Dia 소개
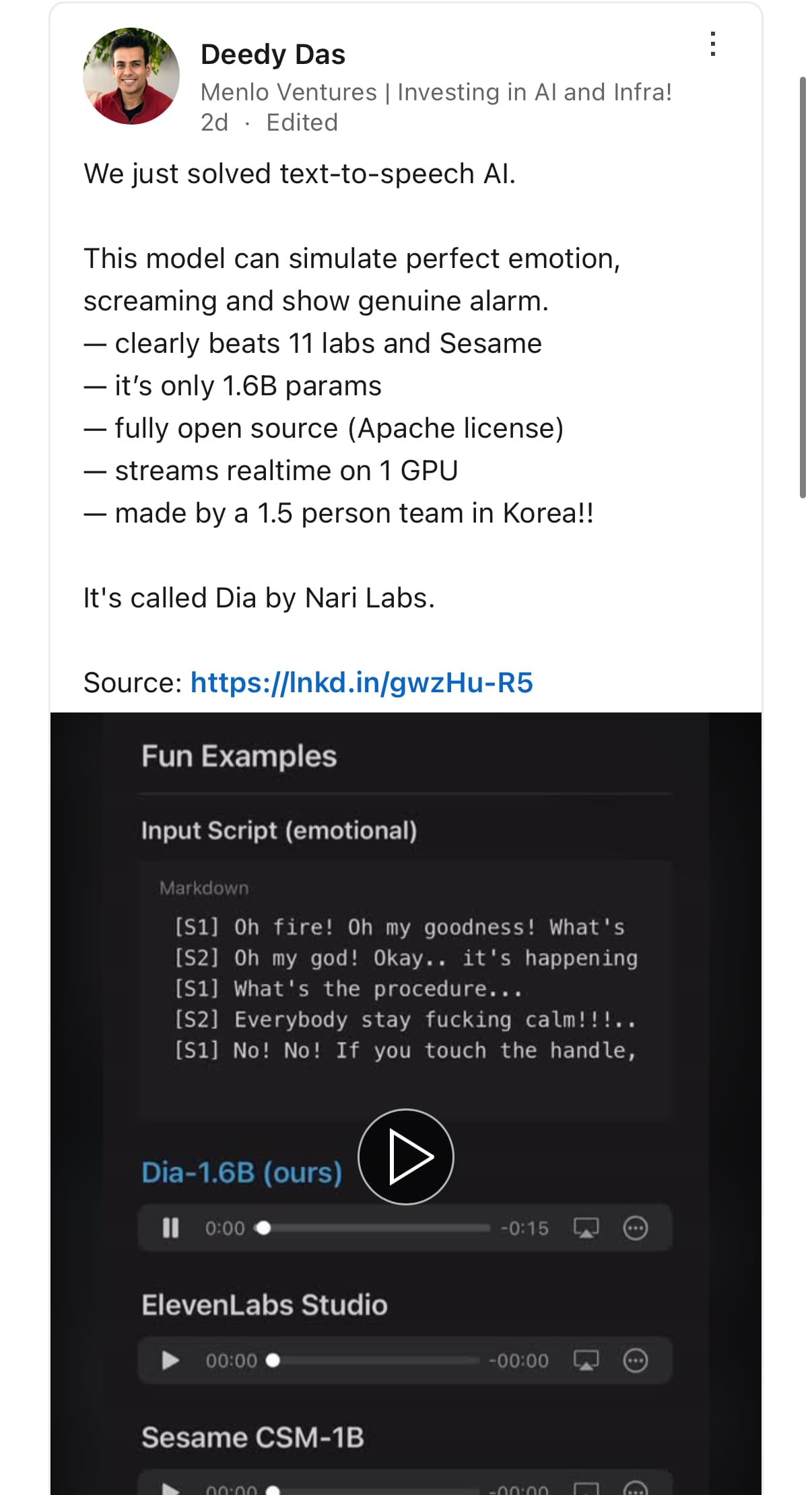
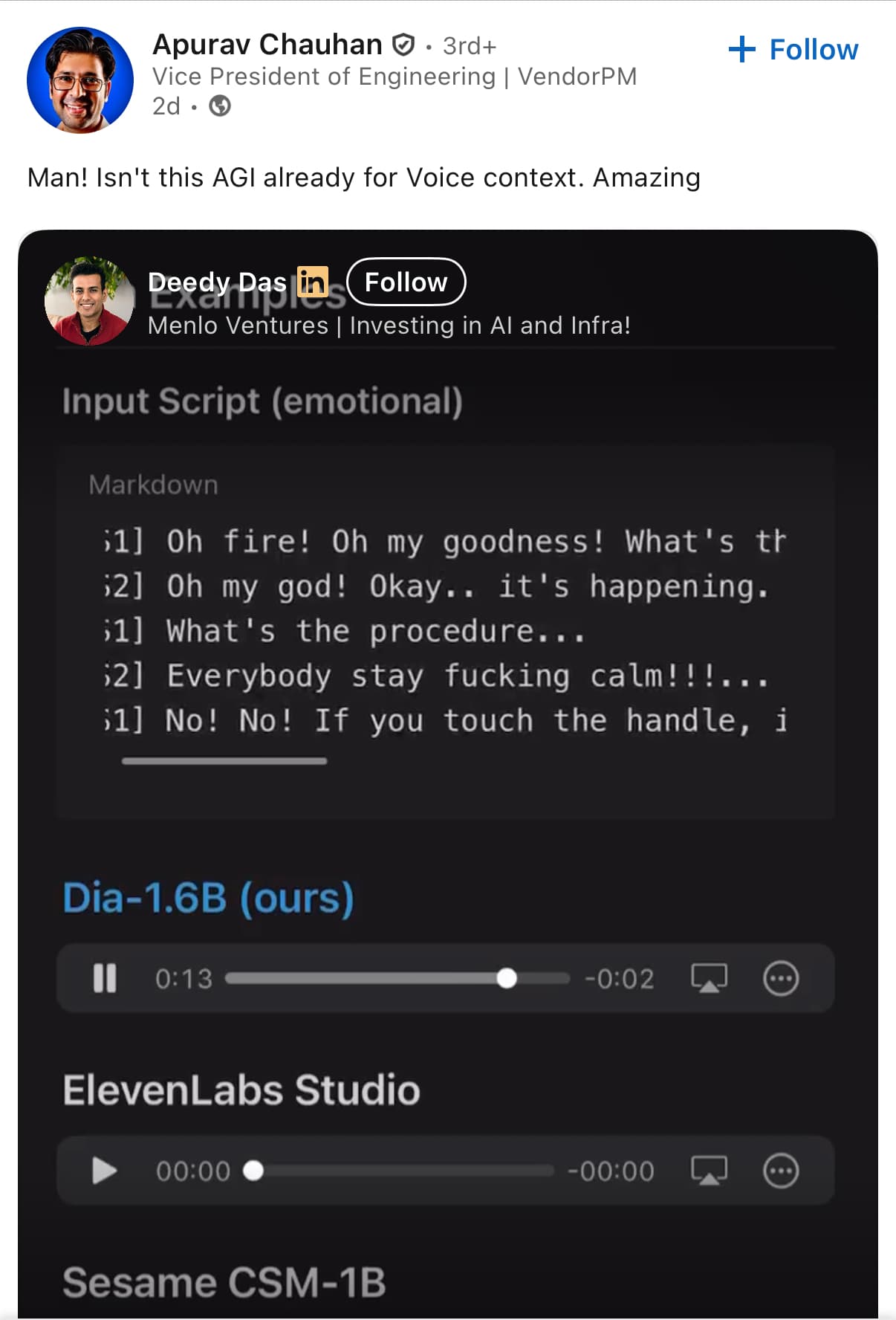
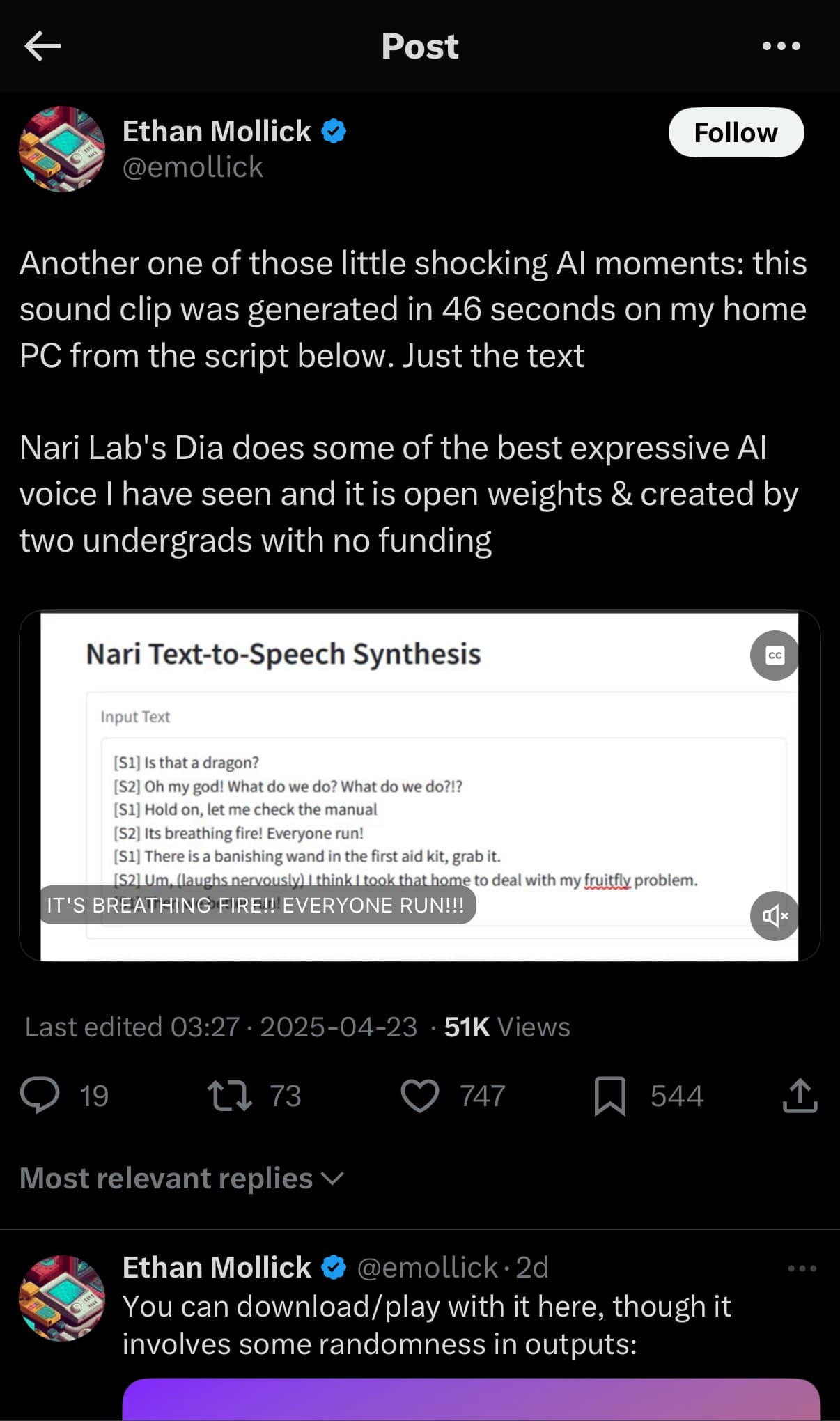
Nari Labs에서 공개한 Dia는 1.6B 파라미터를 가진 오픈소스 텍스트-투-스피치(TTS) 모델로, 감정 표현과 비언어적 요소까지 자연스럽게 생성할 수 있습니다. ElevenLabs나 OpenAI의 상용 모델과 비교해도 손색이 없으며, 오픈소스로 공개되어 누구나 자유롭게 사용할 수 있습니다. 특히, 음성 클로닝 기능과 다양한 감정 표현이 가능하여 콘텐츠 제작자나 개발자에게 유용한 도구가 될 것으로 보입니다.
Dia는 한국의 두 대학생이 설립한 Nari Labs에서 개발한 오픈소스 TTS 모델입니다. 1.6B 파라미터를 기반으로 하며, 텍스트 입력만으로도 감정이 풍부한 대화를 자연스럽게 생성할 수 있습니다. 또한, 웃음, 기침, 한숨 등 비언어적 요소도 표현할 수 있어 실제 사람의 대화와 유사한 음성을 생성합니다.
Dia는 PyTorch 2.0 이상과 CUDA 12.6 환경에서 작동하며, 약 10GB의 VRAM을 요구합니다. 현재는 GPU에서만 실행 가능하지만, 향후 CPU 지원과 양자화된 버전도 계획 중입니다. 모델은 Hugging Face와 GitHub에서 제공되며, Hugging Face Space의 데모를 통해 웹에서 직접 체험할 수 있습니다.
Dia의 개발에는 Google TPU Research Cloud의 지원이 있었으며, SoundStorm, Parakeet, Descript Audio Codec 등의 기존 연구를 참고하여 개발되었습니다.
특히, Dia는 상용 모델인 ElevenLabs Studio, Google의 NotebookLM, Sesame CSM-1B 등과 비교해도 뛰어난 성능을 보입니다. 특히, 감정 표현과 비언어적 요소의 자연스러운 처리에서 우수한 결과를 보여주며, 음성 클로닝 기능도 탁월합니다. 반면, 일부 상용 모델은 특정 음성에 최적화되어 있어 다양한 음성을 생성하는 데 한계가 있을 수 있습니다. Dia 모델과 다른 모델들과의 TTS 결과 비교는 Demo Page에서 확인할 수 있습니다:
Dia의 주요 기능
-
다중 화자 지원: 텍스트에
[S1],[S2]등의 태그를 사용하여 여러 화자의 대화를 생성할 수 있습니다. -
비언어적 요소 표현:
(laughs),(coughs),(sighs)등의 태그를 통해 웃음, 기침, 한숨 등 비언어적 요소를 표현할 수 있습니다.(laughs), (clears throat), (sighs), (gasps), (coughs), (singing), (sings), (mumbles), (beep), (groans), (sniffs), (claps), (screams), (inhales), (exhales), (applause), (burps), (humming), (sneezes), (chuckle), (whistles)
-
음성 클로닝: 사용자가 제공한 음성 샘플을 기반으로 유사한 음성을 생성할 수 있습니다. example/voice_clone.py 파일을 참고하세요.
-
감정 및 톤 조절: 음성 샘플을 조건으로 사용하여 감정과 톤을 조절할 수 있습니다.
-
오픈소스 및 커스터마이징 가능: 코드와 모델 가중치가 공개되어 있어 사용자가 자유롭게 수정하고 활용할 수 있습니다.
사용 방법
설치
pip install git+https://github.com/nari-labs/dia.git
Gradio UI 실행
# uv가 설치되어 있는 경우
git clone https://github.com/nari-labs/dia.git
cd dia
uv run app.py
# 또는 uv가 설치되어 있지 않은 경우:
git clone https://github.com/nari-labs/dia.git
cd dia
python -m venv .venv
source .venv/bin/activate
pip install -e .
python app.py
Python 라이브러리로 사용
import soundfile as sf
from dia.model import Dia
model = Dia.from_pretrained("nari-labs/Dia-1.6B")
text = "[S1] Dia는 오픈소스 텍스트-투-스피치 모델입니다. [S2] 다양한 감정과 톤을 표현할 수 있습니다."
output = model.generate(text)
sf.write("output.mp3", output, 44100)
음성 클로닝 예제
import soundfile as sf
from dia.model import Dia
model = Dia.from_pretrained("nari-labs/Dia-1.6B")
clone_from_text = "[S1] Dia는 오픈소스 텍스트-투-스피치 모델입니다."
clone_from_audio = "sample.mp3"
text_to_generate = "[S1] 안녕하세요. Dia입니다."
output = model.generate(clone_from_text + text_to_generate, audio_prompt_path=clone_from_audio)
sf.write("voice_clone.mp3", output, 44100)
라이선스
Nari Labs의 Dia 프로젝트는 Apache License 2.0으로 공개되어 있습니다. 상업적 사용이 가능하지만, 실제 인물을 모방하거나 허위 정보를 생성하는 등의 악의적인 사용은 금지되어 있습니다.
 Dia GitHub 저장소
Dia GitHub 저장소
https://github.com/nari-labs/dia
 Dia-1.6B 모델을 Hugging Face Space에서 사용해보기
Dia-1.6B 모델을 Hugging Face Space에서 사용해보기
 Dia-1.6B 모델 다운로드
Dia-1.6B 모델 다운로드
 Dia와 ElevenLabs Studio, Sesame CSM-1B 결과 비교
Dia와 ElevenLabs Studio, Sesame CSM-1B 결과 비교
 더 큰 버전의 Dia 대기 신청하기
더 큰 버전의 Dia 대기 신청하기
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()