
DiffSensei 연구 소개
DiffSensei는 "사용자 맞춤형 만화 생성"이라는 새로운 과제를 해결하기 위해 설계된 프레임워크입니다. 만화는 캐릭터와 서사를 중심으로 이루어진 시각적 매체로, 기존의 텍스트-이미지(Text-to-Image) 생성 모델들은 캐릭터 간 상호작용이나 외형 세부 조정에서 한계가 있었습니다. DiffSensei는 이러한 한계를 극복하고 텍스트 기반 스토리 시각화를 고도화하기 위해 만들어졌습니다.
기존의 텍스트-이미지 생성 모델은 주로 단일 이미지 생성에 초점을 맞추고 있으며, 캐릭터 외형, 표정, 동작 등 다중 캐릭터의 세밀한 요소를 제어하기 어렵습니다. 예를 들어, 동일한 캐릭터가 여러 패널에 등장할 때 일관성을 유지하거나 특정 캐릭터 간의 상호작용을 표현하는 데 한계가 있습니다. 이를 해결하기 위해 DiffSensei는 확산 모델(Diffusion Model)과 멀티모달 대형 언어 모델(Multimodal-LLM)을 통합하여 정밀한 캐릭터 제어와 텍스트 적응을 구현합니다.
MangaZero 데이터셋
맞춤형 만화 생성 태스크는 다중 캐릭터를 포함하는 만화 이미지를 생성하는 데 중점을 둡니다. 각 캐릭터는 고유한 이미지 입력을 기반으로 커스터마이징되고 사용자에 의해 위치가 지정됩니다. 중요한 점은 캐릭터들이 텍스트 프롬프트에 따라 표정, 동작, 포즈를 동적으로 변경해야 한다는 것입니다.
N개의 패널(프레임)로 구성된 만화 스토리를 생성하기 위한 입력은 다음과 같습니다:
- 각 패널의 텍스트 프롬프트 (T_0, T_1, ..., T_{N-1})
- 캐릭터 이미지들 (I = I_0, I_1, ..., I_{K-1})
- 각 패널의 캐릭터 바운딩 박스 (B_0^c, B_1^c, ..., B_{N-1}^c)
- 각 패널의 대화 바운딩 박스 (B_0^d, B_1^d, ..., B_{N-1}^d)
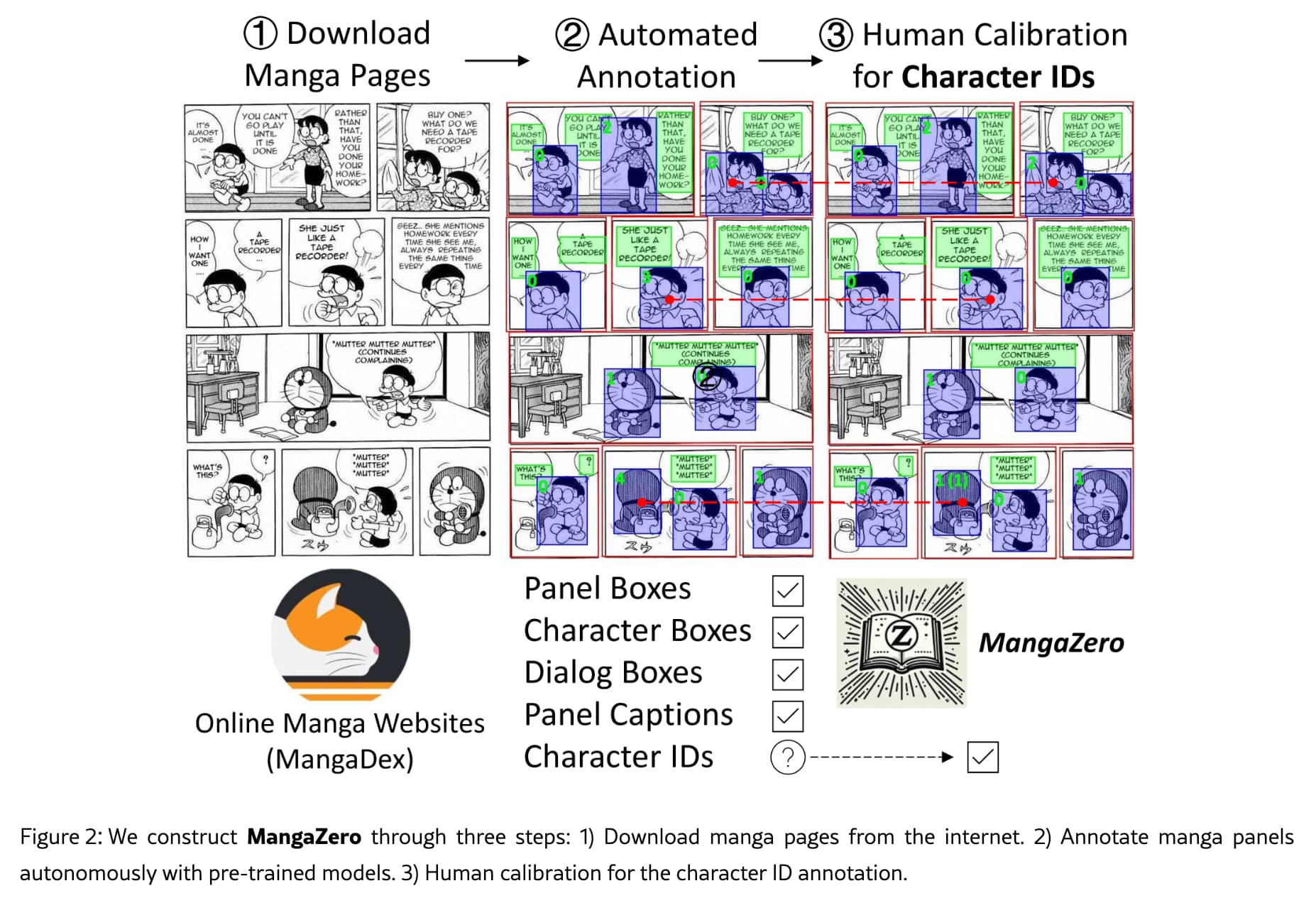
MangaZero 데이터셋은 다음과 같은 3단계 과정을 통해 구축되었습니다:
- 데이터 수집:
- MangaDex에서 48개의 만화 시리즈 선정
- 시리즈당 최대 1,000페이지 다운로드
- 총 43,264개의 더블 페이지 이미지 수집
- 자동 주석 처리:
- Magi 모델을 사용한 만화 특화 주석 처리
- 패널 바운딩 박스, 캐릭터 바운딩 박스, 캐릭터 ID, 대화 바운딩 박스 추출
- LLaVA-v1.6-34B를 사용한 패널 캡션 생성
- 인간 검증:
- 기계 생성 라벨의 정확도 향상을 위한 수동 검증
- 특히 캐릭터 ID 라벨링의 정확도 개선에 중점
DiffSensei 프레임워크 구조
DiffSensei는 다음의 두 가지 핵심 문제를 해결하고자 합니다:
- 소스 이미지로부터의 단순 복사-붙여넣기를 피하면서 캐릭터의 본질적 특징을 보존하는 것: 캐릭터의 본질적 특성은 유지하면서도 단순한 복사-붙여넣기를 피해야 하는 것이 주요한 문제 중 하나입니다. 특히, 텍스트 프롬프트에 따라 캐릭터의 표정, 포즈, 동작을 자연스럽게 변형할 수 있어야 하며, 픽셀 수준의 직접적인 전달을 피하고 의미론적 특성을 전달해야 합니다.
- 학습과 추론 과정에서 최소한의 계산 비용으로 안정적인 레이아웃 제어를 구현하는 것: 최소한의 연산 비용으로 캐릭터와 대화 말풍선의 정확한 위치 지정하거나, 여러 캐릭터들 간의 상호작용을 자연스럽게 표현하는 것이 필요합니다.
이를 위해 캐릭터 이미지 특성을 토큰화하여 직접적인 픽셀 세부사항 전송을 방지하고, 멀티모달LLM(MLLM)을 캐릭터 이미지 특성 어댑터로 활용합니다. 레이아웃 제어를 위해서는 경량의 마스크드 인코딩 기법을 도입하여 계산 비용을 최소화하도록 하였습니다.
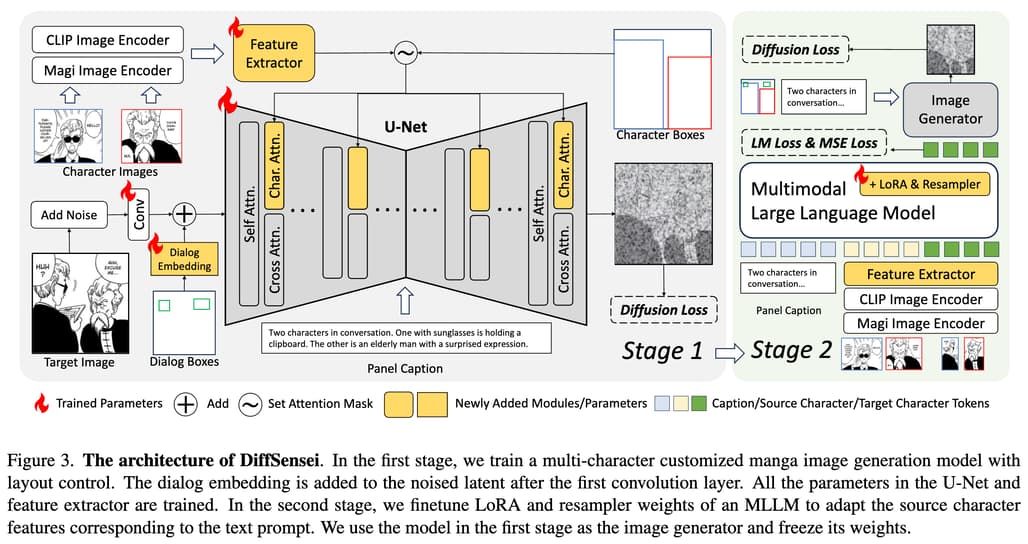
DiffSensei 프레임워크의 주요 구성요소들은 다음과 같습니다:
다중 캐릭터 특성 추출 (Multi-character Feature Extraction)
다중 캐릭터 특성 추출은 입력된 캐릭터 이미지들의 본질적인 특성을 효과적으로 포착하면서도 단순한 복사-붙여넣기를 방지하기 위해 설계된 시스템입니다. 이 시스템은 두 개의 서로 다른 이미지 인코더(CLIP과 Magi)를 사용하여 캐릭터의 시각적 특성을 다각도로 포착합니다. CLIP 인코더는 일반적인 시각적 특성과 의미론적 이해를 담당하며, Magi 인코더는 만화 스타일에 특화된 특성을 추출합니다. 추출된 특성들은 리샘플러(resampler) 모듈을 통해 처리되어 캐릭터별로 몇 개의 토큰으로 압축됩니다. 이렇게 압축된 토큰 형태의 표현은 미세한 픽셀 수준의 정보 대신 캐릭터의 핵심적인 특성만을 포착하게 됩니다. 각 캐릭터마다 할당된 쿼리 토큰들은 이후 생성 과정에서 캐릭터의 정체성을 유지하면서도 유연한 변형을 가능하게 합니다. 특히 비캐릭터 영역을 위한 별도의 플레이스홀더 벡터를 도입하여 캐릭터가 없는 영역도 적절히 처리할 수 있게 했습니다.
마스크드 크로스 어텐션 주입 (Masked Cross-attention Injection)
마스크드 크로스 어텐션 주입 메커니즘은 각 캐릭터의 위치와 레이아웃을 효과적으로 제어하기 위해 고안된 시스템입니다. 기존의 어텐션 메커니즘을 확장하여 텍스트와 캐릭터를 위한 별도의 크로스 어텐션 레이어를 구성했습니다. 각 캐릭터는 자신에게 할당된 바운딩 박스 영역 내에서만 영향을 미치도록 주의 마스크가 적용됩니다. 이러한 마스킹 전략은 캐릭터들이 서로의 영역을 침범하지 않으면서도 자연스럽게 상호작용할 수 있게 합니다. 텍스트와 캐릭터 어텐션의 결과는 가중치를 통해 적절히 조합되어 최종 출력에 반영됩니다. 특히 비캐릭터 영역에서는 플레이스홀더 벡터가 활용되어 배경이나 기타 요소들이 자연스럽게 생성되도록 합니다. 이 접근 방식은 기존의 레이아웃 제어 방법들보다 계산 효율성이 높으면서도 정확한 위치 제어가 가능합니다.
대화 레이아웃 인코딩 (Dialog Layout Encoding)
대화 레이아웃 인코딩은 만화의 핵심 요소인 대화 말풍선의 위치와 형태를 효과적으로 제어하기 위해 개발된 시스템입니다. 현재의 텍스트-이미지 생성 모델들은 긴 대화문을 생성하는 데 한계가 있다는 점을 고려하여, 실제 텍스트 내용 대신 레이아웃만을 제어하는 접근방식을 채택했습니다. 학습 가능한 대화 임베딩을 도입하여 말풍선의 위치와 크기를 효과적으로 인코딩합니다. 이 임베딩은 노이즈가 있는 잠재 공간과 동일한 크기로 확장되어 대화 영역 마스크와 결합됩니다. 최소한의 계산 리소스로도 정확한 말풍선 배치가 가능하도록 설계되었습니다. 이러한 접근 방식은 아티스트가 나중에 실제 대화 내용을 수동으로 편집할 수 있는 유연성을 제공합니다. U-Net의 노이즈 예측 과정에서 대화 레이아웃 정보가 자연스럽게 반영되도록 합니다.
MLLM 기반 텍스트 호환 캐릭터 특성 어댑터 (MLLM as Text-compatible Character Feature Adapter)
MLLM 기반 캐릭터 특성 어댑터는 텍스트 프롬프트에 따라 캐릭터의 표정, 포즈, 동작을 유연하게 조정하기 위해 도입된 혁신적인 컴포넌트입니다. 기존의 접근 방식들이 입력 캐릭터 이미지의 픽셀 분포를 지나치게 엄격하게 따르는 문제를 해결하고자 했습니다. MLLM을 활용하여 패널 캡션과 소스 캐릭터 특성을 입력으로 받아 텍스트에 부합하는 새로운 캐릭터 특성을 생성합니다. 특수 토큰을 활용하여 출력 형식을 제어하고, 다양한 손실 함수(LM Loss, MSE Loss, Diffusion Loss)를 통해 고품질의 특성 변환을 달성합니다. LoRA와 리샘플러 가중치만을 업데이트하는 효율적인 학습 전략을 채택했습니다. MangaZero 데이터셋의 캐릭터 ID 주석을 활용하여 동일 캐릭터의 다양한 표현을 학습할 수 있게 했습니다. 이미지 생성기와의 정렬을 위해 생성된 특성을 U-Net의 캐릭터 크로스 어텐션에 전달하여 디퓨전 손실을 계산합니다. 이러한 설계를 통해 캐릭터의 정체성은 유지하면서도 텍스트 프롬프트에 따라 자연스럽게 변화하는 표현이 가능해졌습니다.
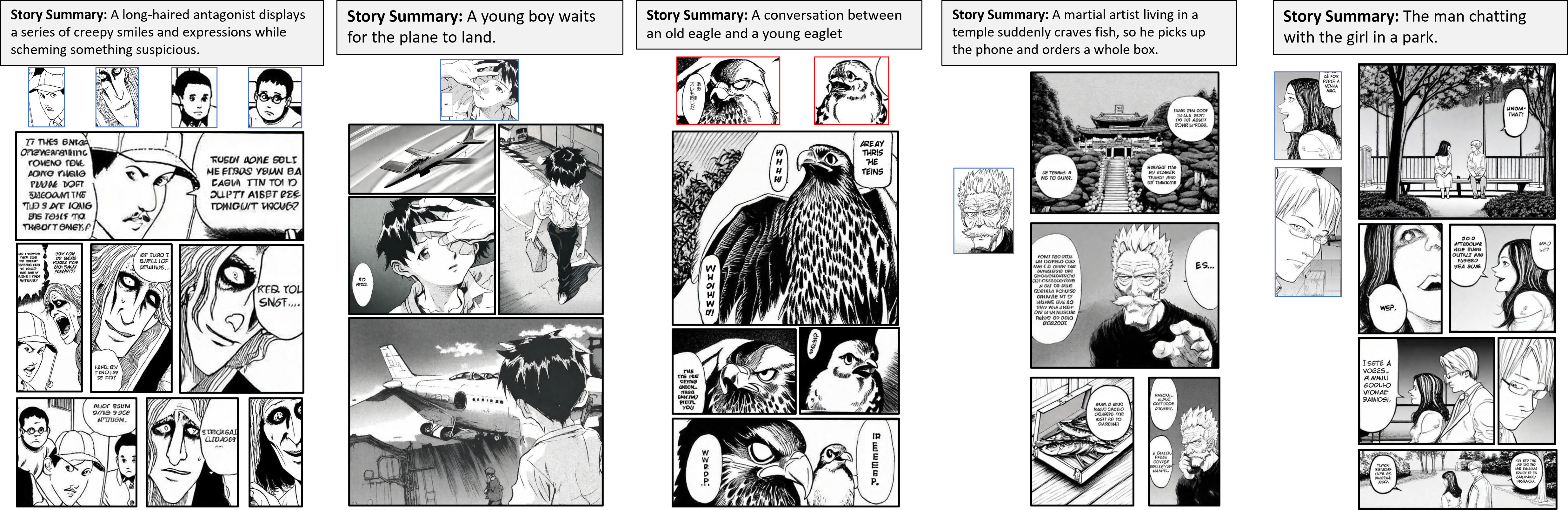
DiffSensei로 생성한 결과 및 예시
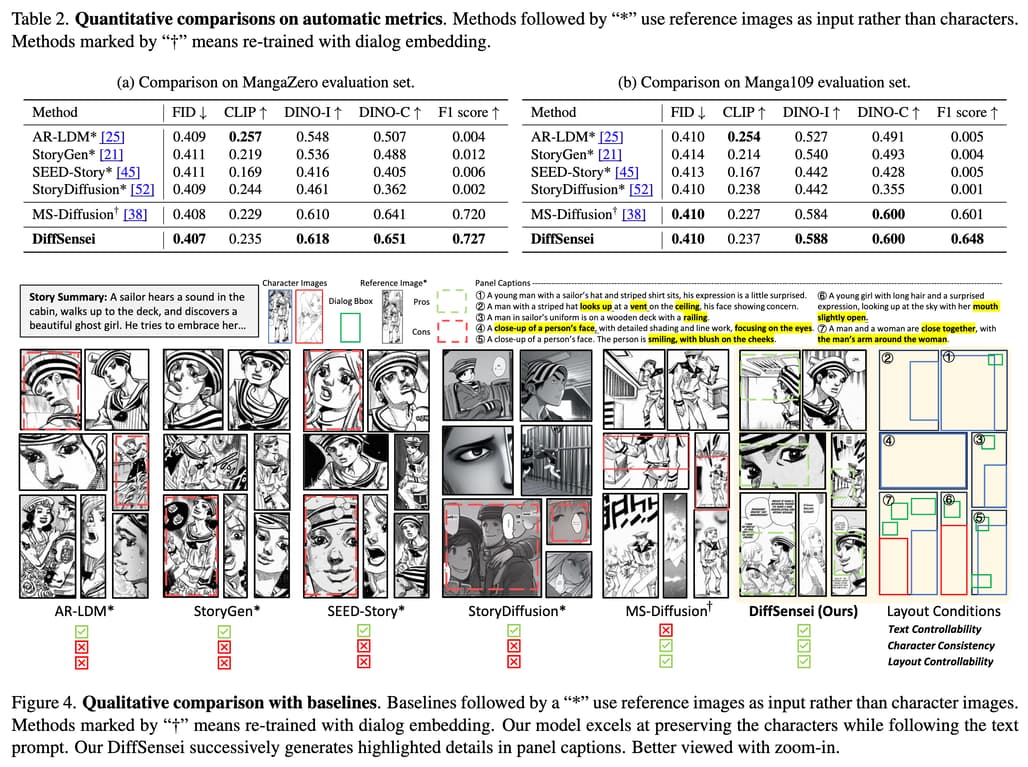
아래 예시 이미지 또는 PDF를 참고해주세요:




 DiffSensei 프로젝트 홈페이지
DiffSensei 프로젝트 홈페이지
 DiffSensei 논문
DiffSensei 논문
 DiffSensei GitHub 저장소
DiffSensei GitHub 저장소
https://github.com/jianzongwu/DiffSensei
 DiffSensei의 MangaZero 데이터셋
DiffSensei의 MangaZero 데이터셋
더 읽어보기
- [GN] Comic-Factory - 디퓨전 모델을 이용하여 만화를 생성해주는 도구
- [GN] Shortbread - AI를 이용해 만화 만들기
- [GN] Stability AI, 스케치를 이미지로 바꿔주는 Stable Doodle 공개
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()