
Command A+ 소개
엔터프라이즈 에이전트 시대, "충분히 강하면서 직접 돌릴 수 있는 모델"에 대한 갈증
엔터프라이즈에서 대규모 언어 모델(LLM)을 도입할 때 가장 자주 부딪히는 벽은 모델의 절대 성능이 아니라 운영의 현실성입니다. 데이터를 외부 API로 내보낼 수 없는 금융, 통신, 공공 도메인일수록 "이 모델을 우리 데이터센터 안에서 돌릴 수 있는가", "GPU 몇 장이면 되는가", "한국어/일본어/아랍어도 같은 품질이 나오는가" 같은 질문이 모델 점수표 한 줄보다 무겁게 다가옵니다.
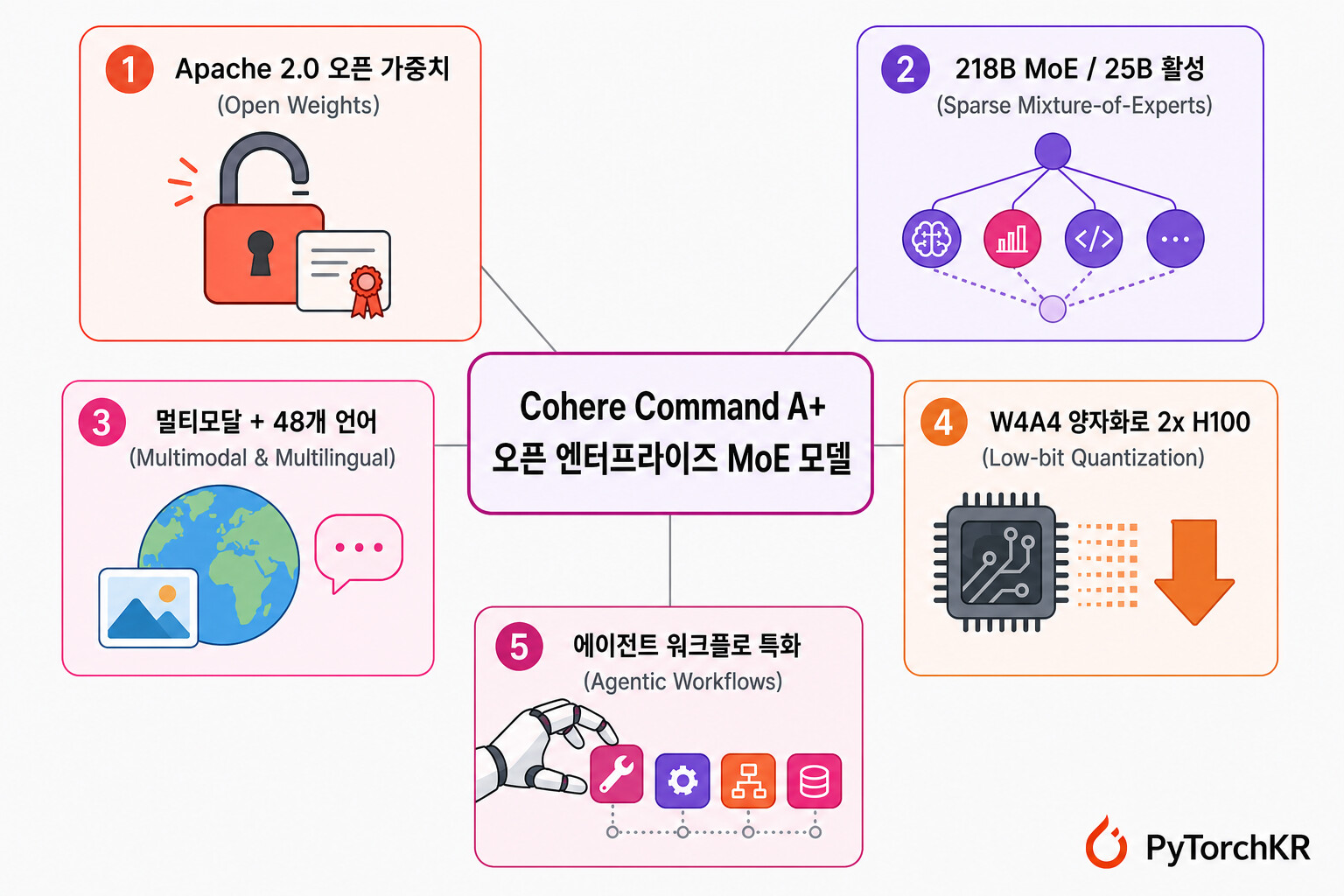
Cohere가 최근 공개한 Command A+(command-a-plus-05-2026)는 바로 이 지점을 정조준한 모델로, 3가지 주요 특징을 갖습니다: 첫째, Cohere가 처음으로 자사 최강 모델을 Apache 2.0 라이선스로 풀었다는 점. 둘째, 218\text{B} 총 파라미터 / 25\text{B} 활성 파라미터의 희소 MoE(Sparse Mixture-of-Experts) 구조로, 같은 품질을 종전보다 훨씬 작은 하드웨어 풋프린트에 욱여넣었다는 점. 셋째, 멀티모달과 48 개 언어를 한 모델에 통합하여 종전 Command A 패밀리(Command A, Command A Reasoning, Command A Vision, Command A Translate)를 하나의 모델로 합쳤다는 점입니다.
기존 접근법들과의 대비를 보면 의미가 더 분명해집니다. 폐쇄형 프런티어 모델(GPT-4 계열, Claude Sonnet 계열)은 성능은 우수하지만, "주권 AI(sovereign AI)"를 표방하는 고객사에게는 데이터를 외부로 흘려보내야 한다는 근본적 제약이 있습니다. 한편 기존 오픈 가중치 모델(Llama, Qwen, DeepSeek 계열) 중 엔터프라이즈 에이전트 워크로드를 본격적으로 겨냥한 모델은 의외로 많지 않았고, 멀티모달과 도구 사용을 동시에 만족하면서 W4A4 양자화 시 단일 NVIDIA Blackwell GPU에서 돌아가는 라인업은 더더욱 드물었습니다.
Command A+는 이 두 갈래의 빈틈을 메우려는 시도이며, Cohere가 "Apache 2.0 + 엔터프라이즈급 + 직접 배포 가능"이라는 세 조건을 동시에 만족시킨 첫 모델이라는 점에서 의미가 큽니다. Cohere 공동창업자 Aidan Gomez는 이를 "Cohere의 첫 완전 오픈 Apache 2.0 모델"이라고 강조했고, Hugging Face의 Clement Delangue를 포함한 커뮤니티는 "허용적 라이선스의 배포 가능한 엔터프라이즈급 오픈 모델"이라는 흐름이 한 단계 진전된 사건으로 해석하고 있습니다.
Command A+ 모델 한 줄 요약과 모델 카드
Command A+는 한 줄로 정의하면 "엔터프라이즈 에이전트 워크로드에 특화된 218B/25B 희소 MoE 멀티모달 LLM, Apache 2.0 라이선스로 공개" 입니다. 모델 카드의 핵심 사양을 표로 정리하면 다음과 같습니다:
| 항목 | 값 |
|---|---|
| 모델 ID | command-a-plus-05-2026 |
| 라이선스 | Apache 2.0 |
| 아키텍처 | Sparse Mixture-of-Experts (MoE) |
| 파라미터 | 총 218\text{B} / 활성 25\text{B} (전문가 128 개 중 토큰당 8 개 활성 + 공유 전문가 1 개) |
| 컨텍스트 길이 | 입력 128\text{K} / 최대 생성 64\text{K} |
| 입력 모달리티 | 텍스트, 이미지, 도구 호출 |
| 출력 모달리티 | 텍스트, 사고 흐름(reasoning), 도구 호출 |
| 지원 언어 | 48 개 (한국어 포함) |
| 양자화 | BF16, FP8, W4A4 (NVFP4) |
| 최소 하드웨어 | 1\times NVIDIA B200 @ W4A4 또는 2\times H100 @ W4A4 |
| 지원 프레임워크 | vLLM (\ge 0.21.0 부터 W4A4 지원), Transformers |
여기서 가장 눈에 띄는 숫자는 단연 마지막 두 줄입니다. 200\text{B} 급 모델이 H100 두 장으로 추론된다는 건 종전 dense 100\text{B} 급 모델들의 운영 비용 곡선을 그대로 적용할 수 없다는 뜻이며, 이는 단순한 가중치 공개를 넘어 배포 가능성(deployability) 자체를 자산으로 만들겠다는 Cohere의 선언으로 읽힙니다.
Command A 패밀리의 통합: "다섯 모델의 능력을 한 모델로"
Cohere의 이전 라인업은 역할별로 분기된 Command A 패밀리였습니다. 일반 챗과 도구 호출은 Command A, 복잡한 추론은 Command A Reasoning, 비전 입력은 Command A Vision, 다국어 번역은 Command A Translate가 담당하는 식입니다. 이러한 분기는 각 영역의 품질을 극대화하기 좋은 반면, 운영 측면에서는 모델을 여러 벌 띄워야 한다는 큰 부담을 안깁니다.
Command A+는 이 분기를 하나의 모델로 합치는 것을 명시적 목표로 삼았습니다. 블로그가 제시한 비교 표를 옮겨오면 다음과 같습니다.
| Command A+ | Command A | Command A Reasoning | Command A Vision | Command A Translate | |
|---|---|---|---|---|---|
| 크기 | 218B A25B | 111B | 111B | 112B | 111B |
| Reasoning | ✓ | — | ✓ | — | — |
| Multimodal | ✓ | — | — | ✓ | — |
| Tool use | ✓ | ✓ | ✓ | — | — |
| Multilingual | 48 | 23 | 23 | 6 | 23 |
이 표가 말해주는 핵심은, 종전에는 모달리티/역량별로 모델을 골라 띄워야 했던 워크로드를 이제 Command A+ 한 모델에서 처리할 수 있다는 것입니다. 이는 단순한 "성능 한두 점 개선"보다 실제 배포 환경에서 훨씬 의미 있는 변화입니다. 추론 게이트웨이, 로드 밸런서, 캐시 전략, 평가 파이프라인을 하나의 모델 기준으로 단순화할 수 있기 때문입니다.
성능 지표도 통합이 단순 평균이 아님을 보여줍니다. 에이전트 도구 사용을 다루는 \tau^2\text{-Bench Telecom} 에서 Command A Reasoning의 37\% 에서 85\% 로 점프했고, 에이전트 코딩의 어려운 변형인 Terminal-Bench Hard에서는 3\% 에서 25\% 로 거의 한 자릿수에서 두 자릿수로 올라섰습니다. 즉, 통합 모델인데도 특정 분기 모델보다 해당 분기에서 더 잘하는 결과가 나온 셈입니다.
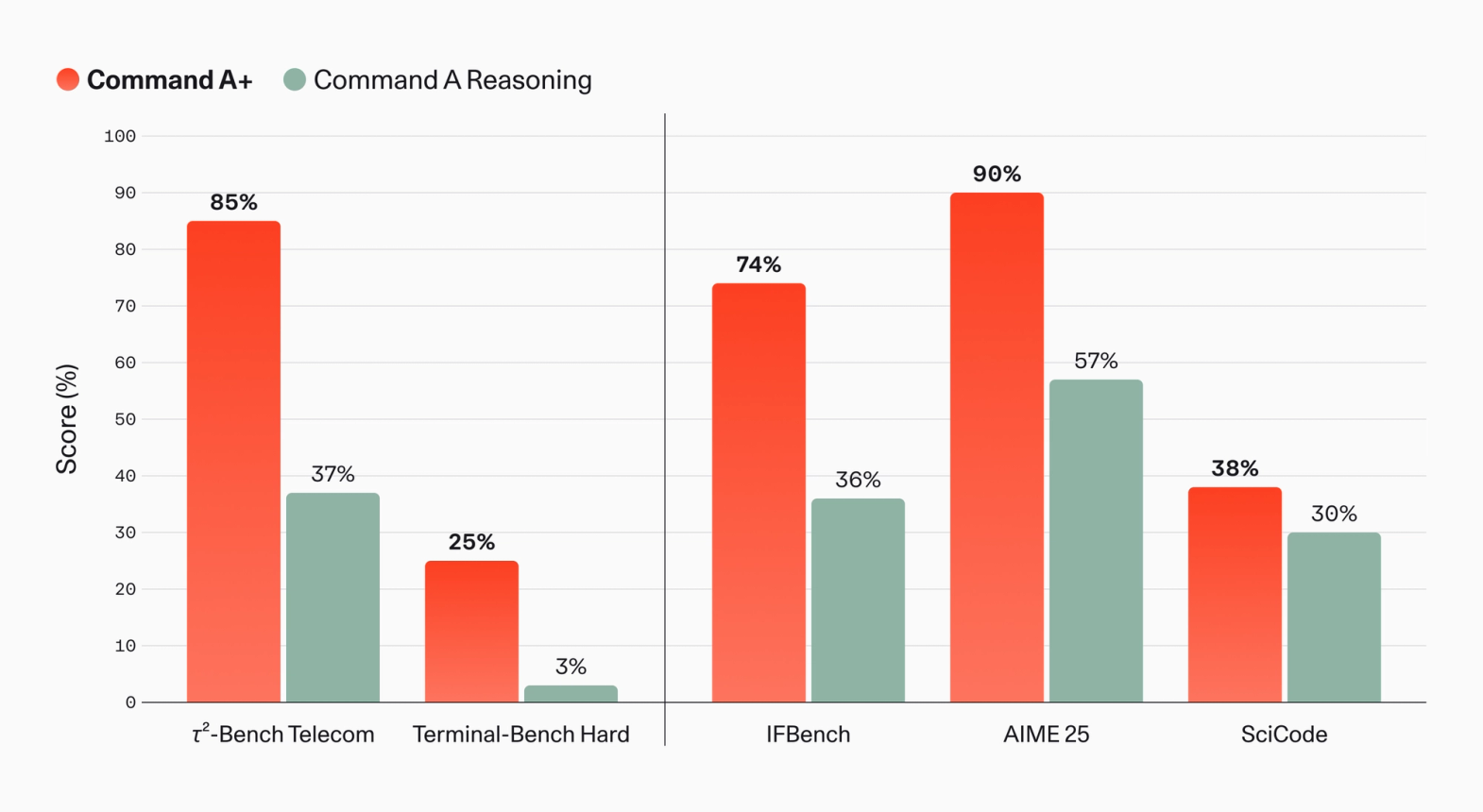
자체 제품인 North 내부 평가에서도 일관된 향상이 보고됩니다. 엔터프라이즈 클라우드 파일시스템을 MCP로 붙여 질문에 답하는 Agentic Question Answering 에서 +20\%, 업로드된 스프레드시트에 대한 데이터 분석에서 +32\%, 이전 세션의 메모리를 참고해 후속 세션 질문에 답하는 Memory Usage Quality 에서 39\% \rightarrow 54\% 의 향상이 보고되었습니다. 모두 LLM-as-a-judge 방식의 자체 평가라는 점은 감안해야 하지만, 같은 평가 척도로 측정한 Command A Reasoning과의 차이라는 점에서 통합 모델의 실용적 이득을 가늠하기에 무리가 없습니다.

아키텍처: 흔치 않은 선택들이 모인 MoE
Command A+의 모델 카드와 Hugging Face 페이지를 읽다 보면 단순한 "또 하나의 MoE"가 아니라는 인상을 받게 됩니다. 커뮤니티에서 Elie Bakouch, Sebastian Raschka, @stochasticchasm 등이 짚어낸 흥미로운 설계 선택을 정리해 보면 다음과 같습니다.
Sparse MoE: 128 전문가 + 공유 전문가 1, top-k=8
Command A+는 디코더 전용 트랜스포머(Transformer)에 희소 MoE 레이어를 얹은 구조입니다. 토큰당 128 개의 전문가 중 8 개가 라우팅되고, 추가로 모든 토큰에 적용되는 공유 전문가(shared expert) 1 개가 존재합니다. 공유 전문가를 크게 쓰는 설계는 일부 토큰이 전문가 선택에서 소외될 때도 안정적인 표현력을 확보하기 위한 장치로 해석됩니다.
라우터는 token-choice 방식이며, 로드 밸런싱은 additive bias 기반으로 균형을 잡고, 라우터 활성화 함수는 일반적인 softmax 대신 top-k 로짓에 대한 정규화된 sigmoid 를 사용합니다. MoE 레이어는 토큰을 드랍하지 않는 dropless 방식으로 학습되어, 학습-추론 간 분포 불일치 문제를 완화합니다.
Sliding-window + Global Attention 의 3:1 인터리브
어텐션 레이어는 Command A에서 처음 도입한 패턴을 그대로 따릅니다. RoPE(Rotational Positional Embeddings)를 쓰는 슬라이딩 윈도우 어텐션과 위치 임베딩 없이 전 토큰을 보는 전역 어텐션을 3:1 비율로 번갈아 배치하는 식입니다. 이는 긴 컨텍스트의 비용을 줄이면서도 일정 주기로 전체 문맥을 다시 통합할 수 있도록 한 절충안으로, 128\text{K} 컨텍스트와 64\text{K} 생성 길이를 단일 노드에서 처리하기 위한 실용적 선택입니다.
커뮤니티가 짚은 "이례적인" 디자인 포인트
커뮤니티 분석에서 자주 언급된 포인트는 네 가지입니다.
- 상대적으로 얕은 깊이: 총 32 레이어 수준의 비교적 얕은 구조. 비슷한 활성 파라미터의 모델들과 비교했을 때 깊이는 줄이고 폭과 전문가 수로 표현력을 확보한 인상입니다.
- Parallel Transformer Block: 어텐션과 FFN(혹은 MoE)을 직렬이 아닌 병렬 분기로 합치는 PaLM 계열의 패턴. 메모리 접근 패턴을 개선해 처리량을 끌어올리는 효과가 있는 것으로 알려져 있습니다.
- LayerNorm 채택: 최근 대부분의 LLM이 RMSNorm으로 갈아탄 흐름과 달리 LayerNorm을 사용했다는 점. 학습 안정성과 양자화 친화성 측면의 의도된 절충으로 해석됩니다.
- 공유 전문가 비중과 활성 전문가 수: 128 중 8 활성에 공유 전문가 1 개를 추가로 항상 적용. 이는 표현력과 일반화에 보탬이 되지만, 모든 토큰이 공유 전문가를 통과하므로 그 가중치 자체를 양자화하는 비용/품질 트레이드오프가 커집니다. 뒤에서 다룰 W4A4 양자화 전략이 "전문가에 한해 4비트, 어텐션 경로는 full precision" 으로 갈라진 이유와 직결됩니다.
이 조합 자체가 새로운 발명은 아니지만, "우리는 어떤 조합으로 MoE를 굳혔는가" 를 공개 가중치와 함께 시연했다는 점에서 Command A+ 릴리스는 단순 모델 드롭 이상의 아키텍처 데이터 포인트 로 받아들여지고 있습니다.
효율: 1\times B200 또는 2\times H100 에서 도는 200\text{B} 급 모델
Cohere가 블로그에서 가장 길게 푼 주제는 성능이 아니라 효율입니다. 이는 "엔터프라이즈에서 실제로 굴릴 수 있는가"가 모델 선택의 1차 기준이 되는 현장의 요구에 정확히 부합합니다.
양자화 방법론: MoE 전문가만 NVFP4 W4A4, 어텐션 경로는 full precision
Reasoning 트레이스가 길어질수록 토큰당 양자화 오차가 누적되어 어려운 벤치마크에서 큰 회귀를 보이는 것이 일반적입니다. Command A+ 는 이를 우회하기 위해 양자화를 선택적으로 적용합니다.
- MoE 전문가에만 NVFP4 W4A4 (4-bit 가중치 + 4-bit 활성화, two-level scaling)를 적용
- Q/K/V/O 프로젝션, KV 캐시, 어텐션 연산은 full precision 유지
- 사후 학습에서 Quantization-Aware Distillation(QAD) 를 사용하여 양자화된 학생 모델이 풀-프리시전 교사 모델의 출력 분포를 모사하도록 학습. 순전파에는 fake quantization 연산자를, 역전파에는 straight-through estimator를 사용
MoE 전문가가 전체 파라미터의 대부분을 차지하므로 여기에만 4-bit를 적용해도 메모리 풋프린트는 단일 B200 예산 안에 들어옵니다. 동시에 짧고 중간 길이의 디코드에서 병목이 되는 expert GEMM이 가속됩니다. 어텐션 경로를 full precision으로 남긴 덕분에, 길어지는 reasoning 트레이스에서 누적 오차로 인한 품질 회귀가 크게 줄어듭니다.
그 결과 Cohere는 BF16/FP8/W4A4 세 가지 양자화를 모두 공개했고, 모델 카드는 "세 양자화 모두 벤치마크 품질과 성능에서 인지할 수 있는 차이는 거의 없다" 라고 명시합니다. 최소 하드웨어 요구는 다음과 같이 정리됩니다.
| Quantization | Blackwell | Hopper |
|---|---|---|
| BF16 (16-bit) | 4\times B200 | 8\times H100 |
| FP8 (8-bit) | 2\times B200 | 4\times H100 |
| W4A4 (4-bit) | 1\times B200 | 2\times H100 |
vLLM 측은 W4A4 가중치에 대해 day-0 지원 을 발표하며 "2\times H100" 에서 돌아가는 점을 따로 강조했습니다. 종전 dense 100\text{B} 급 모델이 차지하던 하드웨어 풋프린트에 200\text{B} 급 MoE가 들어올 수 있게 된 셈입니다.
속도와 지연: MoE 구조 + 추측 디코딩(Speculative Decoding)
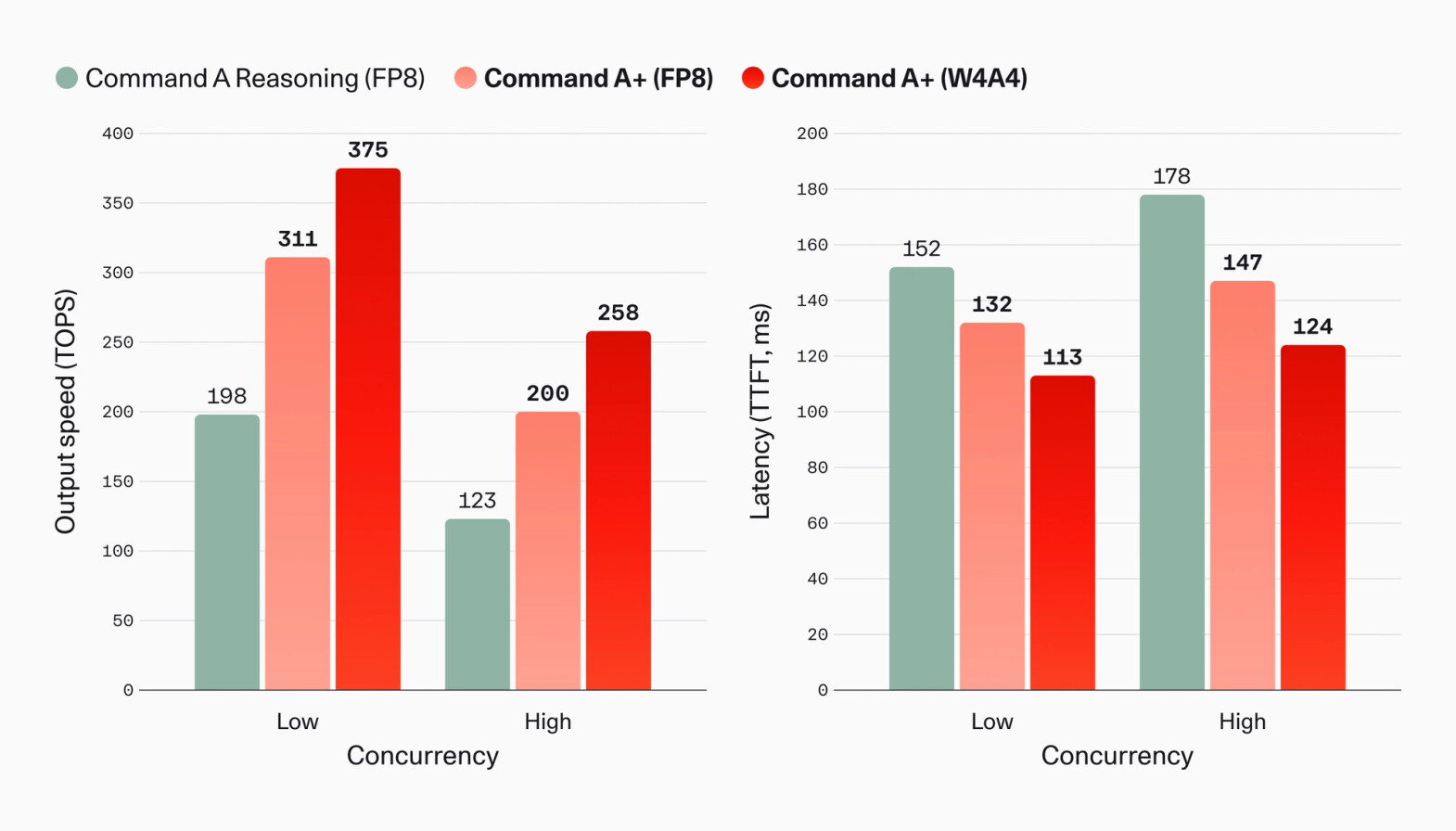
Cohere는 같은 양자화/동시성 조건에서 Command A Reasoning 대비 출력 토큰 처리량(TOPS)이 최대 +63\%, 첫 토큰 도착 시간(TTFT)이 최대 -17\% 개선되었다고 보고합니다. 여기에 W4A4 양자화가 추가로 속도를 +47\%, 지연을 -13\% 가져갑니다.
이와 별개로 Cohere는 MoE 구조에 맞춰 최적화된 추측 디코딩(speculative decoding) 을 적용해 텍스트/멀티모달 입력 모두에서 1.5\sim 1.6\times 추가 추론 가속을 얻었다고 밝혔습니다. 상세 내용은 MoE 모델에서의 speculative decoding 활용 블로그에 별도로 정리되어 있습니다.
새로운 토크나이저: 한국어 -16\%, 일본어 -18\%, 아랍어 -20\% 토큰
Command A+ 는 Cohere의 새 토크나이저를 처음 채택했습니다. 같은 응답을 만드는 데 더 적은 토큰이 들기 때문에 토큰 단가 기반 추론 비용이 그대로 줄어듭니다. 흥미로운 점은 토크나이저 학습에서 자주 과소대표되던 비유럽 언어들에서 이득이 두드러진다는 것으로, 한국어는 토큰 효율이 16\%, 일본어는 18\%, 아랍어는 20\% 개선되었다고 보고됩니다.
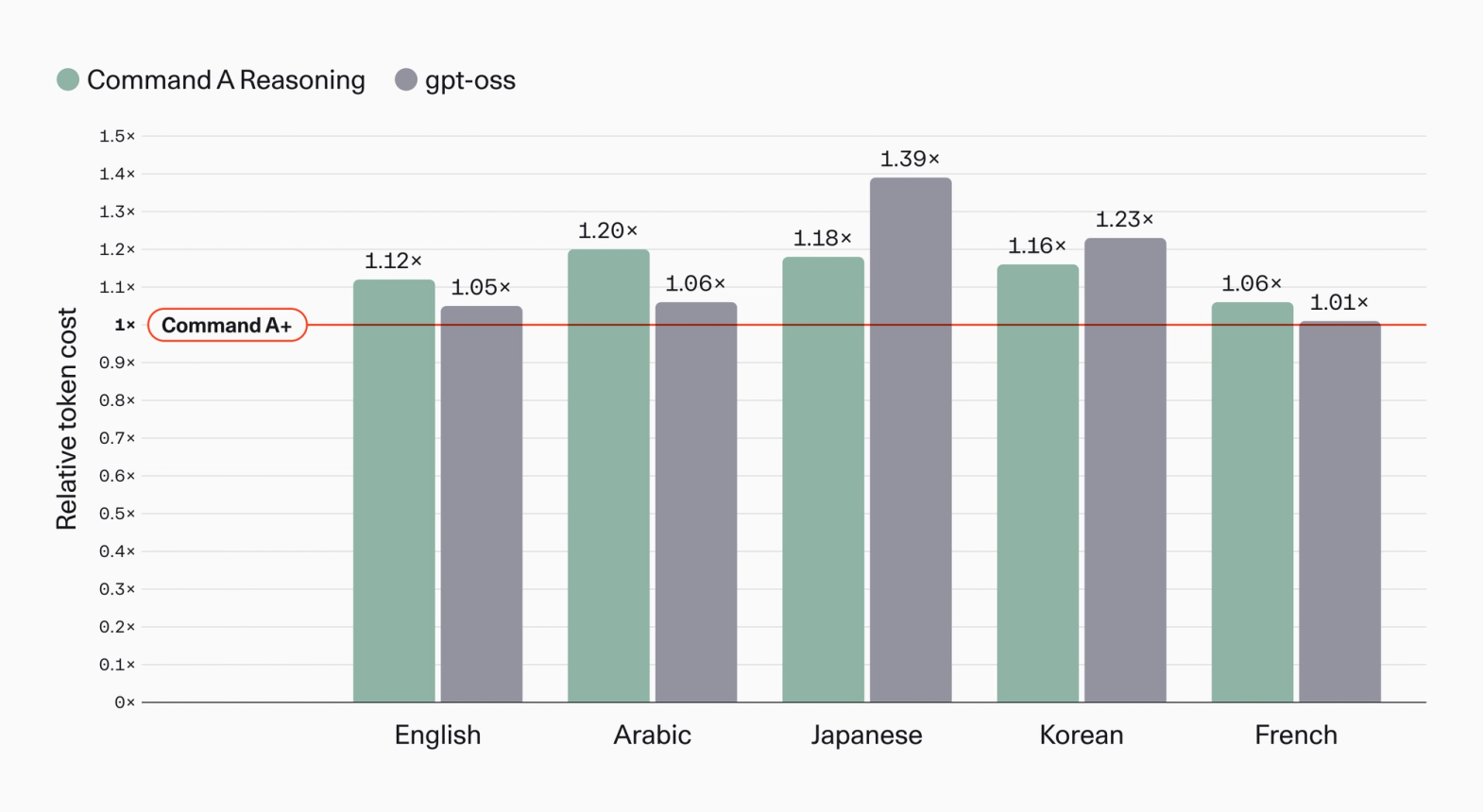
한국어 사용자 입장에서 이 부분은 단순한 다국어 지원 이상의 의미를 가집니다. 같은 응답을 만드는 데 토큰이 줄어들면 응답 시간이 짧아지고 같은 컨텍스트 윈도우에 더 많은 정보를 담을 수 있기 때문입니다.
멀티모달과 다국어: 한 모델로 합쳐도 좋아진 영역들
멀티모달: 첫 번째 Multimodal Reasoning 모델
Command A+ 는 Cohere의 첫 멀티모달 reasoning 모델 입니다. 이전 라인업에서는 Command A Vision 이 비전을 담당했지만 reasoning과 도구 사용은 다른 모델에 분리되어 있었습니다. Command A+ 는 이를 통합하여, MMMU 75.1\%, MMMU Pro 63\%, MathVista 80.6\% (이전 73.5\%), CharXiv reasoning 52.7\% (이전 46.9\%) 등 문서 이해와 시각적 reasoning 전반에서 개선을 보였습니다.

다국어: 23 \rightarrow 48 개 언어와 한국어
지원 언어는 23 개에서 48 개로 두 배 이상 늘었습니다. 한국어를 비롯해 영어, 아랍어, 중국어, 일본어, 인도네시아어, 베트남어, 힌디어, 타밀어 등이 포함됩니다. 자체 번역 벤치마크인 MT-AIME 2025(영어 AIME 2025를 아랍어, 일본어, 한국어로 번역해 평가)와 공개 벤치마크 WMT24++(xCOMETxl 기준)에서 모두 향상이 보고됩니다.
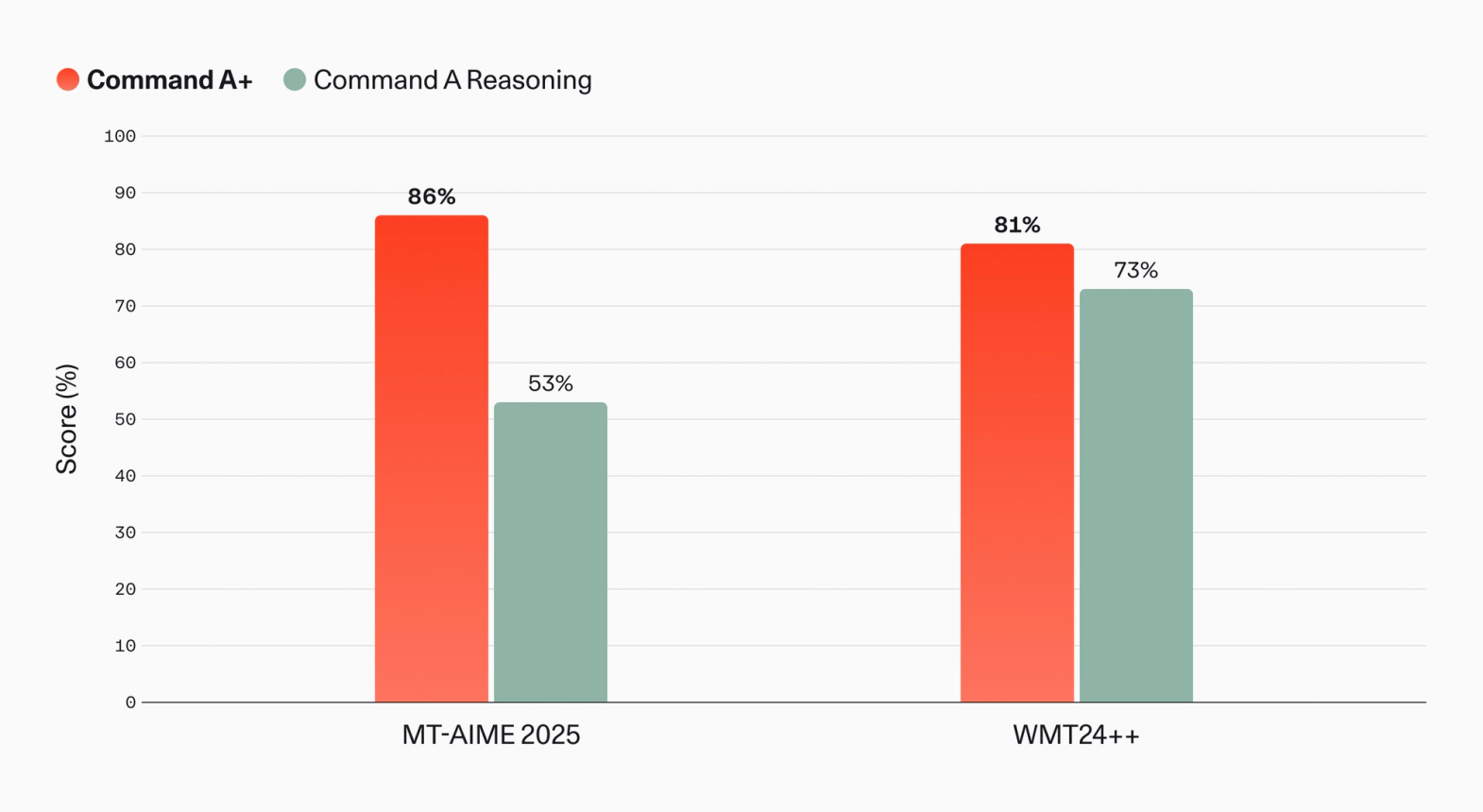
한국어 화자에게 의미 있는 지점은, 통상 영어로만 점수가 측정되는 수학·추론 벤치마크가 한국어/일본어/아랍어로도 평가되었다는 점입니다. MT-AIME 2025 점수 자체보다, "비영어 reasoning을 정면으로 자기 벤치마크에 포함시킨다" 는 운영 시그널이 더 흥미롭습니다.
외부 벤치마크: Artificial Analysis Intelligence Index 37 점
Artificial Analysis 가 발표한 Intelligence Index 에서 Command A+ 는 37 점 을 받아, Claude 4.5 Haiku와 비슷한 구간에 자리잡았습니다. Artificial Analysis 의 평가는 다음과 같이 요약됩니다.
- 강점: 비환각(non-hallucination) 점수가 매우 높음. 즉, 모르는 것을 모른다고 말하는 보정이 잘 되어 있음. 또한 처리량 측면의 속도가 동급 모델 대비 우수.
- 약점: 과학적 reasoning과 코딩에서는 최상위 동급 모델보다 떨어짐.
이는 "agentic + RAG + 다국어 + 멀티모달 + 도구 사용"을 동시에 만족시키는 운영형 모델로서의 위치를 잘 보여줍니다. 즉, Command A+ 는 "가장 어려운 코드/과학 문제를 풀어내는 최강 두뇌" 가 아니라, "엔터프라이즈 일반 워크로드를 안정적이고 빠르게 처리하는 만능 일꾼" 으로 설계되었다는 해석이 자연스럽습니다.
도구 사용과 인용(Citation): 에이전트 워크로드에 맞춘 출력 포맷
Command A+ 는 도구 호출에 특화된 학습을 받았고, Transformers의 chat templates 를 통해 함수 호출을 자연스럽게 사용할 수 있습니다. 도구 정의는 JSON 스키마로 전달되고, 모델은 사고 흐름(thinking) 을 <|START_THINKING|> 와 <|END_THINKING|> 사이에 생성한 뒤 tool_calls 를 반환합니다.
흥미로운 점은 인용 모드(citation mode) 입니다. enable_citations=True 옵션을 주면 응답 내 텍스트 조각(span)을 도구 결과에 직접 묶어 출력합니다. 예를 들어 "2023년 9월 29일의 총 매출은 <co>10000</co: 0:[0]> 이었고, 판매 수량은 <co>250.</co: 0:[0]> 이었습니다" 와 같이 표기되며, 0:[0] 은 "tool_call_id 0 의 결과 인덱스 0" 을 가리킵니다. 여러 도구 결과가 한 span을 지지하면 0:[1,2],1:[0] 처럼 합쳐 표기됩니다.
엔터프라이즈 RAG/에이전트 워크플로에서 "이 문장은 어느 검색 결과/도구 결과에서 왔는가" 를 추적하는 일이 점점 중요해지는 흐름을 감안하면, 이런 grounding span을 모델 출력 포맷으로 끌어올린 결정은 단순한 친절을 넘어 운영 가능성을 위한 설계로 읽힙니다.
설치 및 사용 방법
W4A4 가중치 기준의 가장 짧은 사용 예시는 다음과 같습니다.
Transformers
# transformers 는 모델 지원이 머지된 소스 빌드 사용 권장
pip install git+https://github.com/huggingface/transformers
from transformers import AutoTokenizer, AutoModelForImageTextToText
model_id = "CohereLabs/command-a-plus-05-2026-w4a4"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForImageTextToText.from_pretrained(model_id)
messages = [{"role": "user", "content": "What has keys but can't open locks?"}]
input_ids = tokenizer.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True, return_tensors="pt",
)
gen_tokens = model.generate(
input_ids, max_new_tokens=4096, do_sample=True, temperature=0.6, top_p=0.95,
)
print(tokenizer.decode(gen_tokens[0]))
응답은 <|START_THINKING|>...<|END_THINKING|> 블록과 최종 답변으로 분리되어 나옵니다.
vLLM (W4A4 서빙)
W4A4 가중치는 vllm>=0.21.0 와 Cohere의 cohere_melody 라이브러리를 함께 사용합니다.
uv pip install "vllm>=0.21.0" transformers "cohere_melody>=0.9.0"
B200 1장 기준 서빙 예시:
vllm serve CohereLabs/command-a-plus-05-2026-w4a4 \
-tp 1 \
--tool-call-parser cohere_command4 \
--reasoning-parser cohere_command4 \
--enable-auto-tool-choice
샘플링 파라미터는 temperature=0.9, top_p=0.95, repetition_penalty=1.04 가 권장됩니다.
마치며: "오픈 + 운영 가능 + 다국어" 의 새로운 기준선
Command A+ 는 단일 벤치마크에서 새로운 SOTA를 갈아치우는 종류의 모델은 아닙니다. Artificial Analysis 평가가 정확히 그 점을 짚어줍니다. 그러나 "엔터프라이즈가 실제로 굴릴 수 있는 오픈 가중치 모델" 이라는 좁고 실용적인 기준에서 보면, 이번 릴리스는 몇 개의 못박이 같은 의미가 있습니다.
-
라이선스: Apache 2.0 으로 풀린 Cohere의 첫 자사 최강 모델. 상업적 사용/파인튜닝/재배포의 자유도가 큰 폭으로 넓어집니다.
-
하드웨어: W4A4 양자화에서 단일 B200 또는 2\times H100 으로 서빙 가능. 200\text{B} 급 MoE가 종전 dense 100\text{B} 의 운영 풋프린트로 들어옴.
-
통합: reasoning + multimodal + multilingual + tool use + citation 을 한 모델로. 모델 분기를 운영 파이프라인에서 지워낼 수 있음.
-
다국어 토크나이저: 한국어 포함 비유럽 언어에서 토큰 수 자체가 줄어 비용/지연이 동시에 개선.
-
아키텍처 시그널: 공유 전문가, parallel transformer block, sliding/global 3:1 인터리브, LayerNorm 같은 흔치 않은 설계 선택을 묶어 공개 가중치로 시연.
한국어를 중심으로 쓰는 사용자들에게는, 같은 응답에 들어가는 토큰 수가 줄어드는 토크나이저 변경과 한국어가 자체 평가 항목에 포함되었다는 사실 자체가 실용적인 신호로 다가옵니다. "오픈 가중치인데 한국어가 진지하게 평가된 모델" 의 선택지가 한 칸 더 늘어났다는 점에서, 한국어 RAG/에이전트 시스템 구축자들에게도 다음 PoC의 후보로 진지하게 검토할 가치가 있습니다.
 Introducing Command A+ (Cohere 공식 블로그)
Introducing Command A+ (Cohere 공식 블로그)
 Command A+ W4A4 (Hugging Face)
Command A+ W4A4 (Hugging Face)
다른 양자화 변형: BF16 | FP8 | Space (체험)
Command A+ 공식 문서
 Cohere 홈페이지
Cohere 홈페이지
MoE 모델에서의 Speculative Decoding (Cohere 블로그)
Artificial Analysis Intelligence Index
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()