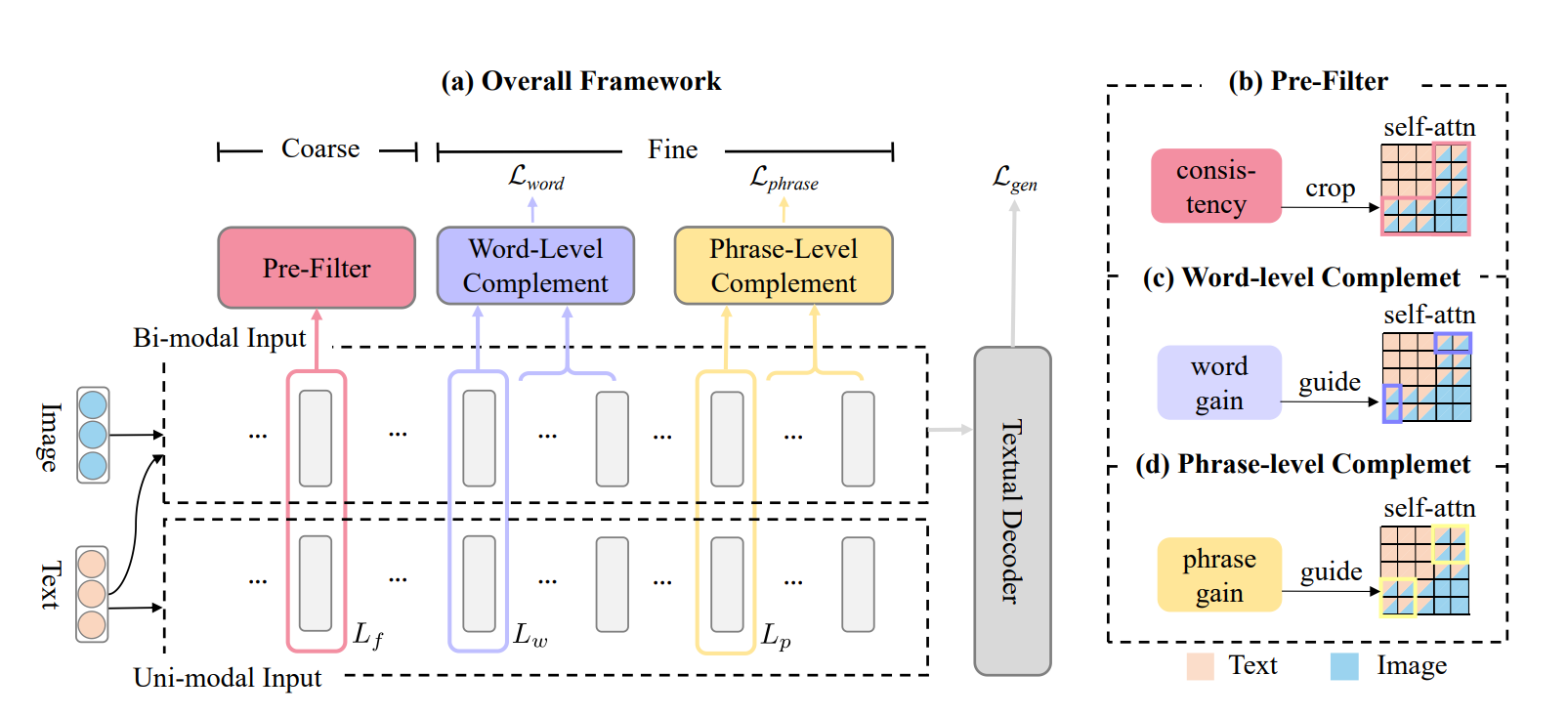
CFSum은 세 가지 주요 모듈로 구성되어 있습니다:
- Pre-filter 모듈: 이 모듈은 텍스트와 일치하지 않는 이미지를 걸러냅니다. 이를 통해 모델이 오해를 일으키는 이미지에 의해 방해받는 것을 방지합니다.
- Word-level complement 모듈: 이 모듈은 이미지가 요약에 어떻게 기여하는지를 단어 수준에서 모델링합니다. 이 정보는 후속 attention 메커니즘을 안내하는 데 사용됩니다.
- Phrase-level complement 모듈: 이 모듈은 더 높은 계층에서 구문 수준의 이미지 기여를 모델링합니다.
이 논문은 또한 CFSum이 다른 기준 모델에 비해 더 나은 성능을 보이는 것을 실험적으로 보여줍니다. 특히, CFSum은 이미지와 텍스트가 잘 맞지 않는 경우에도 견고함을 유지하면서, 이미지가 요약에 기여하는 방식을 더 잘 이해하고 활용할 수 있습니다.
GitHub 저장소
참고 논문
A context knowledge map guided coarse-to-fine action recognition: 이 논문은 대략적-세밀한 접근법을 사용하여 액션 인식을 수행하는 방법에 대해 설명하고 있습니다. 이는 원본 논문에서 사용된 접근법과 유사한 개념을 다루고 있습니다.
Coarse-to-fine reasoning for visual question answering: 이 논문은 시각적 질문 응답을 위한 대략적-세밀한 추론에 대해 설명하고 있습니다. 이는 원본 논문에서 다루는 다중 모달 요약과 관련된 주제입니다.
https://openaccess.thecvf.com/content/CVPR2022W/MULA/html/Nguyen_Coarse-To-Fine_Reasoning_for_Visual_Question_Answering_CVPRW_2022_paper.html
Rfnet: Unsupervised network for mutually reinforcing multi-modal image registration and fusion: 이 논문은 상호 강화하는 다중 모달 이미지 등록 및 융합을 위한 비지도 네트워크에 대해 설명하고 있습니다. 이는 원본 논문에서 다루는 다중 모달 요약과 관련된 주제입니다.