- 생성형 AI 플랫폼 개발/서비스 기업 Fireworks.ai의 글을 허락 하에 번역하여 공유합니다.
- Fireworks.ai에서 작성한 원문은 아래 링크를 눌러 보실 수 있습니다.
 이 글에는 Firework Platform에 대한 사용 사례 및 홍보가 포함되어 있습니다.
이 글에는 Firework Platform에 대한 사용 사례 및 홍보가 포함되어 있습니다.
작성: 제임스 K 리드 (James K Reed), 드미트로 줄가코프(Dmytro Dzhulgakov)
이번 포스팅은 고성능의 Fireworks Gen AI 플랫폼에서 최적화를 위해 사용하는 방법에 대한 기술 블로그 시리즈 중 두 번째 글입니다. 다중 쿼리 어텐션에 대한 이전 포스팅도 참고해보세요.
This is the second in a series of technical blog posts about the techniques we use for optimization of the high-performance Fireworks Gen AI Platform. See also the previous post about Multi-Query Attention.
이 글에서는 지난 몇 년 동안 GPU 속도가 폭발적으로 증가하면서 딥러닝 워크로드에 대한 성능 최적화의 환경이 어떻게 변화했는지를 살펴봅니다. 이러한 추세로 인해 호스트 CPU가 어쩌다 병목(bottleneck)이 되었는지를 살펴보고, 이를 완화하기 위한 몇 가지 기법들을 알아봅니다. 특히, 성능과 사용성을 모두 갖춘 CUDA 그래프(CUDA graphs) 를 중점적으로 살펴봅니다. 대규모 언어 모델(LLM) 추론 시에 CUDA 그래프의 효과를 살펴보고, LLaMAv2-7B 추론 시 2.3배의 속도 향상을 보여드립니다. 또한, Fireworks Inference Platform에서 동급 최고의 속동와 효율을 제공하기 위해 CUDA 그래프와 기타 공격적인 머신 및 서비스 최적화를 사용함을 보입니다.
This post explores how the explosion in GPU speed over the past several years has changed the landscape of performance optimization for deep learning workloads. We examine how the host CPU has become a bottleneck due to this trend and review several techniques for mitigating this. We highlight one technique — CUDA graphs — that balances performance with usability. We examine the effect of CUDA graphs on Large Language Model (LLM) inference workloads and show a 2.3x speedup on a LLaMAv2–7B inference workload . We show that the Fireworks Inference Platform uses CUDA graphs and other aggressive machine and service optimizations to provide best-in-class speed and efficiency for LLM serving.
최신 GPU가 쉬지 않도록 하기: CPU/GPU 중첩(overlap) / Keeping Modern GPUs Busy: CPU/GPU Overlap
최근의 딥러닝 프로그램은 대부분 PyTorch framework(파이토치 프레임워크)를 기반으로 Python으로 작성됩니다. PyTorch는 기본적으로 간단합니다: 미리 최적화해둔 텐서(Tensor) 연산들의 모음으로, Python 프로그램에서 호출하여 사용합니다. 또한, PyTorch는 백서(paper)에서 설명하듯, 오랜기간 딥러닝 작업에서 높은 성능을 보여왔습니다. PyTorch 백서에 소개된 핵심 아이디어는 CPU/GPU 중첩(overlap) 입니다: CPU에서 실행되는 프로그램이 GPU에서 실행할 작업(커널/kernel)을 전송하고, CPU 프로그램이 GPU 작업보다 빠르게 실행되는 한, 높은 성능을 달성할 수 있다는 것입니다.
Contemporary deep learning programs are most often written in the Python language using PyTorch as a framework. PyTorch is fundamentally simple: a collection of pre-optimized Tensor operations that the user calls from a Python program. On the other hand, PyTorch has historically provided high performance for deep learning workloads, as described in the PyTorch paper. A key idea introduced in the PyTorch paper is the idea of CPU/GPU overlap : the CPU program dispatches work (kernels) for the GPU to execute, and so long as the CPU program runs faster than the GPU work, high performance is achieved.
대규모 배치 크기 학습 시의 높은 CPU/GPU 중첩 (A large batch-size training run with high CPU/GPU overlap)
그러나 시간이 지남에 따라 GPU 속도가 아주 빠르게 증가하게 되어, CPU/GPU 중첩에 대한 논문의 주장 또한 퇴색(less true)하게 되었습니다. 시간이 지나오면서 GPU 아키텍처에서의 부동 소수점 성능과 메모리 대역폭을 살펴보겠습니다:
- (PyTorch 백서에서 사용했던) GP100(2016)은 21 TFLOPS(테라플롭스)의 반정밀도(half-precision) 연산 속도와 730GB/s의 메모리 대역폭을 갖습니다
- V100(2017)은 112 TFLOPS(테라플롭스)의 반정밀도(텐서코어/TensorCore) 연산 속도와 900GB/s의 메모리 대역폭을 갖습니다.
- A100(2020)은 312 TFLOPS의 반정밀도(텐서코어) 연산 속도와 1600~2000GB/s의 메모리 대역폭을 갖습니다.
- H100(2022)은 989 TFLOPS의 반정밀도(텐서코어) 연산 속도와 3,350GB/s의 메모리 대역폭을 갖습니다.
However, the claims made in the paper about CPU/GPU overlap have become less true over time as GPU speeds have increased at a breakneck pace. Let’s examine floating point performance and memory bandwidth for GPU architectures over time:
- GP100 (as evaluated in the PyTorch paper) (2016) has 21 TFLOPS half-precision and 730 GB/s memory bandwidth
- V100 (2017) has 112 TFLOPS half-precision (TensorCores) and 900 GB/s memory bandwidth
- A100 (2020) has 312 TFLOPS half-precision (TensorCores) and 1600–2000 GB/s memory bandwidth
- H100 (2022) 989 TFLOPs half-precision (TensorCores) and 3350 GB/s memory bandwidth

시간 경과에 따른 NVIDIA GPU의 성능 비교 (NVIDIA GPU Performance Over Time)
PyTorch 백서가 작성된 이후로 GPU의 반정밀도 부동소수점(half-precision floating point) 성능은 47배, 메모리 대역폭은 4.6배 증가했습니다. 이러한 속도 향상은 딥러닝 워크로드에서 최대한의 성능을 제공할 수 있도록 하는, CPU의 성능이 GPU보다 앞선다는 전제에 중대한 영향을 미치게 됩니다.
GPU half-precision floating point performance has increased 47x and memory bandwidth has increased 4.6x since the PyTorch paper was written. This speedup has profound implications on the ability of the CPU to stay ahead of the GPU and deliver maximum performance for deep learning workloads.
CPU 오버헤드 - 어디에서 대부분의 시간을 사용하고 있을까? / CPU Overheads — Where Does All The Time Go?
PyTorch(파이토치) 프로그램이 실행될 때, CPU는 정확히 어떠한 작업을 하게 될까요? 여기에는 여러 층의 오버헤드가 존재하고 있습니다.
What exactly is the CPU doing when you run a PyTorch program? Several layers of overhead exist.
먼저, PyTorch 프로그램에는 CPU에서 실행되어야 하는 사용자-작성(user-written) 로직이 있습니다. 이러한 로직에는 메타프로그래밍(metaprogramming), 예를 들어 하이퍼파라미터(hyperparameter)를 기반으로 인공 신경망(network)의 구조를 파이썬 코드로 정의하는 것 등이 포함됩니다. 가장 간단한 예는 신경망의 여러 층(layer)에 대한 반복(loop)입니다. PyTorch 프로그램을 작성할 때 가장 좋은 방법은 모델 실행 중 이러한 오버헤드가 발생하지 않도록 이러한 로직을 모듈(Module) 구성쪽으로 내려보내(push)는 것입니다.
이렇게 하더라도, 메타프로그래밍 오버헤드는 대부분의 PyTorch 프로그램이 실행될 때 여전히 존재하게 됩니다.
First, a PyTorch program has user-written logic that must be executed on the CPU. This logic includes metaprogramming, i.e. defining the structure of the network in Python code based on the hyperparameters. The simplest example of this is a loop over network layers. The best practice when writing PyTorch programs is to push this logic into Module construction so that this overhead is not incurred during model execution. Nonetheless, metaprogramming overheads still exist at runtime in most PyTorch programs.
둘째로는 PyTorch 연산이 호출될 때 피연산자(operand)의 장치나 타입(dtype), 또는 autograd(한글 문서) 기록 활성화 여부 등에 따라 GPU에서 어떠한 연산 커널을 호출할지에 대해서 몇 가지 결정을 해야 하는 부분이 있습니다. 이러한 결정은 CPU에서 실행되는 디스패처(dispatcher)라는 컴포넌트에 의해 이루어집니다. 디스패처는 고도로 최적화된 C++로 작성되었지만, 그럼에도 디스패처의 실행은 PyTorch 프로그램을 실행하는 동안의 오버헤드에 여전히 기여하게 됩니다.
Second, when calling PyTorch operations, several decisions must be made about which compute kernel to call on the device (GPU) based on properties like the device/dtype of the operands or whether autograd recording is enabled. These decisions are made by a component called the dispatcher running on the CPU. Although the dispatcher is written as highly-optimized C++, its execution still contributes to runtime overhead while executing a PyTorch program.
셋째로, GPU의 메모리 할당도 실행 시 오버헤드에 기여합니다. PyTorch는 정교한 캐싱 메모리 할당자(caching memory allocator)를 사용하여 이러한 오버헤드의 상당부분을 완화하지만, 자잘한 연산들(small operations)로 이루어진 프로그램을 실행할 때는 CPU의 이러한 할당자 활동은 성능에 부정적인 영향을 끼칠 수 있습니다.
Third, GPU memory allocation contributes to runtime overhead. PyTorch uses a sophisticated caching memory allocator to alleviate much of this overhead, but runtime performance may still be negatively affected by allocator activities on the CPU when executing programs with small operations.
마지막으로 CUDA 자체는 드라이버 및 커널 실행 경로에 오버헤드가 있어 프로그램의 CPU 실행 속도가 느려질 수 있습니다.
Finally, CUDA itself has overheads in the driver and kernel launch paths, which can slow down the CPU execution of the program.
야수(GPU)에게 먹이를 주세요: CPU 오버헤드 최적화 / Feed the (GPU) Beast: Optimizing for CPU Overheads
GPU가 계속 빨라짐에 따라 딥러닝 프로그램을 실행할 때 CPU 오버헤드가 더 큰 문제가 되고 있습니다. 이 문제를 해결하기 위해 몇 가지 기법과 도구들이 등장했습니다.
As GPUs get faster, CPU overheads become more of a problem when executing deep learning programs. Several techniques and tools have emerged to solve this problem.

허깅페이스 트랜스포머 모델에서 배치 크기 1로 추론을 실행할 때 CPU/GPU 중첩이 매우 낮은 모습 / A batch-size 1 inference run on a HuggingFace Transformers model with very poor CPU/GPU overlap
HuggingFace Transformers는 Transformer 아키텍처에 기반한, 언어 모델을 위한 보편적인 코드베이스(ubiquitous codebase)입니다. 그러나, 유연성(flexibility)을 극대화하다보니 상당한 CPU 오버헤드를 발생시키는 방식으로 만들어진 파이썬 때문에 Transformer는 추론에 최적화되어 있지는 않습니다. 이와 반대편에는 고도로 최적화된 C++로 작성하여 성능을 극대화시킨 FasterTransformer(FT)가 있습니다. 하지만 FT의 최적화된 C++ 코드는 손을 대기가 상당히 어려워 새로운 기능을 개발하거나 새로운 모델 아키텍처를 추가하기 위한 개발 시간이 느립니다. (예를 들어, LLaMA 모델은 아직 공식 지원 대상이 아닙니다.)
HuggingFace Transformers is a ubiquitous codebase for language models based on the Transformer architecture. However, in practice, Transformers is not highly optimized for inference, as the Python code is written in a way that maximizes flexibility but incurs significant CPU overhead. On the other end of the spectrum is FasterTransformer (FT), written in highly optimized C++ to maximize performance. In practice, FT’s optimized C++ code is quite hard to work with, slowing down the development of new features or adding new model architectures (e.g. LLaMA models are not officially supported).
성능을 최적화하기 위한 또 다른 접근 방식은 컴파일을 통한 자동 코드 변환입니다. 이러한 접근 방식의 초기 예 중 하나로 Apache TVM이 있으며, Apache TVM은 신경망의 고수준 표현(high-level representation)을 (GPU 등의) 네이티브 머신 코드로 컴파일하는 종단간(End-to-End) 스택을 제공합니다. 하지만 유연한 PyTorch 프로그램을 TVM의 고수준 표현으로 변환하는 작업은 간단치 않으며(non-trivial), 특히 파이썬으로 구현된 제어 흐름(예. 반복문(loop), 분기문(branch))이나, 분산처리 연산(distributed operation)이 포함되어 있는 경우에는 더욱 어렵습니다. 실행 시점에 Tensor의 크기(shape)가 변하는 동적 쉐입(dynamic shape)은 추가적인 복잡성을 야기합니다.
Another approach to performance optimization is automatic code transformation via compilation. Apache TVM is an early example of this approach, which provided an end-to-end stack that compiled a high-level representation of a neural network down to native machine code (e.g. on GPU). However, converting from a flexible PyTorch program to TVM’s high-level representation is non-trivial, especially when a program contains control flow (loops, branches) implemented in Python or when a program involves distributed operations. Dynamic shapes (Tensor shapes that change at runtime) introduce additional complications.
새로운 접근 방식은 PyTorch 2.0과 함께 출시된 torch.compile()입니다. torch.compile()은 기존의 컴파일 스택의 사용성을 개선하는 TorchDynamo를 도입하였습니다. TorchDynamo는 자동으로 파이썬 바이트코드(bytecode)를 분석하여, 프로그램에서 컴파일할 수 있는 부분을 추출하는 새로운 프론트엔드입니다. 그러나 이러한 접근 방식은 임의의 파이썬 코드가 호스트와 장치 간의 동기화를 발생시키는 그래프 중단(graph breaks) 을 야기할 수 있어 누구나 안심하고 사용(fool-proof)하기는 어렵습니다. 또한, torch.compile()의 동적 쉐입(dynamic shape) 및 분산처리 연산(distributed operation) 지원은 아직 개발 중이며, 이 기능이 없으면 LLM 추론 워크로드에 대한 torch.compile()의 적용 가능성(applicability)은 제한적입니다. 또한, PagedAttention에서 사용하는 임의의 메모리 레이아웃 관리(memory layout management) 및 변형(mutation) 기능은 일반적으로 최신 딥러닝 컴파일러들에서는 지원하지 않습니다. LLM 추론 시의 torch.compile()을 사용한 실험에 대한 자세한 내용은 부록(Appendix)을 참조하세요.
A newer approach is
torch.compile, as released with PyTorch 2.0.torch.compileimproves upon the usability of existing compilation stacks with TorchDynamo, a new front-end that automatically analyzes the Python bytecode of the program to extract sections of the program that can be compiled. However, this approach is not fool-proof, as arbitrary Python code can introduce graph breaks , which deoptimize the code and cause host-device synchronization. Additionally,torch.compile’s support for dynamic shapes and distributed operations is still in development, and without it, the applicability oftorch.compileto LLM inference workloads is limited. Further, support for arbitrary memory layout management and mutation as used in the PagedAttention approach is generally not supported by contemporary deep learning compilers. See the Appendix for details about our experiments withtorch.compileon LLM inference.
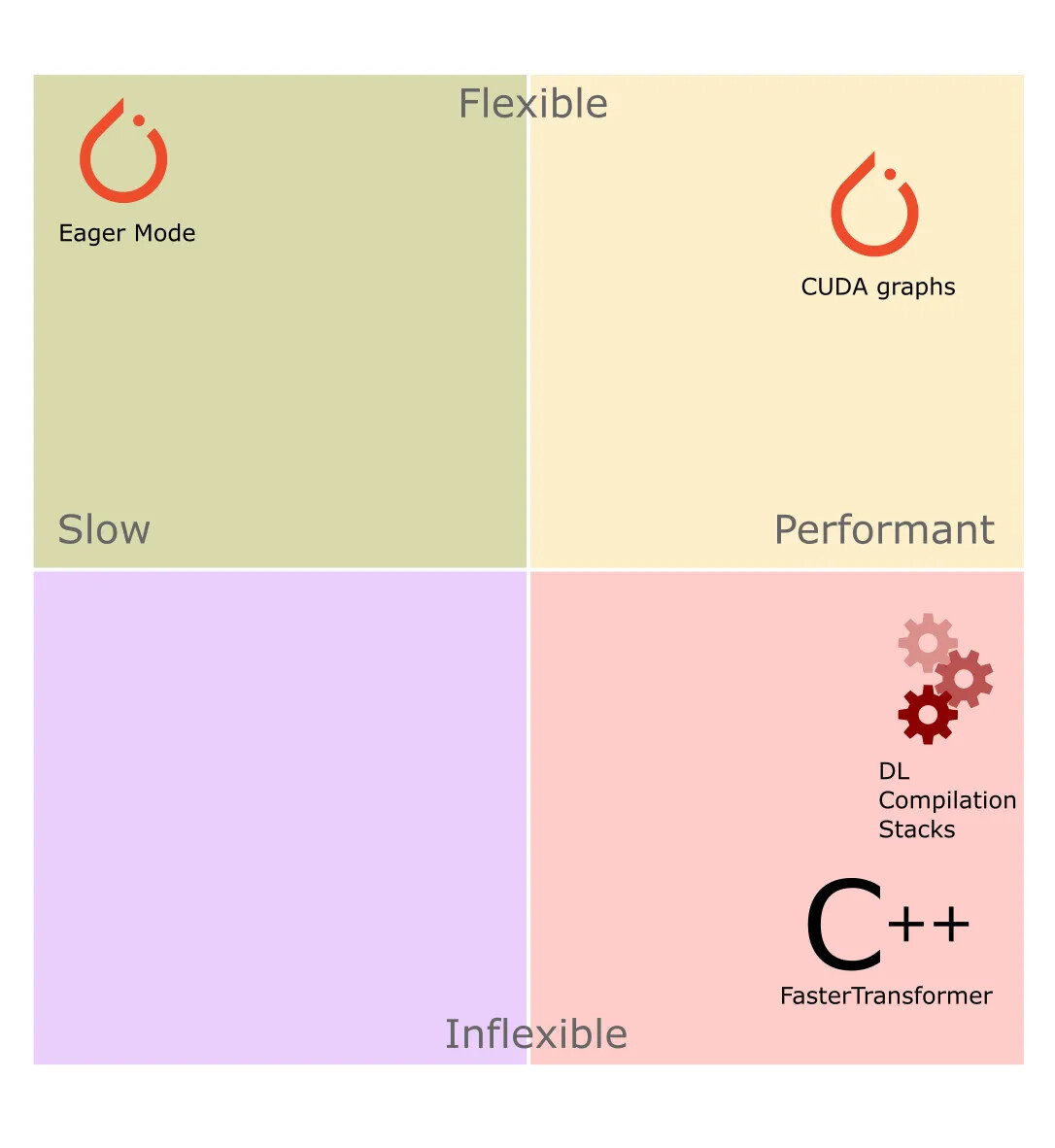
성능 최적화를 위한 접근 방식: 유연성과 속도 사이의 다양한 절충점을 나타냅니다. / Approaches to performance optimization represent various trade-offs between flexibility and speed
지금까지 제시한 접근 방식들은 각기 다른 장단점(trade-off)을 가지고 있지만, 사용성과 성능 사이에서 균형을 이루고 있다고 생각하는 한 가지 옵션을 강조하고자 합니다: 바로 CUDA 그래프(CUDA graph)입니다.
Each of the approaches presented has different trade-offs; However, we’d like to highlight one option that we believe balances usability and performance: CUDA graphs.
CUDA 그래프 / CUDA Graphs
CUDA 10에서 NVIDIA는 CUDA 그래프라는 기능을 도입했습니다. CUDA 그래프는 프로그램이 호출(invoke)한 GPU 커널을 그래프 데이터 구조에 기록한 뒤, 나중에 원래 프로그램의 CPU 오버헤드 없이 해당 그래프에 저장된 커널을 재생(replay)할 수 있는 방법을 제공합니다. 이러한 접근 방식은 특정한 연산들(sequence of operations)이 여러번 호출되는 GPU 프로그램의 성능을 개선하는데 도움이 될 수 있습니다. 즉, 그래프 표현방식(graph representation)은 커널 디스패치까지의 프로그램에 대한 특수한 표현방식(specialized representation)이라고 할 수 있습니다. 예를 들어, 트레이싱 시점(trace time)의 커널 시퀀스와 (텐서 메모리에 대한 포인터들을 비롯한) 인수들이 그래프 내에 "포함되어(baked in)" 있습니다. 따라서 CUDA 그래프를 기록할 시에는 커널의 인자들이 실행 시점과 동일하게 유지되도록 주의해야 합니다.
In CUDA 10, NVIDIA introduced a feature called CUDA graphs. CUDA graphs provide a way to record the GPU kernels invoked by a program into a graph data structure and later replay the kernels stored in that graph without incurring the original program's CPU overhead. This approach can help improve the performance of a GPU program where a specific sequence of operations is called many times. In other words, the graph representation can be said to be a specialized representation of the program down to kernel dispatch, i.e. the sequence of kernels and the arguments used at trace time (including pointers to Tensor memory) are “baked in” to the graph. Thus, care is needed when recording a CUDA graph to ensure that kernel arguments remain the same across runs.
CUDA 그래프 API 외에도, PyTorch(파이토치)는 파이썬 API에서 CUDA 그래프를 지원하기 시작했습니다. PyTorch CUDA 그래프 API는 실행 전반에 걸쳐 텐서 할당(뿐만 아니라 텐서 포인터까지)의 안정성을 보장하기 위해 PyTorch 할당자(allocator)의 상태 관리를 추가적으로 지원하고 있습니다.
On top of the CUDA graph API, PyTorch introduced support for CUDA graphs from the Python API. The PyTorch CUDA graph API provides additional support for managing PyTorch allocator state to ensure the stability of Tensor allocations (and thus Tensor pointers) across runs.
CUDA 그래프는 위에서 강조한 CPU 오버헤드의 모든 원인들(사용자 작성 로직, PyTorch 디스패처 로직, 메모리 할당 오버헤드, GPU 드라이버/커널 오버헤드)을 처리합니다. 또한, PyTorch의 CUDA 그래프 API는 프로그램(또는 프로그램의 일부)이 몇몇 제약 조건을 준수한다면 크게 걸리적거리지도 않습니다. 따라서, 최적화되었지만 지저분한 C++이 아닌, 파이썬으로 코드를 더 쉽게 작성하고 유지/관리할 수 있습니다.
CUDA graphs address all sources of CPU overhead highlighted above: user-written logic, PyTorch dispatcher logic, memory allocation overhead, and GPU driver/kernel overhead. In addition, the CUDA graphs API in PyTorch is relatively unintrusive so long as you can ensure that your program (or part of your program) conforms to a few constraints. This leads to easier to write and maintain code written in Python rather than in messy, optimized C++.
LLM 추론 + CUDA 그래프 / LLM Inference + CUDA graphs
(GPT 계열의 모델과 같은) 디코더 LLM에서 추론을 할 때 2가지 연산 단계가 있습니다: 프롬프트를 이해(consume)하는 프리필(prefill) 단계와 출력 토큰을 하나씩 단계적으로 생성(incremental generation) 하는 단계가 그것들입니다. 배치 크기 또는 입력의 길이가 충분히 큰 경우 프리필(prefill) 단계는 충분히 많은 수의 토큰을 병렬로 처리하게 되므로 GPU 성능이 병목 현상을 발생하지 않고, CPU 오버헤드가 성능에 영향을 미치지 않습니다. 하지만, 대화형 사례 등에서는, 단계적 생성(incremental generation) 시 시퀀스 길이가 1인 상태로 배치 크기까지 작은 상태(심지어는 1)로 실행되는 경우가 많습니다. 따라서 증분 생성 단계는 CPU 속도에 의해 제한될 수 있으므로, CUDA 그래프를 사용하기에 적절한 후보입니다.
When running inference on a decoder LLM (such as the GPT family of models), there are two computation phases: a prefill phase that consumes the prompt and an incremental generation phase that generates output tokens one by one. Given a high enough batch size or input length, prefill operates on a sufficiently high number of tokens in parallel that GPU performance is the bottleneck and CPU overheads do not impact performance. On the other hand, incremental generation is always executed with sequence length 1 and it is often executed with a small batch size (even 1), e.g. for interactive use cases. Thus, incremental generation can be limited by the CPU speed and thus is a good candidate for CUDA graphs.
CUDA 그래프를 사용하기 위해서는 고정된 크기(shape)와 같은 몇가지 제약 조건이 있다는 것을 다시 떠올려주세요. 단계적 생성 단계에서는 시퀀스 길이가 고정되어 있으며, 고정된 배치 크기로 실행할 수 있습니다. 하지만, 어텐션을 계산할 때에는 지금까지 처리했던 토큰들에 대해서 동작하므로, 각 단계마다 차원이 하나씩 증가하게 됩니다. 어렇게 처리된 시퀀스는 KV-캐시(KV-cache)에 저장됩니다. 아래는 증가하는 어텐션을 KV-캐싱으로 처리하는 것을 보이기 위한 (이전 블로그 글에서 가져온) 예시 코드입니다:
Recall that CUDA graphs have several constraints, including a requirement for fixed shapes. Incremental generation has a fixed sequence length and can be run with a fixed batch size. However, the attention computation operates on the tokens processed so far, meaning this dimension increases by one with each step. These processed sequences are stored in a KV-cache. Here we present a code sample demonstrating incremental attention with KV-caching (reproduced from this blog post):
# N, h, d_k는 모두 고정된 값들입니다! (N, h, and d_k are all fixed!)
# K, V는 매 반복 시마다 캐시된 값들입니다 (Cached K and V values across iterations)
K = torch.randn(N, h, ..., d_k)
V = torch.randn(N, h, ..., d_k)
# 시퀀스 생성 도중의 QKV 값들 (Single-step QKV values computed during sequence generation)
Q_incr = torch.randn(N, h, 1, d_k)
K_incr = torch.randn(N, h, 1, d_k)
V_incr = torch.randn(N, h, 1, d_k)
# <...>
# KV-캐시 갱신 (Update KV-cache)
K = torch.cat([K, K_incr], dim=-2)
V = torch.cat([V, V_incr], dim=-2)
# 어텐션 계산 (L은 지금까지의 시퀀스 길이) (Compute attention (L is sequence length so far))
# ****L은 매 반복 시마다 변경됩니다!**** (****L changes on each iteration!****)
logits = torch.matmul(Q_incr, K.transpose(2, 3)) # 출력 크기(Output shape) [N, h, 1, L]
softmax_out = torch.softmax(logits / math.sqrt(d_k), dim=-1) # 출력 크기(Output shape) [N, h, 1, L]
attn_out = torch.matmul(softmax_out, V) # 출력 크기(Output shape) [N, h, 1, d_k]
일반적엔 어텐션 메커니즘과 PagedAttention 체계(scheme) 모두 반복을 거듭함에 따라 크기가 달라지지만, PagedAttention은 CUDA 그래프와 통합할 때 특별한 이점을 제공합니다. 커널 인자들에 대한 관점에서 보면, PagedAttention은 Tensor 주소에 대해 어느 정도의 방향성(level of indirection)을 제공하고 있습니다. K와 V 캐시의 포인터(base pointer)들은 반복을 거듭할 때에도 일관성(consistent)을 유지하고 있으며 커널 인자로 보존(preserve)하더라도 안전합니다. 커널이 동작하는 캐시 위치들은 GPU 메모리 상의 고정된 위치의 버퍼에 저장되므로, 특정 K 및 V 위치에 대한 포인터는 전적으로 해당 커널 내에서 계산할 수 있습니다. 결과적으로, 단계적 생성 단계에서 이뤄지는 전체 연산들을 CUDA 그래프에 안정적으로 기록할 수 있습니다.
While both the regular attention mechanism and the PagedAttention scheme undergo shape changes over iterations, the latter provides a unique advantage when integrating with CUDA graphs. From the perspective of kernel arguments, PagedAttention provides a level of indirection for Tensor addresses. The base pointers to the K and V caches remain consistent across iterations and are safe to preserve as kernel arguments. The set of cache locations the kernel operates on is stored in a buffer with a fixed location in GPU memory, and thus, pointers to specific K and V locations can be computed entirely within the kernel. As a result, the entire computation within the incremental generation step can be soundly recorded into a CUDA graph.
PagedAttention은 페이지 매핑(page mapping)을 추적하기 위해 block_tables라는 다양한 크기(varying-size)의 텐서를 사용하는데, 이 텐서는 CUDA 그래프에 문제가 될 수 있습니다. 그러나, 이 텐서의 값(element)들은 상대적으로 작은 인덱스이므로, 손쉽게(cheaply) 패딩(pad)할 수 있습니다. 이후로는 block_tables 텐서의 일부(subset)를 각 호출(invocation)에 사용합니다. 이러한 설계는 PyTorch의 개발 환경이 제공하는 유연성과 잘 맞을 뿐만 아니라 코드의 간결함을 유지하면서도 FasterTransformers와 동등하거나 더 우수한 성능을 보장합니다.
To keep track of page mapping, PagedAttention uses a varying-size Tensor called
block_tables, which would naïvely present issues for CUDA graphs. However, this Tensor can be cheaply padded since its elements are relatively small indices. A subset of theblock_tablestensor is then used on each invocation. This design not only aligns well with the flexibility offered by PyTorch’s coding environment, but it also ensures a runtime that’s either equivalent or superior to FasterTransformers, all while maintaining code simplicity.
CUDA 그래프는 크기(shape)에 특화되어 있으므로, 실행 시점에 배치 크기를 변경하는 경우에는 특별한 주의를 기울여야 합니다. 다양한 배치 크기에 대해 CUDA 그래프를 사용하는 경우, 각각의 배치 크기에 대해서 별도의 그래프를 추적(trace)하고, 실행 시에 적절한 그래프를 사용(dispatch)하는 것이 좋습니다.
Since CUDA graphs are shape-specialized, special care must be taken when handling a changing batch size at runtime. When using CUDA graphs for multiple batch sizes, it’s best to trace a separate graph for each batch size and dispatch to the appropriate one during runtime.
PyTorch의 CUDA 그래프는 메모리 풀(memory pool)을 사용하여 트레이싱시(trace time)의 할당 내역(allocation)을 캡슐화(encapsulate)한 뒤, 실행 시점(runtime)에 해당 할당 내역(과 포인터)을 사용할 수 있도록 지원합니다. 다양한 배치 크기를 컴파일하는 경우에는 각각의 그래프가 별도의 메모리 풀을 갖는 대신 하나의 공유 메모리 풀(shared memory pool)을 재사용할 수 있습니다. 따라서 내림차순으로 배치 크기가 큰 것부터 순차적으로 그래프를 컴파일하게 되면 이전에 할당했던 더 큰 버퍼로 더 작은 배치(allocation)들을 처리할 수 있으므로, 공유 풀의 메모리가 재사용됩니다. 이러 식으로 GPU 메모리를 과하게 사용하지 않고도 여러 배치 크기를 처리할 수 있습니다.
PyTorch’s CUDA graphs support using a memory pool to encapsulate allocations used during trace time and use them (and crucially, their pointers) during runtime. When compiling for multiple batch sizes, instead of giving each graph its own memory pool, a single shared memory pool can be used. By compiling graphs in decreasing order of batch size, memory from the shared pool is reused, as smaller allocations can be serviced by larger allocated buffers from a previous iteration. This way, multiple batch sizes are supported without using excessive GPU memory.
실제 CUDA 그래프: LLaMA v2 추론 / Real-World CUDA Graphs: LLaMA v2 Inference
CUDA 그래프의 실질적인 적용 사례를 보이기 위해 Meta AI에서 공개한 LLaMA2의 소스코드를 변경합니다. 전체 변경 사항은 여기에서 확인할 수 있습니다. CUDA 그래프를 활성화하기 위해서는, 어텐션을 구현하는 방식을 일부 변경하고, 생성 루틴에 일부 기반 코드를 추가하는 정도로 다소 미미합니다.
To demonstrate applying CUDA graphs in a real-world scenario, we modify the source code of the LLaMA2 code as released by Meta research. A full diff can be found here. The changes required to enable CUDA graphs are rather minimal, consisting of some changes to how attention is implemented in the model and some infrastructural additions in the generation routines.
어텐션쪽에서는 KV 캐시가 새로운 값을 작성할 인덱스들을 파이썬 정수형(integer) 대신 CUDA 텐서(Tensor)에서 사용하도록 변경합니다. 또한 어텐션을 최대 시퀀스 길이에 대해 계산하되, 현 시점의 단계가 시퀀스 위치보다 작은 경우(sequence position <= current time step)에만 소프트맥스(softmax)를 계산하도록 변경합니다. 변경 내역은 아래와 같습니다:
For modifications to attention, we modify the KV-cache handling to take the indices in which to write new values in a CUDA Tensor rather than a Python integer. We also modify attention to compute over the max sequence length but only compute softmax over the sequence positions <= the current time step. The changes are as follows:
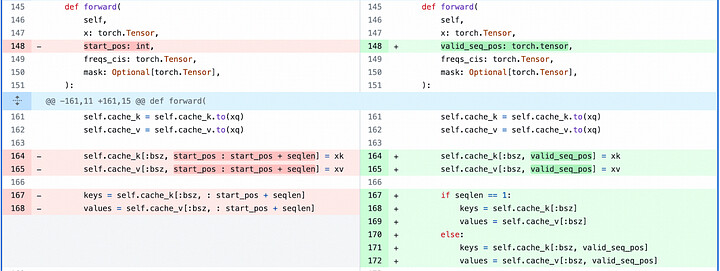
CUDA 그래프를 지원하기 위한 어텐션 수정사항 / Modifications made to attention to support CUDA graphs
이리한 변경 사항을 지원하기 위해 KV 캐시 인덱스와 어텐션 마스크쪽을 리팩토링했습니다. KV 캐시 인덱스를 CUDA 텐서형으로 생성합니다. 또한, 기존의 인과 마스킹(causal masking)에 더해, 최대 max_seq_len까지 시퀀스 위치를 마스킹할 수 있도록 마스킹 생성부를 확대(augment)했습니다:
To support this change, we refactor the generation of KV-cache indices and the attention mask. We generate the KV cache indices as a CUDA Tensor. We also augment mask generation to mask out sequence positions up to max_seq_len, in addition to traditional causal masking:
def params_for_incremental_gen(self, tokens : torch.Tensor, prev_pos : int, cur_pos : int, device : torch.device):
tokens_sliced = tokens[:, prev_pos:cur_pos].to(device=device)
valid_seq_pos = torch.arange(prev_pos, cur_pos, device=device)
mask = torch.full(
(1, 1, 1, self.params.max_seq_len), float("-inf"), device=device
)
mask[:, :, :, :valid_seq_pos.item() + 1] = 0.0
return tokens_sliced, mask, valid_seq_pos
이러한 변경 사항은 적절하지만 필요 이상으로 (최대 max_seq_len까지) 많은 시퀀스들에 대해서 어텐션을 계산하므로 다소 비효율적입니다. PagedAttention은 이 문제를 해결하기 위해 KV 캐시 관리를 커널 자체로 밀어넣음으로써 불필요한 연산을 피하는 방식을 취합니다. 그러니 이러한 간단한(naïve) 접근 방식으로도 CUDA 그래프가 표준 PyTorch 코드에 비해 더 나은 성능을 제공함을 보여줍니다.
Note that these changes are correct but rather inefficient, as we compute attention over more sequence positions than we need to (up to
max_seq_len). The PagedAttention approach addresses this issue, pushing KV-cache management into the kernels themselves while avoiding unnecessary computation. However, we show that even with this naïve approach, CUDA graphs present significant performance advantages over stock PyTorch code.
단계적 생성 단계에서 CUDA 그래프를 위한 모델을 컴파일하는데 필요한 인프라는 매우 간단하며 PyTorch 문서의 예제와 비슷합니다. 추가적인 호출을 위해 정적 입력과 출력을 캐시하는데는 특별한 주의를 약간 기울여야 하지만, 그 외에는 코드가 직관적입니다:
The infrastructure needed to compile the model for CUDA graphs in incremental generation is fairly simple and close to the examples in the PyTorch documentation. Some special care is taken to cache static inputs and outputs for further invocation, but otherwise, the code is straightforward:
def _compile_model(self, tokens_sliced : torch.Tensor, mask : torch.Tensor, valid_seq_pos : torch.Tensor):
assert self._cuda_graph is None and self._compiled_inputs is None and self._compiled_logits is None, "Already compiled the model"
self._compiled_inputs = tuple(v.clone() for v in (tokens_sliced, mask, valid_seq_pos))
s = torch.cuda.Stream()
s.wait_stream(torch.cuda.current_stream())
with torch.cuda.stream(s):
_ = self.model.forward(*self._compiled_inputs)
torch.cuda.current_stream().wait_stream(s)
self._cuda_graph = torch.cuda.CUDA graph()
with torch.cuda.graph(self._cuda_graph):
self._compiled_logits = self.model.forward(*self._compiled_inputs)
def replay(tokens, mask, valid_seq_pos):
self._compiled_inputs[0].copy_(tokens)
self._compiled_inputs[1].copy_(mask)
self._compiled_inputs[2].copy_(valid_seq_pos)
self._cuda_graph.replay()
return self._compiled_logits
return replay
또한, 파이썬 데코레이터를 사용하여 CUDA 그래프를 쉽게 적용할 수 있는 Bram Wasti의 기법도 소개합니다. 이 접근 방식은 복잡한(non-trivial) LLM 추론 사례에는 적절하지 않지만, 이미지 모델 추론이나 고정 크기의 학습 등과 같은 다른 다양한 사례에 적용할 수 있습니다.
LLaMA2-7B + CUDA 그래프 추론의 성능 결과 / LLaMA2–7B + CUDA Graph Inference Performance Results
지금까지 살펴본 방식으로 LLaMA-2 7B 모델의 변형(variant)을 컴파일하고, batch_size=1의 추론 조건에서 테스트합니다. CUDA 그래프를 비활성화 및 활성화한 상태에서 각각 추론 성능 측정을 위한 벤치마크 도구(harness)를 구현하고, 단일 NVIDIA A100-SXM4-80GB GPU에서 테스트합니다. CUDA 그래프를 사용하지 않은 경우 LLaMA-7B 추론 시 초당 30토큰을 생성하지만, CUDA 그래프를 활성화하면 2.3배 빠른 속도인 초당 69개 토큰을 생성함을 확인하였습니다.
We test the above approach for compiling LLaMA-2 with the 7B model variant under
batch_size=1inference conditions. We implement a benchmark harness to measure inference performance with CUDA graphs disabled and enabled, respectively. We test on a single NVIDIA A100-SXM4–80GB GPU. We find that without CUDA graphs, LLaMA-7B inference executes at 30 tokens/sec, but with CUDA graphs enabled it executes at 69 tokens/sec for a 2.3x speedup .
이러한 속도 향상은 전적으로 CPU 오버헤드 감소로 설명할 수 있습니다. (CUDA 그래프를 켜지 않은) 베이스라인은 CPU 실행이 주도합니다 - GPU 연산 커널은 CPU가 이를 실행할 때까지 대기하고 있습니다. 이는 성능 프로파일 시 확인할 수 있습니다:
We find that this speedup is entirely explained by CPU overhead reduction. The baseline run is dominated by CPU execution — GPU compute kernels are waiting for the CPU to dispatch them. This can be seen from a performance profile:
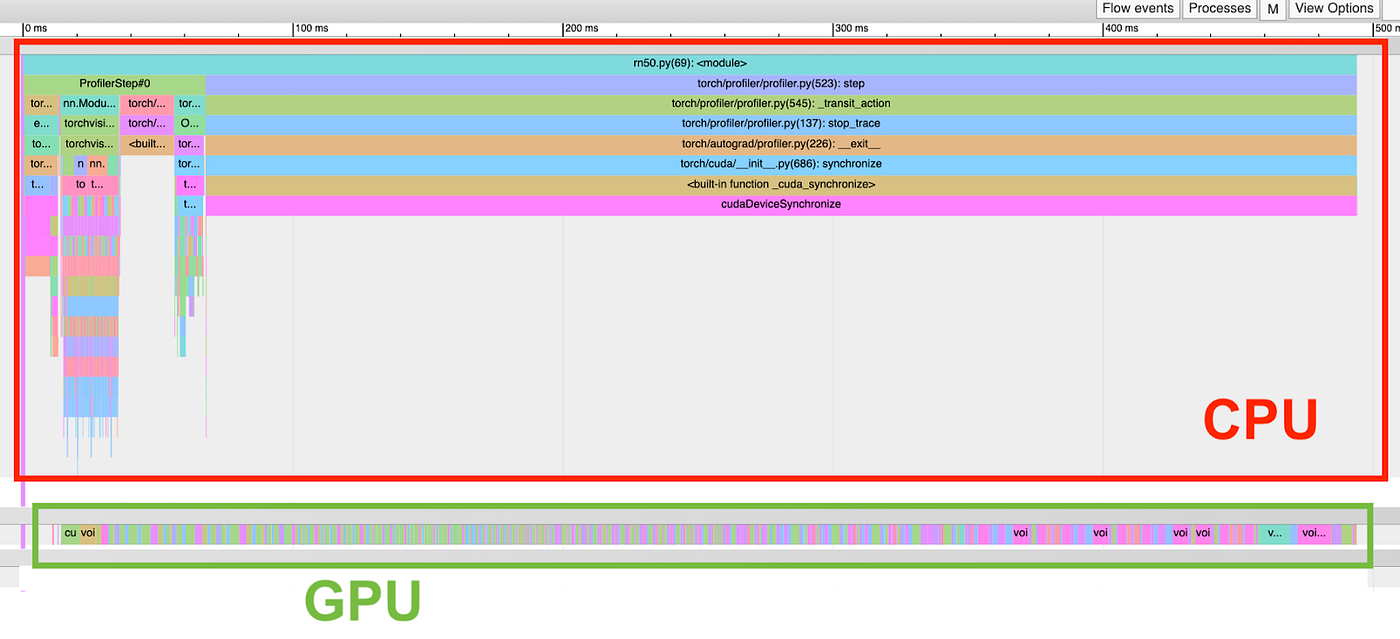
CUDA 그래프를 사용하지 않은 모델의 전체 실행 타임라인 / Overall Timeline of Execution for Non-CUDA Graph Model

위 CUDA 그래프를 사용하지 않은 모델의 실행 타임라인 상세보기 / Detail View of Timeline of Execution for Non-CUDA Graph Model
위 타임라인에서 GPU(각 이미지의 아래쪽 타임라인)는 대부분의 시간을 유휴(idle) 상태로 보내며 CPU(각 이미지의 위쪽 타임라인)가 작업을 실행할 때까지 대기합니다. 반면, CUDA 그래프를 활성화하고 실행 시, 긴 커널 시퀀스를 한 번에 실행하는 빡빡한(tight) 커널 디스패치 동작을 보여줍니다:

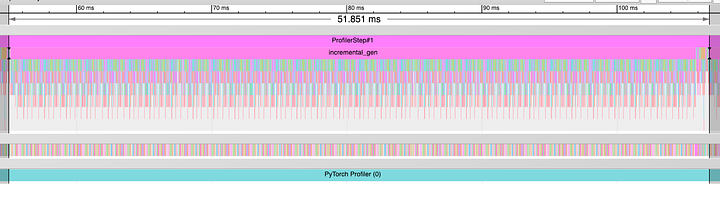
CUDA 그래프를 사용한 모델의 전체 실행 타임라인 / Overall Timeline of Execution for CUDA Graph Model
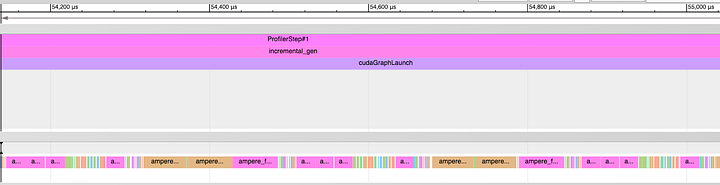
위 CUDA 그래프를 사용한 모델의 실행 타임라인 상세보기 / Detail View of Timeline of Execution for CUDA Graph Model
위 타임라인에서는 CPU 오버헤드가 생략되었기 때문에 GPU가 지속적으로 작업을 수행하고 있습니다.
Firework inference platform에서의 CUDA 그래프 / CUDA Graphs in the Fireworks Inference Platform
Fireworks Inference Platform에서 서비스되는 모든 모델은 CUDA 그래프를 대단히 많이 사용하고 있습니다. 업계 최고 수준의 추론 성능을 제공하기 위해 CUDA 그래프를 비롯한 다양한 기법들(다중 쿼리 어텐션(multi-query attention) 등)을 적용하고 있습니다. 또한, CUDA 그래프를 비롯한 다른 최적화를 적극적으로 적용한 LLaMA 및 StarCoder 제품군들을 포함하여 다양한 모델들을 지원하고 있습니다. CUDA 그래프를 포함한 파이썬 중심의 코드베이스를 사용하여 개발의 유연성과 속도를 유지하면서 우수한 성능을 얻을 수 있습니다. 이를 통해 Code Llama와 같은 최신 모델을 출시 직후 몇 시간 만에 구현하는 등, AI 개발의 최전선(cutting edge)에 설 수 있습니다.
The Fireworks Inference Platform makes heavy use of CUDA graphs for all served models. We apply CUDA graphs and numerous other techniques (including multi-query attention and others) to provide the best inference performance in the industry. We support a growing number of models, including those in the LLaMA and StarCoder families, all with CUDA graphs and aggressive optimizations applied. Our Python-centric codebase with CUDA graphs allows us to get good performance while still retaining the flexibility and speed of development. This allows us to be on the cutting edge of AI development, e.g., enabling the latest models like Code Llama just hours after their release.
지금 바로 무료로 모델을 Fireworks Inference Platform에서에서 사용해 보고, Fireworks Platform의 LLM이 귀사의 제품에 어떠한 성능을 제공할 수 있는지 확인해보세요.
Try out models on our platform today for free to see what kind of performance we can deliver for Large Language Models in your product.
결론 / Conclusion
정리하면, 최근 몇 년간 GPU 속도가 크게 발전하면서 딥러닝 워크로드에 대한 성능 최적화 분야가 크게 변화했습니다. 결과적으로, 호스트 CPU가 처리 시의 병목으로 부상하게 되었습니다. 이를 해결하기 위해 우리는 여러가지 기술들을 평가했으며, 그 중 CUDA 그래프는 상당한 성능의 향상과 코드의 유연성 및 사용 편의성을 결합한 방법이었습니다. 대규모 언어 모델(LLM)의 워크로드에 대한 CUDA 그래프의 영향을 연구한 결과, 빠른 GPU 개선에 직면한 상황에서 성능 최적화를 위한 강력한 방법이라는 결론을 내렸으며, 이를 Fireworks 생성형 AI 플랫폼에 광범위하게 활용하고 있습니다.
In conclusion, the substantial advancements in GPU speed in recent years have significantly altered the field of performance optimization for deep learning workloads. As a result, the host CPU has emerged as a bottleneck in processing. To address this, we evaluated several techniques, with CUDA graphs being a method that combines significant performance improvement with code flexibility and usability. After studying the impacts of CUDA graphs on Large Language Model workloads, we conclude that it presents a compelling solution for performance optimization in the face of rapid GPU improvement and we use it extensively in the Fireworks Generative AI Platform.
부록 / Appendix
PyTorch 2.0의 torch.compile() 내의 CUDA 그래프 / CUDA Graphs in PyTorch 2.0’s torch.compile
CUDA 그래프를 적용하는 것은 C++로 전체 모델을 다시 작성하는 것보다 쉽지만 여전히 많은 주의를 기울여야 합니다. PyTorch 2.0의 새로운 컴파일 기법(torch.compile())은 장기적으로 이 프로세스를 단순화하고 자동화하는 것을 목표로 합니다. mode='reduce-overhead'로 호출하면, torch.compile()는 추출한 PyTorch 연산 그래프에 CUDA 그래프를 적용하려고 시도합니다. 오늘날 이 기술은 소규모 프로그램이나 컴퓨터 비전 모델들에서 잘 동작합니다. 이 글에서 사용한, 기준이 되는 Llama 코드(이하 레퍼런스 LLama 코드; reference Llama code)에 이 기법을 적용하는데 다음과 같은 문제들이 발생했습니다:
While applying CUDA graphs is easier than rewriting an entire model in C++, it still requires a lot of care. New compilation techniques in PyTorch 2.0 (
torch.compile) aim to simplify and automate this process in the long run. When invoked withmode=’reduce-overhead’,torch.compiletries to apply CUDA graphs to the extracted graphs of PyTorch operations. Today, this technique works well on smaller programs or computer vision models. We ran into issues applying it to the reference Llama code used in this post:
- 그래프 캡처가
torch.inference_mode어노테이션에서는 실패했지만,torch.no_grad로 대체하면 잘 동작했습니다. (하지만 기록해둔 모든 연산(bookkeeping)을 최적화하지는 않았습니다)
- Graph capture failed with
torch.inference_modeannotations, but worked when replaced bytorch.no_grad(which, however, doesn’t optimize away all bookkeeping)
- 레퍼런스 LLama 코드는 fairscale의 명시적인 분산처리 연산을 통해 텐서 병렬 처리를 사용합니다. 이는 그래프 중단(graph break)을 유발하고 컴파일의 이점이 사라지게 됩니다. 평가를 위해 분산처리 지원을 제거하고, 단일 GPU에서 실행하도록 제한했습니다. 분산 집합(distributed collectives)은 CUDA 그래프 자체에서 지원하고 있습니다.
- The LLaMA reference code uses tensor parallelism via explicit distributed operations in fairscale. They introduce graph breaks and eliminate any benefits from compilation. For evaluation, we removed distributed support, thus limiting applicability to a single GPU. Note that distributed collectives are supported with CUDA graphs on their own.
- LLaMA 코드베이스에서 위치 임베딩(positional embedding)은 복소수(complex number)를 사용하여 계산하는데, 이 임베딩은 PyTorch 2.0.1 안정(stable) 버전부터는 컴파일로 캡처할 수 없습니다. 이에 대한 수정 사항이 포함된 최신 PyTorch 2.1 최신(nightly) 버전으로 전환한 후 캡처에는 성공했지만, 여전히 컴파일된 커널의 품질이 최적이 아닐 수 있다는 경고를 생성합니다.
- Positional embeddings in the LLaMA codebase are computed using complex numbers. As of stable PyTorch 2.0.1, they can’t be captured by compilation. After switching to the latest PyTorch 2.1 nightly, which includes the fix, the capture succeeds but torchinductor still generates warnings about the quality of compiled kernels potentially being not optimal.
- 레퍼런스 LLaMA 코드베이스 외에도, PagedAttention과 같은 커스텀 연산을
torch.compile()에서 캡처할 수 있도록 추가적인 처리가 필요합니다.
- Beyond the LLaMA reference codebase, custom operations like PagedAttention require additional handling to be capturable by
torch.compile.
위의 변경 사항을 저장소에 적용한 후(전체 변경 사항 참조), LLaMA-7B 모델을 분산 처리하지 않는(non-distributed setup) 설정에서 torch.compile()을 성공적으로 실행할 수 있었습니다. A100에서의 추론 속도는 배치 크기 1의 경우 초당 69 토큰으로, 직접 CUDA 그래프를 적용했을 때와 정확히 일치했습니다. 프로파일러를 기반으로 살펴보면, 전체 생성 단계가 하나의 CUDA 그래프 호출로 감싸져있습니다. 흥미롭게도, TorchInductor에서 몇 가지 융합(fusion)은 추론 속도를 변화시키지 않는 것 같습니다. torch.compile()은 분산되지 않은 경우에도 비슷한 성능 이점을 제공하지만, 컴파일을 위한 워밍업 시간이 약 3분 가량 소요되어, 명시적으로 CUDA 그래프를 적용한 경우의 초기화 시간이 1초 미만인 것과 비교됩니다. 또한 backend='cudagraphs'으로 torch.compile()을 호출하여 융합 커널(fused kernel) 생성을 건너뛰고 CUDA 그래프만 적용하도록 해보았지만, 오류가 발생했습니다.
After applying the above changes to the repo (see the full diff), we could run
torch.compilesuccessfully in a non-distributed setup for the LLaMA-7B model. Inference speed matches manual CUDA Graph application exactly at 69 token/s for batch size 1 on A100. Based on the profiler, the entire generation step gets wrapped in a single CUDA graph invocation. Interestingly, a few fusions from torchinductor don’t seem to change inference speed. Thoughtorch.compileprovides similar performance benefits for non-distributed cases, the warm-up time for compilation is about 3 minutes, compared to sub-second initialization time for explicit CUDA graphs. We tried makingtorch.compileskip fused kernel generation and only apply CUDA graphs usingbackend=’cudagraphs’, but it errored out.
향후에는 torch.compile())이 LLM 추론을 위해 사용 가능한 방법이 될 수 있겠지만, 현재로서는 이러한 최적화는 충분히 자동화가 되지 않아 전문 지식이 필요합니다.
torch.compilemay be a viable solution for LLM inference in the future, but for now, these optimizations require specific expertise that is not yet sufficiently automated.