안녕하세요, 파이토치 공부를 시작한지 얼마 안된 초보입니다.
multi GPU를 사용해 모델을 학습하려 하는데, 가장 간단한 방법인 DataParallel 사용 시 문제가 있습니다.
GPU들에 모델이 할당 된 후 학습이 진행되지 않고, 특히 GPU 0은 utilization이 0%로 뜹니다. GPU는 GTX 1080Ti 8개입니다.
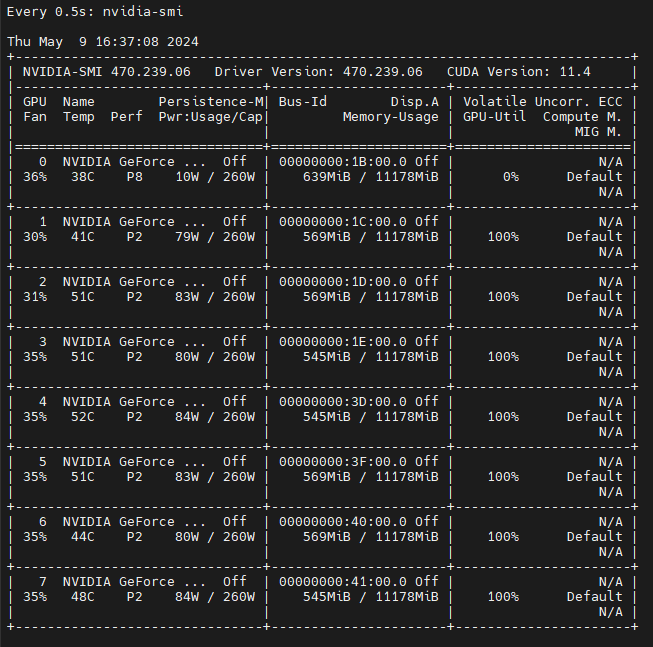
아래는 제가 사용한 예제입니다.
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
class RandomDataset(Dataset):
def __init__(self, size, length):
self.len = length
self.data = torch.randn(length, size)
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
class Model(nn.Module):
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
self.sigmoid = nn.Sigmoid()
def forward(self, input):
return self.sigmoid(self.fc(input))
if __name__ == '__main__':
# Parameters and DataLoaders
input_size = 5
output_size = 1
batch_size = 30
data_size = 100
rand_loader = DataLoader(dataset=RandomDataset(input_size, data_size),
batch_size=batch_size, shuffle=True)
model = Model(input_size, output_size)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
model = nn.DataParallel(model).cuda()
optimizer = optim.SGD(params=model.parameters(), lr=1e-3)
cls_criterion = nn.BCELoss()
for data in rand_loader:
targets = torch.empty(data.size(0)).random_(2).view(-1, 1)
if torch.cuda.is_available():
input = Variable(data.cuda())
with torch.no_grad():
targets = Variable(targets.cuda())
else:
input = Variable(data)
with torch.no_grad():
targets = Variable(targets)
output = model(input)
optimizer.zero_grad()
loss = cls_criterion(output, targets)
loss.backward()
optimizer.step()
실행하면 다음과 같이 GPU들이 인식되고 이후 아무런 출력이 없습니다.
python test.py
Let's use 8 GPUs!
아래는 제 torch 버전입니다.
pip show torch
Name: torch
Version: 2.2.2+cu118
DataParallel을 사용하기 위해 추가로 설정해야 할 것이 있나요?