
CUDA Tile 소개
CUDA Tile은 NVIDIA가 최근 CUDA 13.1과 함께 발표한 차세대 GPU 프로그래밍 모델로, 인공지능(AI)과 고성능 컴퓨팅(HPC) 분야에서 필수적인 고성능 커널 개발의 패러다임을 근본적으로 변화시키기 위해 등장했습니다. 이 기술은 단순히 새로운 라이브러리를 추가하는 차원이 아니라, GPU 연산의 기본 단위를 스레드(Thread)에서 데이터 덩어리인 타일(Tile)로 격상시키는 거대한 아키텍처의 전환을 의미합니다.
최근의 GPU 하드웨어는 비약적으로 발전했습니다. NVIDIA의 Hopper나 Blackwell 아키텍처는 텐서 코어(Tensor Core) 와 같은 강력한 전용 가속 유닛을 탑재하고 있으며, 메모리 계층 구조 또한 더욱 깊고 복잡해졌습니다. 하지만 기존의 프로그래밍 방식으로는 이러한 하드웨어의 잠재력을 100% 끌어내기 위해 개발자가 극도로 복잡한 최적화 과정을 수동으로 수행해야만 했습니다. CUDA Tile은 이러한 문제를 해결하기 위해, 하드웨어의 복잡성을 컴파일러와 중간 표현(IR, Intermediate Representation) 레벨에서 추상화(Abstraction)하고, 개발자는 데이터의 흐름과 레이아웃에 집중할 수 있도록 돕는 포괄적인 생태계입니다.

기존 SIMT 모델의 한계와 CUDA Tile의 필요성
전통적인 CUDA 프로그래밍은 SIMT(Single Instruction, Multiple Threads) 모델을 기반으로 합니다. 이 모델에서 개발자는 수천, 수만 개의 스레드를 개별적으로 제어해야 합니다. 예를 들어, 행렬 곱셈을 수행할 때 개발자는 각 스레드가 처리할 데이터의 인덱스를 계산하고(threadIdx, blockIdx), 글로벌 메모리에서 데이터를 가져와 공유 메모리(Shared Memory)에 적재한 뒤, 레지스터로 이동시켜 연산을 수행하는 파이프라인 전체를 직접 코딩해야 했습니다. 이는 하드웨어를 극한으로 제어할 수 있다는 장점이 있지만, 코드가 복잡해지고 유지보수가 어려우며, 새로운 GPU 아키텍처가 나올 때마다 코드를 다시 최적화해야 하는 '이식성(Portability)' 문제를 야기했습니다.
반면, CUDA Tile 모델은 접근 방식이 전혀 다릅니다. 이 모델에서는 연산의 최소 단위가 스칼라(숫자 하나)가 아니라 **타일(다차원 데이터 블록)**입니다. 개발자는 "스레드 0번이 A[0]를 로드한다"고 지시하는 대신, "128x128 크기의 타일 A를 로드하여 타일 B와 곱한다"라고 선언적으로 명시합니다. 구체적으로 어떤 스레드가 데이터를 나르고, 어떻게 텐서 코어에 데이터를 공급할지는 CUDA Tile 컴파일러가 담당합니다. 이를 통해 개발자는 하드웨어 세부 사항에 대한 깊은 지식 없이도 텐서 코어와 같은 가속기를 최대한 활용하는 고성능 커널을 작성할 수 있게 됩니다.
| 구분 | 기존 SIMT 모델 (Traditional CUDA) | CUDA Tile 모델 (CUDA Tile IR) |
|---|---|---|
| 실행 단위 | 스레드 (Thread):<br />스레드 하나하나가 실행의 주체 |
타일 (Tile):<br />일정 크기의 데이터 블록이 연산의 기본 단위 |
| 제어 방식 | 수동 제어:threadIdx, blockIdx 등을 사용해 개발자가 병렬 처리를 직접 계산하고 제어 |
추상화된 제어:<br />타일 간의 데이터 흐름과 연산만 정의하며, 구체적인 스레드 매핑은 컴파일러가 담당 |
| 메모리 관리 | 수동 파이프라인:<br />글로벌 메모리 → 공유 메모리 → 레지스터로의 데이터 이동을 개발자가 직접 코딩 |
구조적 지원/자동화:<br />메모리 계층 간 이동 및 Tensor Core 활용이 구조적으로 지원되어 최적화가 용이 |
| 장단점 | 하드웨어를 극한까지 제어할 수 있으나, 코드 작성이 어렵고 유지보수가 까다로움 | 하드웨어 세부 사항을 몰라도 고성능 커널 작성이 가능하며, 최신 GPU 기능 활용이 쉬움 |
CUDA Tile 소개 영상
다음은 CUDA 아키텍트 Stephen Jones가 CUDA Tile에 대해 소개하는 영상입니다:

이번 PyTorch 2025의 'The Future Is Tiled' 세션의 발표 영상 또한 함께 참고해주세요:

CUDA Tile 생태계
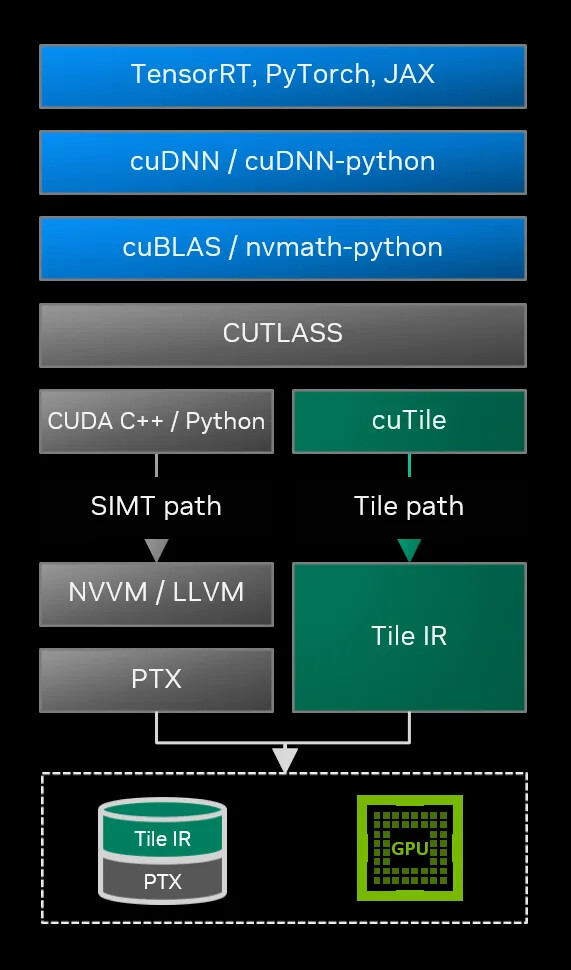
CUDA Tile 생태계는 크게 세 가지 핵심 기둥으로 구성되어 있습니다. 컴파일러 인프라의 핵심인 CUDA Tile IR, 개발자 친화적인 Python 인터페이스인 cuTile Python, 그리고 실전 예제와 대규모 언어 모델(LLM) 통합을 지원하는 TileGym이 바로 그것입니다.
즉, CUDA Tile은 단일 도구가 아니며, 개발자가 마주하는 상위 레벨의 cuTile Python 라이브러리와 하위 레벨의 Tile IR(Intermediate Representation)이 연결된 유기적인 생태계입니다. 이제 cuTile Python과 Tile IR, 그리고 이를 잘 활용할 수 있도록 하는 TileGym을 하나씩 살펴보겠습니다.
개발자가 직접 접하는 cuTile Python
cuTile Python은 NVIDIA GPU에서 타일(Tile) 기반 프로그래밍 모델을 사용하여 병렬 커널을 작성할 수 있게 해주는 Python 기반의 고수준 인터페이스입니다. 개발자는 cuTile Python을 사용하여 C++ 템플릿 메타프로그래밍의 난해함 없이, 친숙하고 유연한 Python 문법을 사용하여 고성능 CUDA Tile 커널을 정의하고 최적화할 수 있습니다.
Numba 등과 같은 기존의 Python 기반 GPU 프로그래밍이 주로 스레드 단위의 SIMT 모델을 따르거나 제한적인 기능만을 제공했던 것과 달리, cuTile Python은 최신 CUDA Tile IR (Intermediate Representation) 사양을 기반으로 구축되었습니다. Python 코드로 작성된 커널은 컴파일러에 의해 자동으로 최적화된 Tile IR로 변환되며, 이를 통해 Tensor Core와 같은 최신 하드웨어 가속 기능을 손쉽게 활용할 수 있습니다.
따라서 개발자가 Python으로 알고리즘에 대해서 기술하면, cuTile은 이를 최적화된 Tile IR로 변환하고, 최종적으로는 C++로 작성된 커널과 동일하거나 더 뛰어난 성능을 내는 바이너리를 생성합니다. 즉, 복잡한 C++/CUDA 코드를 작성하지 않고도, Tile IR 사양을 기반으로 한 고성능 커널을 Python 코드로 쉽게(Seamless)하게 표현할 수 있습니다. 이는 PyTorch나 JAX와 같은 딥러닝 프레임워크와 결합하여 커스텀 연산자를 개발할 때 강력한 시너지를 발휘합니다.
특히 AI 연구자나 데이터 과학자들이 익숙한 Python 환경(NumPy, CuPy 등)과 원활하게 통합되어, 연구용 코드의 프로토타이핑부터 고성능 커널 배포까지의 간극을 획기적으로 줄여줍니다.
cuTile Python의 주요 특징
Python-Native 타일 프로그래밍: 개발자는 Python의 데코레이터(@ct.kernel)와 함수형 API를 사용하여 GPU 커널을 정의할 수 있습니다. 즉, tile, shape, dtype과 같은 Tile IR의 타입(Type) 시스템이 Python 객체로 매핑되며, load, store, mma (Matrix Multiply-Accumulate)와 같은 고수준 연산자를 제공하여 복잡한 메모리 계층 제어를 단순화합니다.
자동화된 컴파일 파이프라인: cuTile Python은 런타임에 Python AST(Abstract Syntax Tree)나 함수 호출을 분석하여 CUDA Tile IR을 생성합니다. 생성된 IR은 백엔드 컴파일러(tileiras)를 통해 최적화된 바이너리(cubin)로 변환되어 실행됩니다.
생태계 통합 (NumPy/CuPy): 개발자는 입출력 데이터로 CuPy 배열이나 NumPy 배열을 자연스럽게 사용할 수 있습니다. 이렇게 사용한 배열들은 커널 실행 시 그리드(Grid) 설정이나 스트림(Stream) 관리도 Python 코드 내에서 직관적으로 처리됩니다.
cuTile Python 사용 예시: Vector Add Kernel
다음은 cuTile Python을 사용하여 두 벡터를 더하는 간단한 커널 예제입니다.
import cuda.tile as ct
import cupy
import numpy as np
TILE_SIZE = 16
# 1. 커널 정의 (Decorator 사용)
@ct.kernel
def vector_add_kernel(a, b, result):
# 현재 블록의 ID 가져오기
block_id = ct.bid(0)
# 2. 타일 단위로 데이터 로드
# (Global Memory -> Register/Shared Memory 처리는 자동화됨)
a_tile = ct.load(a, index=(block_id,), shape=(TILE_SIZE,))
b_tile = ct.load(b, index=(block_id,), shape=(TILE_SIZE,))
# 3. 타일 연산 수행
result_tile = a_tile + b_tile
# 4. 결과 저장
ct.store(result, index=(block_id,), tile=result_tile)
# 데이터 준비 (CuPy 사용)
a = cupy.random.uniform(-5, 5, 128)
b = cupy.random.uniform(-5, 5, 128)
result = cupy.zeros_like(a)
# 커널 실행 (Launch)
# Grid 설정: (데이터 크기 / 타일 크기, 1, 1)
grid = (ct.cdiv(a.shape[0], TILE_SIZE), 1, 1)
ct.launch(cupy.cuda.get_current_stream(), grid, vector_add_kernel, (a, b, result))
# 결과 검증
print("Execution Completed")
위 예시 코드에서 볼 수 있듯이, 루프나 스레드 인덱싱 없이 ct.load, +, ct.store 등 직관적인 타일 연산만으로 GPU 커널을 작성할 수 있습니다.
cuTile Python 더 알아보기
cuTile Python과 관련한 더 자세한 내용은 다음 영상 및 블로그, 개발자 문서, GitHub 저장소 등을 참고해주세요:


https://github.com/NVIDIA/cutile-python
Tile 생태계의 중심, CUDA Tile IR
CUDA Tile IR은 이 생태계의 허리 역할을 하는 컴파일러 인프라입니다. 이는 MLIR(Multi-Level Intermediate Representation) 을 기반으로 구축되었으며, 타일 기반 연산을 표현하기 위한 가상 명령어 세트(Virtual Instruction Set) 역할을 합니다.
CUDA Tile IR 프로젝트는 크게 Dialect(방언), 직렬화 도구, 테스트 스위트로 구성됩니다. CUDA Tile Dialect는 타일(Tile)을 프로그래밍 언어의 '일급 객체(First-class citizen)'로 정의합니다. 즉, tile<128x128xf16>과 같이 타일의 크기, 차원, 데이터 타입을 명확하게 타입 시스템으로 보장합니다. 이를 통해 컴파일러는 데이터의 레이아웃과 흐름을 명확히 이해하고, 이를 타겟 GPU(예: sm_90, sm_100)에 최적화된 기계어(SASS/PTX)로 변환할 수 있습니다.
또한, CUDA Tile IR은 바이트코드(Bytecode) 형태로 직렬화(Serialization)될 수 있습니다. 이렇게 생성된 바이트코드는 런타임에 드라이버를 통해 JIT(Just-In-Time) 컴파일되거나, 미리 컴파일(AoT)되어 배포될 수 있습니다. 이는 다양한 언어(C++, Python 등) 프론트엔드가 공통적으로 타겟팅할 수 있는 표준화된 중간 계층을 제공한다는 점에서 매우 중요합니다.
Tile IR 예시 코드 (MLIR)
CUDA Tile IR로 작성된 코드는 .mlir 확장자를 가지며, 데이터의 형상과 타입을 명시적으로 드러냅니다. 아래 예시는 포인터를 타일로 변환하여 데이터를 로드하는 간단한 예시를 설명한 것입니다.
cuda_tile.module @example_module {
entry @example_kernel(%data_ptr : tile<ptr<f32>>) {
// 1. 인덱스 생성
%offsets = iota : tile<128xi32>
// 2. 포인터 형상 변환 (Reshape & Broadcast)
%reshaped = reshape %data_ptr : tile<ptr<f32>> -> tile<1xptr<f32>>
%broadcasted = broadcast %reshaped : tile<1xptr<f32>> -> tile<128xptr<f32>>
// 3. 오프셋 적용 및 데이터 로드
%ptr_tile = offset %broadcasted, %offsets : ...
%data, %token = load_ptr_tko weak %ptr_tile : ...
// ... 연산 및 저장
return
}
}
위 코드의 흐름을 보면, 메모리 주소조차도 tile<ptr<f32>>라는 타일 타입으로 취급됩니다. 또한, reshape, broadcast, offset과 같은 고수준 연산자를 통해 데이터의 구조를 정의하면, 컴파일러가 이를 효율적인 메모리 접근 명령어로 변환합니다. 이를 통해 개발자는 복잡한 포인터 산술 연산 대신 논리적인 데이터 구조 변환에 집중할 수 있습니다.
MLIR 코드 컴파일 및 실행 워크플로우
이렇게 작성/변환된 MLIR 코드는 cuda-tile-translate 도구를 통해 실행 가능한 형태로 변환할 수 있습니다:
- 변환:
.mlir파일을.tilebc(바이트코드) 파일로 변환합니다. - 컴파일:
tileiras도구를 사용하여 바이트코드를 특정 GPU 아키텍처(예:sm_90)를 위한.cubin바이너리로 컴파일합니다. - 실행: 호스트 C++ 애플리케이션에서 CUDA Driver API(
cuModuleLoad,cuLaunchKernel)를 사용하여 커널을 로드하고 실행합니다.
Tile IR 더 알아보기
CUDA Tile IR과 관련한 더 자세한 내용은 다음 블로그 및 개발자 문서, GitHub 저장소 등을 참고해주세요:
https://github.com/NVIDIA/cuda-tile
Tile 생태계 진입을 돕는 TileGym

새로운 프로그래밍 모델을 익히는 것은 언제나 어렵습니다. TileGym은 이러한 진입 장벽을 낮추기 위해 제공되는 실전 예제 및 커널 라이브러리 저장소입니다. 하지만 TileGym은 단순한 "Hello World" 수준의 예제를 넘어섭니다.
TileGym에는 Llama 3나 DeepSeek-V2와 같은 최신 거대 언어 모델(LLM)에 필요한 핵심 연산(예: Attention, GEMM 등)을 CUDA Tile로 구현한 사례가 포함되어 있습니다. 개발자들은 TileGym의 코드를 참고하여 자신의 프로젝트에 맞는 최적화된 커널을 빠르게 구현할 수 있으며, 실제 상용 모델에 적용 가능한 수준의 성능 튜닝 기법을 학습할 수 있습니다. 이는 이론적인 명세서가 아닌, 실제로 작동하는 "살아있는 교과서" 역할을 합니다.
TileGym 저장소 구성
TileGym은 크게 교육용 예제, 실전 커널 구현체, LLM 통합 가이드라는 세 가지 핵심 가치를 제공합니다:
풍부한 커널 예제 (Rich Collection of Kernels): 기본적인 벡터 연산부터 시작하여, 실제 딥러닝에서 사용되는 복잡한 연산자(Operator)까지 다양한 수준의 예제를 포함하고 있습니다. 모든 예제는 cuTile Python을 사용하여 작성되어 있어, Python 개발자가 쉽게 코드를 읽고 이해할 수 있습니다.
최신 LLM 아키텍처 지원 (End-to-End LLM Integration): 단순한 단위 연산을 넘어, Llama 3.1-8B 및 DeepSeek-V2 등과 같은 실제 모델 추론 파이프라인에 타일 커널이 어떻게 통합되는지 보여줍니다. 즉, PyTorch 기반의 Hugging Face Transformers 라이브러리와 연동하여, 기존 모델의 특정 레이어를 TileGym 커널로 교체하여 가속하는 방법을 제시합니다.
성능 벤치마킹 (Performance Benchmarking): TileGym에는 작성한 커널의 효율성을 검증할 수 있는 마이크로 벤치마크(Micro-benchmarks) 도구들도 함께 포함되어 있습니다. 이를 통해 개발자는 자신이 작성한 타일 커널이 실제 하드웨어에서 얼마나 효율적으로 동작하는지 정량적으로 측정할 수 있습니다.
TileGym 더 알아보기
TileGym과 관련한 더 자세한 내용은 다음 GitHub 저장소를 참고해주세요:
https://github.com/NVIDIA/TileGym
 CUDA Tile 공식 홈페이지
CUDA Tile 공식 홈페이지
더 읽어보기 (영문)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()