Crawl4AI 소개
Crawl4AI는 대규모 언어 모델(LLM)을 위한 웹 크롤링과 데이터 추출을 비동기적으로 처리하는 라이브러리입니다. 비동기 기능을 통해 여러 URL을 동시에 처리할 수 있고, 웹 페이지의 메타데이터, 미디어 태그, 링크 등을 손쉽게 추출할 수 있습니다. 이 도구는 Playwright와 같은 크롤러를 활용하여 성능을 극대화하고, 크롤링 대상 페이지에서 Javascript 실행 및 CSS 셀렉터를 통한 데이터 추출도 지원합니다.
기존의 동기 크롤링 방식은 웹 페이지 로드 시간과 실행 시간에 큰 영향을 받는 반면, Crawl4AI는 비동기 구조를 통해 빠르고 대규모의 데이터를 효율적으로 수집할 수 있습니다. 이를 통해 AI 응용 프로그램에 필요한 대량의 데이터를 신속하게 확보할 수 있습니다.
Crawl4AI의 주요 기능
- 무료 및 오픈소스: 누구나 자유롭게 사용할 수 있는 무료 오픈소스 프로젝트입니다.
- 빠른 성능: 상용 서비스보다 빠른 성능을 자랑합니다.
- 다양한 출력 형식 지원: JSON, HTML, Markdown 등의 LLM 친화적인 형식으로 데이터를 출력합니다.
- 다중 URL 크롤링: 여러 URL을 동시에 처리하여 효율적인 데이터 수집이 가능합니다.
- 미디어 태그 추출: 이미지, 오디오, 비디오 태그를 모두 추출합니다.
- 세션 관리 및 프록시 지원: 복잡한 다중 페이지 시나리오에 유용하며 프록시를 통해 개인 정보 보호 및 접근성을 강화합니다.
- 고급 데이터 추출: CSS 셀렉터 및 JavaScript 실행을 통해 정확한 데이터 추출이 가능하며, 세부 추출 전략도 지원합니다.
설치 방법
Crawl4AI는 Python 패키지로 설치하거나 Docker로 사용할 수 있습니다.
pip를 이용한 설치
pip install crawl4ai
기본적으로 Playwright를 사용하여 비동기 크롤링이 가능하며, 필요한 경우 Playwright를 수동으로 설치할 수 있습니다.
playwright install
Playwright에 문제가 발생한 경우, 다음의 명령어를 실행하면 해결이 되는 경우도 있습니다:
python -m playwright install chromium
동기 버전 설치
pip install crawl4ai 명령어는 자동으로 비동기(Asynchronous)로 동작하는 크롤러를 설치합니다. 동기식(Synchronous)으로 동작하는 크롤링을 원할 경우 Selenium을 사용한 동기 버전을 설치할 수 있습니다.
pip install crawl4ai[sync]
사용 방법
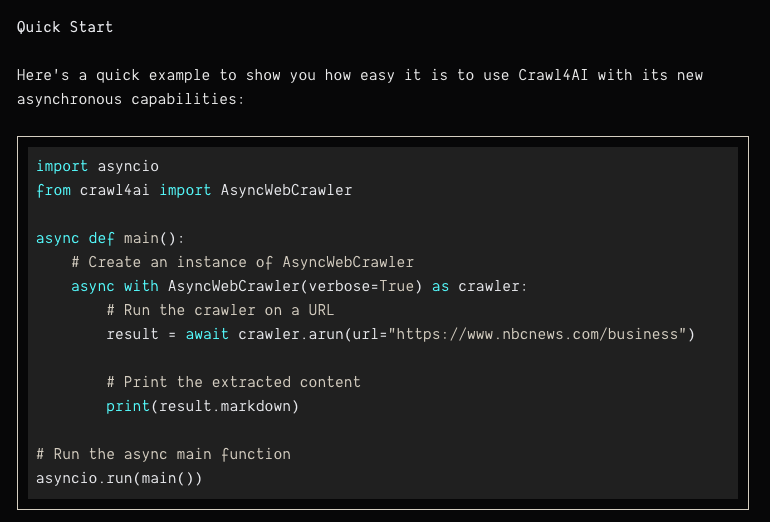
간단한 사용 예시는 다음과 같습니다:
import asyncio
from crawl4ai import AsyncWebCrawler
async def main():
async with AsyncWebCrawler(verbose=True) as crawler:
result = await crawler.arun(url="https://www.nbcnews.com/business")
print(result.markdown)
if __name__ == "__main__":
asyncio.run(main())
이 예시는 NBC 뉴스의 비즈니스 페이지를 크롤링하여 내용을 Markdown 형식으로 출력합니다.
Crawl4AI 라이선스
Crawl4AI 프로젝트는 Apache 2.0 License로 공개 및 배포되고 있습니다.
 Crawl4AI GitHub 저장소
Crawl4AI GitHub 저장소
https://github.com/unclecode/crawl4ai?tab=readme-ov-file
 Crawl4AI를 Google Colab에서 바로 사용해보기
Crawl4AI를 Google Colab에서 바로 사용해보기
 Crawl4AI 공식 문서
Crawl4AI 공식 문서
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()