- 이 글은 GPT 모델로 자동 요약한 설명으로, 잘못된 내용이 있을 수 있으니 원문을 참고해주세요!

- 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다!


소개
Cohere에서는 최신 임베딩 모델인 Embed v3를 공개했습니다. Embed v3는 MTEB 및 BEIR 벤치마크에서 최고의 성능을 보입니다. 이 모델은 특히 잡음이 많은 데이터셋을 다룰 때 유용하며, 문서의 주제와 내용의 질을 평가하는 능력을 갖추고 있습니다. 또한, 벡터 데이터베이스 운영 비용을 크게 줄이는 압축 인식 학습 방법을 도입했습니다.

Embed v3의 주요 기능
Embed v3는 실제 세계의 잡음이 많은 데이터와 상호 작용하는 검색 애플리케이션을 개선하고, 검색-증강 생성(RAG) 시스템의 검색 기능을 향상시킵니다. 이 모델은 기업 데이터와 연결하는 데 있어 현재 생성형 AI 모델의 한계를 극복하는 데 도움이 됩니다. 예를 들어, 특정 고객과의 가격에 관한 논의 요약이 필요한 경우, Embed v3는 가장 관련성 높은 대화를 검색하여 생성형 모델에 필요한 정보를 제공합니다.
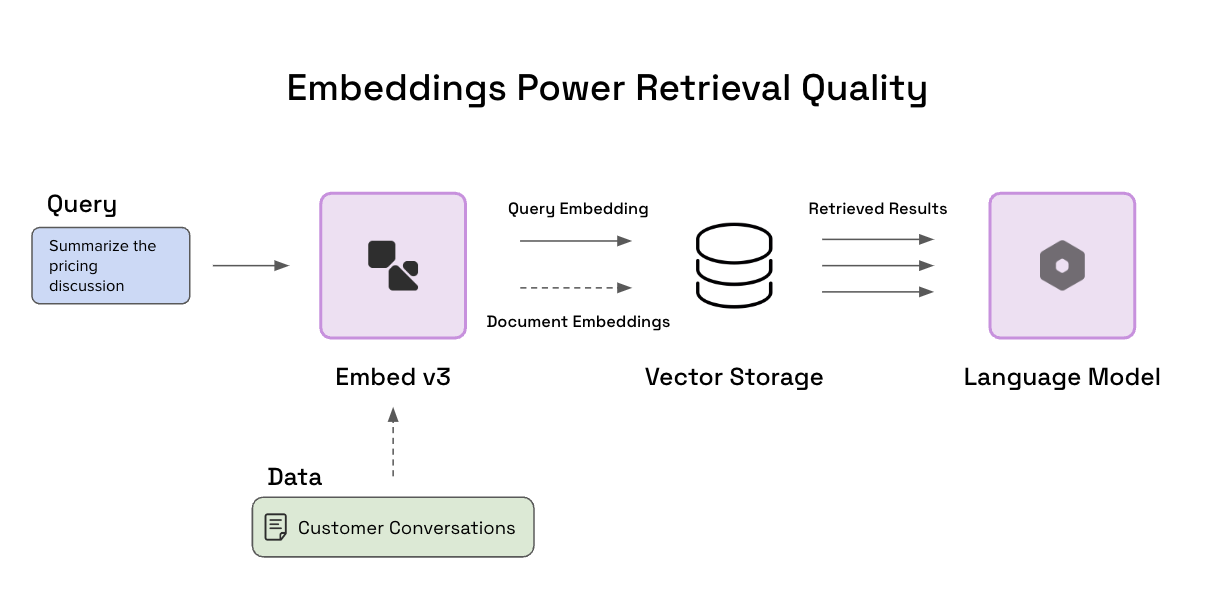
Embed v3 모델 성능
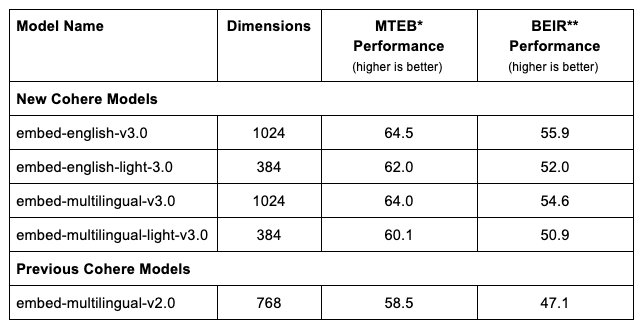
Embed v3는 영어 및 다국어 버전으로 제공되며, 1024 또는 384 차원의 모델이 있습니다. 이 모델들은 MTEB 및 BEIR 벤치마크에서 최고의 성능을 달성했습니다. 모든 모델은 정규화된 임베딩을 반환하며, 닷 프로덕트(dot product), 코사인 유사도(cosine similarity), 유클리디안 거리(Euclidean distance)를 유사도 측정 기준으로 사용할 수 있습니다.
새로운 필수 입력 파라미터: 입력 유형
새 모델에는 모든 API 호출에 설정해야 하는 새로운 필수 입력 파라미터인 input_type이 추가되었습니다. 이는 search_document, search_query, classification, clustering 중 하나를 포함해야 합니다. 이 입력 유형은 각 작업에 대한 최고의 품질을 보장하기 위해 필요합니다.
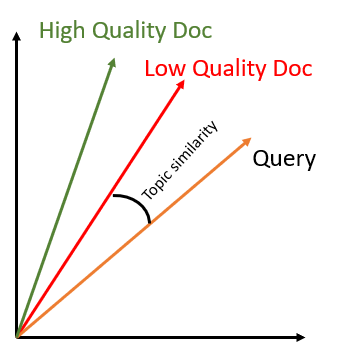
실제 데이터에 대한 정확도
이전 모델들은 주로 쿼리와 문서 간의 주제 유사성만을 측정했습니다. 하지만 Embed v3는 주제와 내용의 질을 모두 매칭하여 가장 유용한 정보를 제공하는 문서를 상위에 배치합니다.
Embed v3 모델 (HuggingFace)
Cohere Embed v3 Model (English, 영어 버전)
Cohere의 Embed v3 모델 저장소, 영어 버전 (HuggingFace)
Cohere Embed v3 Model (Light & English, 영어 버전)
Cohere의 Embed v3 모델 저장소, Light & 영어 버전 (HuggingFace)
Cohere Embed v3 Model (Multilingual, 다국어 버전)
Cohere의 Embed v3 모델 저장소, 다국어 버전 (HuggingFace)
Cohere Embed v3 Model (Light & Multilingual, 다국어 버전)
Cohere의 Embed v3 모델 저장소, Light & 다국어 버전 (HuggingFace)
더 읽어보기
Massive Text Embedding Benchmark (MTEB)
임베딩 모델의 성능을 평가하는 MTEB 데이터셋과 벤치마크에 대한 내용
BEIR
영역 외 검색에 초점을 맞춘 데이터셋으로, Embed v3의 성능 평가에 사용
MTEB Leader Board by HuggingFace
HuggingFace에서 제공하는 MTEB 벤치마크 리더보드
Cohere Embed v3 모델 사용해보기 (Cohere 계정/로그인 필요)
Cohere Embed v3 모델 소개 웨비나
https://info.cohere.ai/embed-v3-webinar