DataFlow 소개
DataFlow는 LLM(Large Language Model)의 성능을 극대화하기 위해 설계된 데이터 중심 AI(Data-Centric AI) 시스템입니다. 이 프레임워크는 PDF, 일반 텍스트, 저품질의 Q&A 등 노이즈가 많은 원시 데이터를 파싱, 생성, 처리, 평가하여 고품질의 데이터셋으로 변환하는 과정을 자동화합니다. 단순한 데이터 필터링 도구를 넘어, 사전 학습(Pre-training), 지도 미세 조정(SFT), 강화 학습(RL) 및 RAG(검색 증강 생성)에 필요한 맞춤형 데이터를 체계적으로 생산할 수 있는 통합 솔루션입니다.
최근 AI 연구의 흐름은 모델 구조의 개선 못지않게 '데이터의 품질'을 중시하는 방향으로 이동하고 있습니다. 하지만 특정 도메인(의료, 금융, 법률 등)에 특화된 고품질 데이터를 확보하는 것은 매우 비용이 많이 들고 어렵습니다. DataFlow는 이러한 문제를 해결하기 위해 연산자(Operator), 파이프라인(Pipeline), 에이전트(Agent) 라는 모듈형 아키텍처를 도입했습니다. 이를 통해 사용자는 레고 블록을 조립하듯 데이터 처리 과정을 설계하거나, 지능형 에이전트를 통해 자동으로 최적의 데이터 파이프라인을 구축할 수 있습니다.

특히 DataFlow는 데이터 품질 향상이 실제 모델 성능 개선으로 이어짐을 실증적으로 입증했습니다. Qwen2.5와 같은 최신 모델을 DataFlow로 정제된 데이터로 학습했을 때, 수학(Math), 코드(Code), 지식(Knowledge) 벤치마크에서 무작위 샘플링이나 단순 필터링 방식 대비 유의미한 성능 향상을 보였습니다. 이는 LLM 개발자들에게 데이터 준비 과정의 효율성과 모델 성능을 동시에 잡을 수 있는 강력한 도구를 제공합니다.
기존의 데이터 준비 방식은 주로 무작위 샘플링(Random Sampling)이나 간단한 규칙 기반 필터링에 의존했습니다. 예를 들어, Alpaca나 WizardLM 데이터셋을 구축할 때 단순한 휴리스틱이나 LLM의 생성 결과물을 그대로 사용하는 경우가 많았습니다. 반면, DataFlow는 다음과 같은 차별점을 가집니다:
- 정교한 필터링 및 합성: 단순 생성이 아니라 '생성(Generator) -> 정제(Refiner) -> 평가(Evaluator)'로 이어지는 다단계 파이프라인을 통해 데이터의 품질을 엄격하게 관리합니다.
- 모듈화된 설계: 고정된 스크립트가 아닌 80개 이상의 일반 연산자와 40개 이상의 도메인 특화 연산자를 조합하여 유연하게 워크플로우를 구성할 수 있습니다.
- 지능형 에이전트: 사용자가 일일이 파이프라인을 짜지 않아도, DataFlow Agent가 작업 목표에 맞춰 필요한 연산자를 자동으로 조합하고 실행합니다.
DataFlow의 핵심 구성 요소 및 기능
DataFlow 시스템은 크게 연산자(Operators), 파이프라인(Pipelines), 그리고 에이전트(Agent)로 구성되어 있습니다.
연산자 (Operators): 데이터 처리의 기본 단위

DataFlow는 데이터 처리를 위한 최소 단위인 '연산자'를 모듈화하여 제공합니다. 입력된 정형 데이터(JSON, CSV 등)를 지능적으로 처리하여 고품질의 결과물을 출력합니다.
-
일반 연산자(Generic Operators): 텍스트 평가, 처리, 합성 등 범용적인 기능을 수행하는 80개 이상의 연산자를 제공합니다.
-
도메인 특화 연산자(Domain-Specific Operators): 40개 이상의 의료, 금융, 법률 등 특정 분야에 특화된 처리를 담당하는 연산자를 제공합니다.
-
평가 연산자(Evaluation Operators): 데이터의 품질을 6가지 차원에서 종합적으로 평가하는 연산자를 20개 이상 제공합니다.
연산자와 관련한 상세한 내용은 다음 Operator 문서를 참고해주세요.
https://opendcai.github.io/DataFlow-Doc/en/guide/text_evaluation_operators/
파이프라인 (Pipelines): 목적별 워크플로우
파이프라인은 연산자들을 체계적으로 연결하여 특정 목적을 달성하는 워크플로우입니다. DataFlow는 사용자가 즉시 활용할 수 있는 사전 정의된 파이프라인부터, 연산자를 자유롭게 조합하는 유연한 파이프라인, 그리고 에이전트가 자동으로 설계해주는 지능형 파이프라인까지 3가지 수준의 워크플로우를 제공합니다.
1. 즉시 사용 가능한 파이프라인(Ready-to-Use Pipelins): DataFlow는 복잡한 설정 없이도 즉시 사용(Ready-to-Use)하여 특정 목적의 데이터를 생산할 수 있도록 아래의 5가지 핵심 파이프라인을 제공하고 있습니다:
-
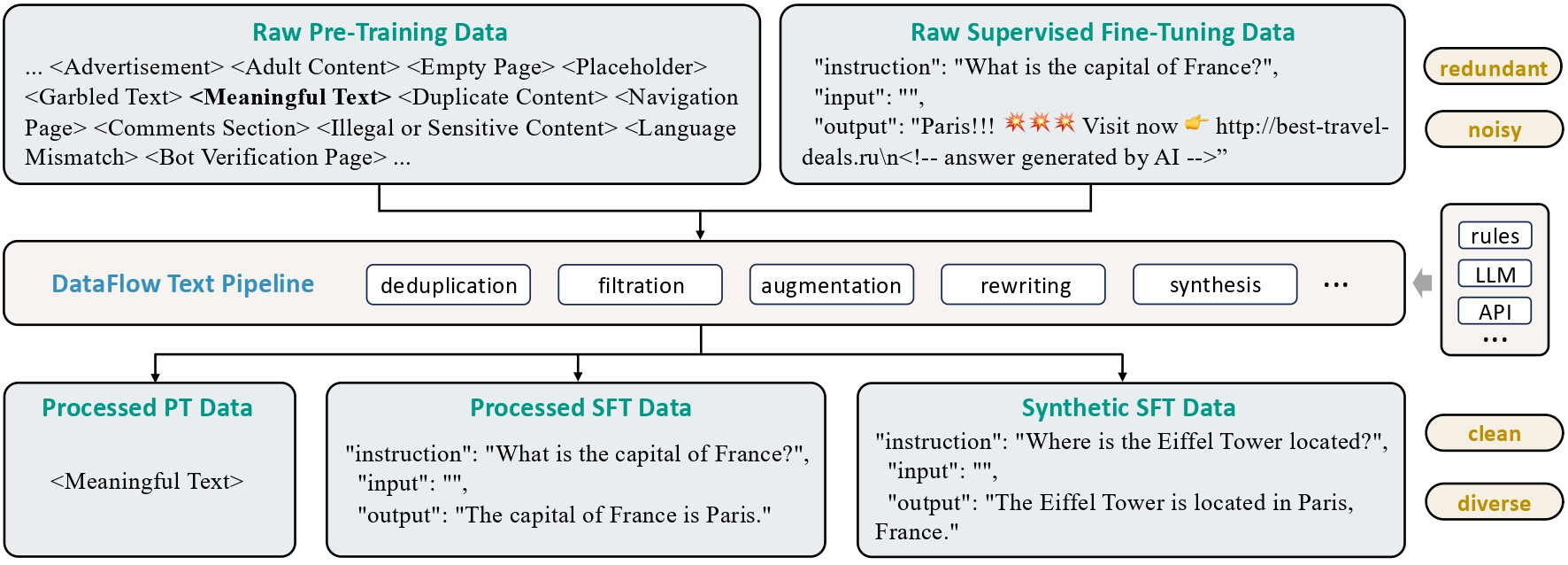
 텍스트 파이프라인(Text Pipeline): 텍스트 파이프라인은 대규모 일반 텍스트 데이터(주로 인터넷 크롤링 데이터)에서 SFT(지도 미세 조정) 및 RL(강화 학습) 훈련에 적합한 질문-답변(Q&A) 쌍을 발굴합니다.
텍스트 파이프라인(Text Pipeline): 텍스트 파이프라인은 대규모 일반 텍스트 데이터(주로 인터넷 크롤링 데이터)에서 SFT(지도 미세 조정) 및 RL(강화 학습) 훈련에 적합한 질문-답변(Q&A) 쌍을 발굴합니다.
-
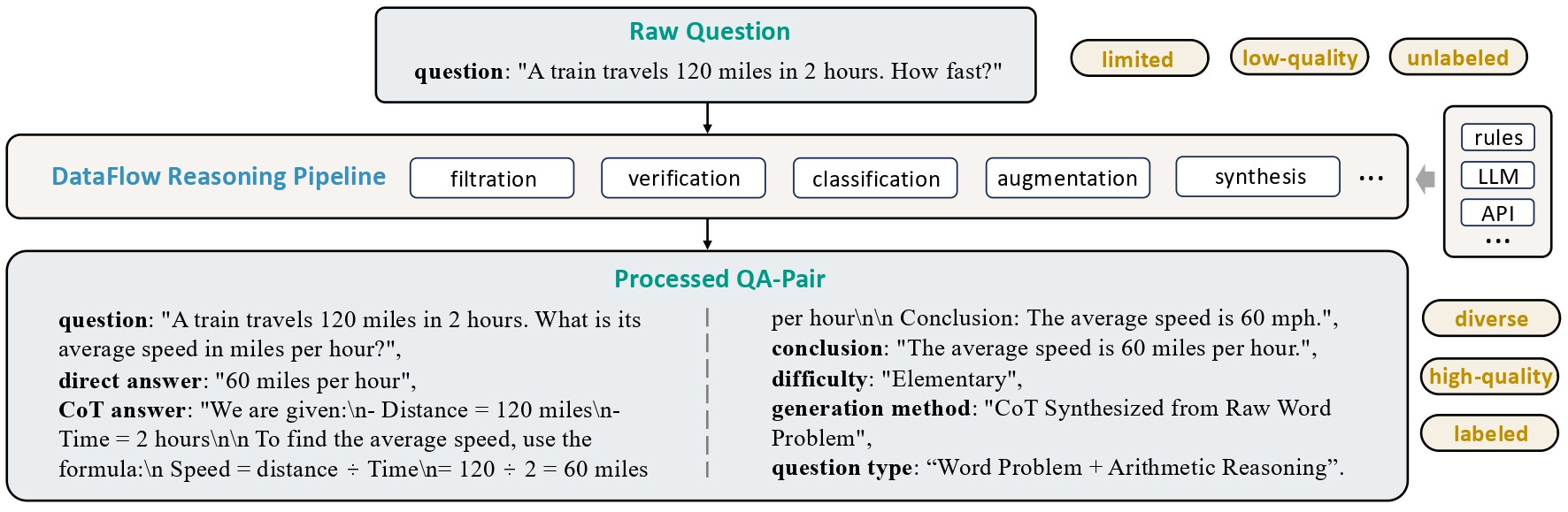
 추론 파이프라인(Reasoning Pipeline): 기존의 질문-답변 쌍을 입력받아 (1) 확장된 사고 사슬(Chain-of-Thought), (2) 카테고리 분류, (3) 난이도 추정 정보를 추가하여 데이터의 추론 품질을 강화합니다.
추론 파이프라인(Reasoning Pipeline): 기존의 질문-답변 쌍을 입력받아 (1) 확장된 사고 사슬(Chain-of-Thought), (2) 카테고리 분류, (3) 난이도 추정 정보를 추가하여 데이터의 추론 품질을 강화합니다.
-
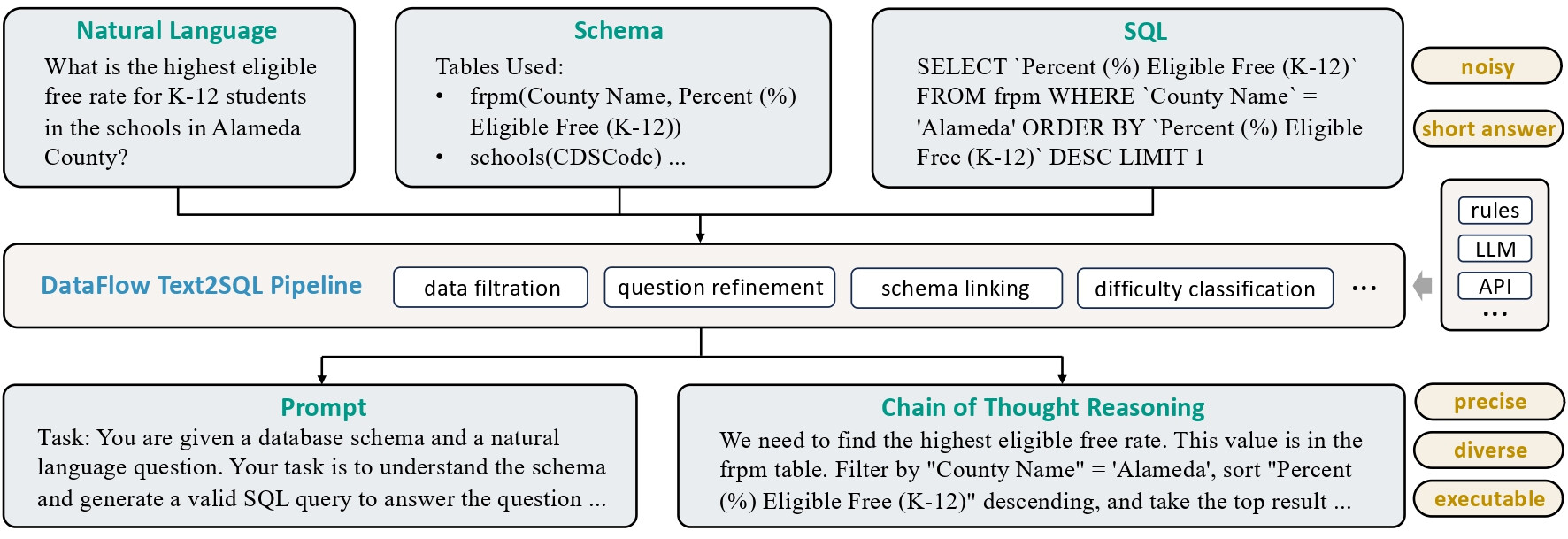
 Text2SQL 파이프라인(Text2SQL Pipeline): 자연어 질문을 SQL 쿼리로 변환합니다. 단순 변환뿐만 아니라 설명(Explanation), 사고 사슬 추론, 그리고 문맥에 맞는 스키마(Contextual Schema) 정보를 함께 생성하여 학습 데이터의 완성도를 높입니다.
Text2SQL 파이프라인(Text2SQL Pipeline): 자연어 질문을 SQL 쿼리로 변환합니다. 단순 변환뿐만 아니라 설명(Explanation), 사고 사슬 추론, 그리고 문맥에 맞는 스키마(Contextual Schema) 정보를 함께 생성하여 학습 데이터의 완성도를 높입니다.
-
 지식 베이스 정제 파이프라인(Knowledge Base Cleaning Pipeline): PDF, Word 문서, 표(Table) 등 정형화되지 않은 소스에서 지식을 추출하고 구조화된 항목으로 정리합니다. 이는 RAG(검색 증강 생성) 시스템이나 QA 데이터 생성에 바로 활용될 수 있습니다.
지식 베이스 정제 파이프라인(Knowledge Base Cleaning Pipeline): PDF, Word 문서, 표(Table) 등 정형화되지 않은 소스에서 지식을 추출하고 구조화된 항목으로 정리합니다. 이는 RAG(검색 증강 생성) 시스템이나 QA 데이터 생성에 바로 활용될 수 있습니다.
-
 에이전트 RAG 파이프라인(Agentic RAG Pipeline): 기존 QA 데이터셋이나 지식 베이스에서 외부 지식이 반드시 필요한 질문을 식별하고 추출합니다. 이는 에이전트 기반 RAG(Agentic RAG) 모델을 훈련시키기 위한 맞춤형 데이터를 생성하는 데 사용됩니다.
에이전트 RAG 파이프라인(Agentic RAG Pipeline): 기존 QA 데이터셋이나 지식 베이스에서 외부 지식이 반드시 필요한 질문을 식별하고 추출합니다. 이는 에이전트 기반 RAG(Agentic RAG) 모델을 훈련시키기 위한 맞춤형 데이터를 생성하는 데 사용됩니다.
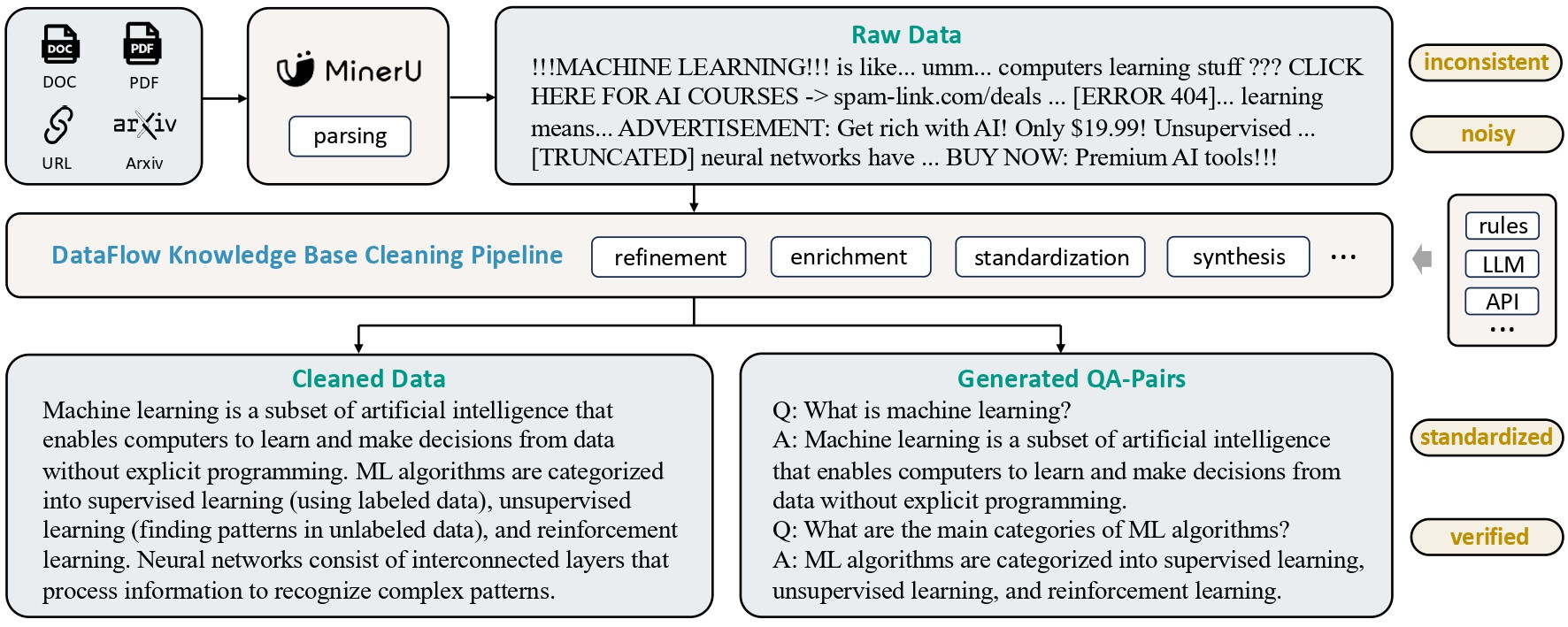

2. 유연한 연산자 파이프라인 (Flexible Operator Pipelines): DataFlow는 사용자가 직접 레고 블록처럼 조립할 수 있는 다양한 연산자를 제공합니다. 연산자는 크게 다음과 같이 분류됩니다. 상세 내용은 DataFlow 공식 문서에서 확인할 수 있습니다.
- Fundamental Operators: 데이터 처리의 기초가 되는 연산자
- Generic Operators: 범용적으로 사용되는 텍스트 처리 및 변환 연산자
- Domain-Specific Operators: 특정 분야(금융, 법률 등)에 특화된 연산자
- Evaluation Operators: 데이터의 품질을 측정하고 평가하는 연산자
3. 에이전트 가이드 파이프라인 (Agent Guided Pipelines): DataFlow-Agent는 사용자가 일일이 파이프라인을 설계하지 않아도 되는 지능형 어시스턴트입니다. 에이전트는 사용자가 제시한 작업 목표를 기반으로 데이터 분석(Data Analysis) 을 수행하고, 필요한 맞춤형 연산자(Operators)를 작성하며, 이를 자동으로 연결하여 파이프라인을 조립(Orchestrate) 합니다.
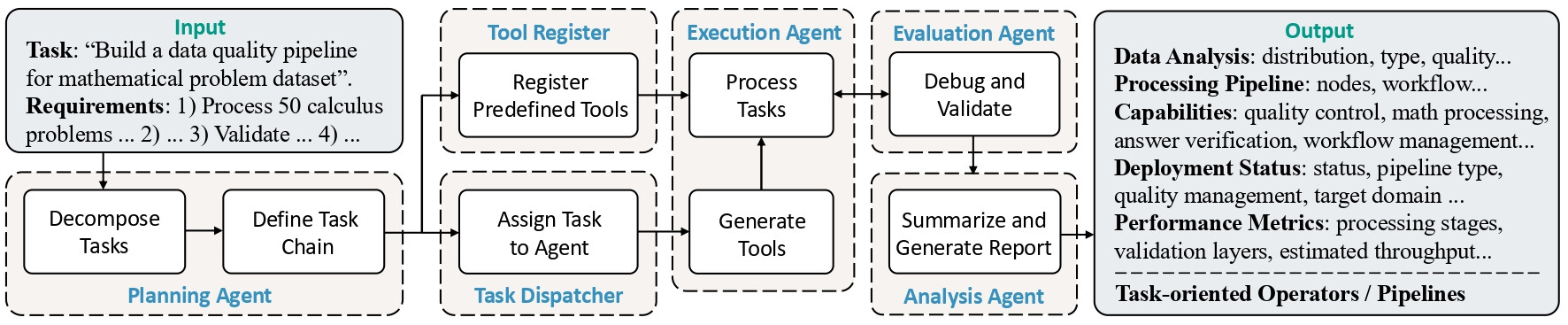
이러한 과정을 통해 에이전트 가이드 파이프라인은 데이터 준비 과정의 진입 장벽을 획기적으로 낮춥니다.
DataFlow-Instruct-10k 데이터셋
DataFlow 프레임워크의 성능을 입증하기 위해 생성된 고품질 지시(Instruction) 튜닝 데이터셋입니다. 총 10,000개의 샘플로 구성되어 있으며, 각 도메인별로 DataFlow 파이프라인을 거쳐 생성 및 필터링되었습니다.
- Math (3k): MATH 데이터셋을 시드로 하여 추론 파이프라인을 통해 생성된 고난도 수학 문제 및 CoT 솔루션.
- Code (2k): LingoCoder를 기반으로 API 파이프라인을 통해 생성된 코드 지시 데이터.
- Text (5k): 일반적인 대화 및 지시 수행 데이터로, 생성 후 엄격한 품질 필터링을 통과한 데이터.
DataFlow 설치 및 사용법
DataFlow는 Python 3.10 이상 환경에서 pip를 통해 다음과 같이 쉽게 설치할 수 있습니다:
# (선택) conda를 사용한 가상 환경 생성
conda create -n dataflow python=3.10
conda activate dataflow
# 기본 설치
pip install open-dataflow
# vLLM을 포함한 GPU 지원 설치
pip install open-dataflow[vllm]
설치 후에는 다음과 같은 명령어로 설치가 잘 수행되었는지 확인할 수 있습니다:
dataflow -v
# DataFlow가 정상 설치되었다면, 다음과 같은 결과가 보여야 합니다:
# open-dataflow codebase version: 1.0.0
# Checking for updates...
# Local version: 1.0.0
# PyPI newest version: 1.0.0
# You are using the latest version: 1.0.0.
pip를 사용한 직접 설치 외, Docker 이미지를 사용하는 방법도 제공합니다. 아래와 같이 미리 빌드된 Docker 이미지를 불러와 사용하거나, 직접 GitHub 저장소의 Dockerfile을 빌드하여 사용할 수 있습니다:
# 빌드된 Docker 이미지 불러오기
docker pull molyheci/dataflow:cu124
# GPU 지원을 포함한 컨테이너 실행
docker run --gpus all -it molyheci/dataflow:cu124
# 컨테이너 내부에서 설치 확인
dataflow -v
라이선스
DataFlow 프로젝트는 Apache-2.0 라이선스로 배포되고 있습니다.
 DataFlow 홈페이지
DataFlow 홈페이지
 DataFlow 기술 문서: DataFlow An LLM-Driven Framework for Unified Data Preparation and Workflow Automation in the Era of Data-Centric AI
DataFlow 기술 문서: DataFlow An LLM-Driven Framework for Unified Data Preparation and Workflow Automation in the Era of Data-Centric AI
PyTorchKR
 의 DataFlow 기술문서 리뷰
의 DataFlow 기술문서 리뷰
 DataFlow 프로젝트 GitHub 저장소
DataFlow 프로젝트 GitHub 저장소
 DataFlow-Instruct-10k 데이터셋
DataFlow-Instruct-10k 데이터셋
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()