
DifuzCam 논문 소개
DifuzCam 논문에서는 전통적인 렌즈를 평면적이고 렌즈 없는 마스크로 대체하여 카메라의 크기를 크게 줄이는 새로운 카메라 설계를 소개합니다. 전통적인 카메라는 렌즈를 사용하여 빛을 센서에 초점 맞추는데, 이 논문에서는 렌즈를 센서 근처에 배치된 정적 진폭 마스크로 대체합니다. 이렇게 하면 센서에 도달하는 데이터는 복잡한 다중 투영으로 이루어져 있으며, 이는 직접적으로 해석할 수 없는 이미지가 됩니다. 이러한 평면 카메라(FlatCam) 데이터로부터 고품질의 이미지를 복원하는 것은 본질적으로 어려운 과제입니다.
이 문제를 해결하기 위해 저자들은 강력한 자연 이미지 사전(prior) 역할을 하는 사전 학습된(pre-trained) 확산 모델을 활용한 새로운 방법을 제안합니다. 확산 모델은 이미지를 복원하기 위해 노이즈를 제거하는 일련의 과정으로 이미지를 생성하는 생성 모델의 일종으로, 이미지 합성, 인페인팅(inpainting), 초해상도(super-resolution) 등에서 우수한 성과를 보여왔습니다. DifuzCam 논문에서는 이 모델을 컨트롤 네트워크(ControlNet)와 결합하여 확산 과정을 평면 카메라 데이터에 적응시켜 복원 정확도를 높이고자 합니다. 또한, 장면에 대한 텍스트 설명을 포함하여 이미지 품질을 더욱 향상시키는 텍스트 지침(text guidance) 기능도 통합했습니다.
이러한 기술을 결합하여 DifuzCam이라는 새로운 컴퓨팅 사진학 접근법이 탄생했습니다. 이 방법은 평면 카메라(FlatCam) 데이터로부터 고품질 이미지를 복원할 수 있게 하며, 다양한 이미징 시스템에도 적용 가능하다는 점을 실험적으로 보여줍니다. 이 논문은 초소형 렌즈 없는 카메라를 실제로 사용할 수 있게 하는 길을 제시하며, 고품질 이미지를 생성할 수 있는 방법을 제공하는 중요한 기여를 하고 있습니다.
DifuzCam 방법론
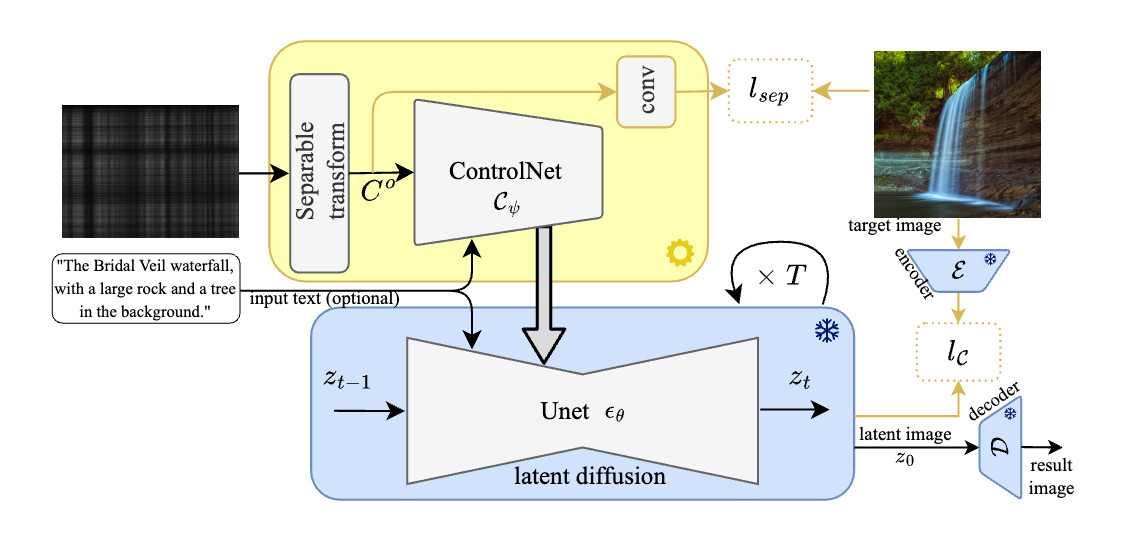
먼저, 평면 카메라(FlatCam)로 실제 이미지를 캡처하여 학습 데이터를 수집했습니다. 이 과정에서 약 55,000개의 이미지를 수집하였고, 그 중 500개의 이미지는 테스트용으로 따로 저장했습니다. 이 데이터는 LAION 데이터셋을 사용하여 수집되었으며, 이는 고해상도의 이미지와 그에 해당하는 텍스트 설명을 포함하고 있습니다. 이 데이터를 통해 DifuzCam 모델을 학습시켰으며, 이를 통해 고품질의 이미지 재구성이 가능해졌습니다.
평면 카메라로부터 얻어진 원시 이미지는 픽셀 공간에서 재구성될 수 있도록 학습된 분리 가능 선형 변환을 거칩니다. 이 변환은 재구성 과정에서 매우 중요한 역할을 하며, 플랫 카메라 측정값으로부터 자연스러운 이미지를 생성할 수 있도록 합니다. 또한, 이 과정에서 텍스트 설명을 추가로 활용하여 이미지 재구성의 품질을 더욱 향상시킬 수 있습니다. 이는 촬영자가 장면에 대해 설명한 내용을 바탕으로 재구성된 이미지가 더 정확하게 표현될 수 있도록 도와줍니다.
학습 과정에서는 사전 학습된 확산 모델을 사용하여 고품질의 이미지를 생성합니다. 이를 위해 우리는 플랫 카메라로부터 얻어진 실제 측정값을 사용하여 모델을 학습시켰으며, 이 과정에서 다양한 노이즈와 비이상적인 효과를 포함한 실제 측정값을 활용하였습니다. 이렇게 얻어진 데이터는 매우 현실적이며, 이를 통해 학습된 모델은 실제 응용에서 잘 작동할 수 있게 됩니다. 학습된 모델은 최종적으로 고화질의 이미지를 재구성할 수 있으며, 이는 아래와 같이 기존 방법들보다 훨씬 향상된 결과를 제공합니다.

DifuzCam의 주요 아이디어를 정리하면 다음과 같습니다:
-
확산 모델을 이미지 사전으로 사용: DifuzCam의 첫 번째 주요 기여는 확산 모델을 이미지 사전으로 사용하는 것입니다. 확산 모델은 자연 이미지의 분포를 학습하여 고품질 이미지를 생성하는 것으로 알려진 생성 모델입니다. DifuzCam에서는 확산 모델이 사전 역할을 하여 복원 과정의 강력한 출발점을 제공합니다. 이는 평면 카메라가 캡처한 데이터가 매우 복잡하여 강력한 사전 없이 쉽게 해석할 수 없기 때문에 매우 중요합니다. 사전 학습된 확산 모델을 활용함으로써, 저자들은 정확하면서도 지각적으로 현실적인 이미지를 복원할 수 있었습니다.
-
텍스트 기반 이미지 복원: 두 번째 주요 기여는 복원 과정에 텍스트 지침을 통합한 것입니다. 확산 모델을 사용하는 것 외에도, DifuzCam은 장면에 대한 텍스트 설명을 복원 과정에 포함할 수 있습니다. 이는 촬영자가 캡처된 장면을 설명하는 텍스트를 제공할 수 있으며, 모델이 이 정보를 사용하여 복원 과정을 안내합니다. 텍스트 기반 접근법은 복원된 이미지의 세부 사항을 더욱 정밀하게 조정할 수 있도록 도와줍니다. 이는 특히 원시 데이터만으로는 장면을 완전히 복원하기 어려운 경우에 유용합니다.
-
학습된 분리 가능한 변환: 세 번째 주요 기여는 확산 모델에 데이터를 입력하기 전에 원시 센서 데이터에 학습된 분리 가능한 선형 변환을 사용하는 것입니다. 이 변환은 복잡하고 중첩된 평면 카메라 데이터를 더 쉽게 처리할 수 있는 형식으로 변환하는 데 매우 중요합니다. 분리 가능한 변환은 데이터를 다른 차원에서 독립적으로 처리할 수 있도록 하여, 계산 복잡성을 줄이고 효율성을 높입니다. 이 단계는 전체적으로 복원된 이미지의 품질을 크게 향상시킵니다.
결론
DifuzCam 논문에서는 플랫 카메라로부터 얻은 측정값으로부터 고품질 이미지를 재구성할 수 있는 새로운 방법을 제안했습니다. 이 방법은 사전 학습된 확산 모델의 강력한 이미징 기능을 활용하며, 텍스트 설명을 추가하여 이미지 재구성의 품질을 더욱 향상시킬 수 있습니다. DifuzCam은 기존의 방법들보다 재구성 품질이 훨씬 우수하며, 이는 플랫 카메라의 실용성을 크게 높일 수 있는 잠재력을 가지고 있습니다.
저자들은 PSNR(피크 신호 대 잡음 비율), SSIM(구조적 유사도 지수), LPIPS(학습된 지각 이미지 패치 유사도)와 같은 다양한 이미지 품질 지표를 사용하여 이 방법을 평가했습니다. 이러한 지표는 이미지 처리 분야에서 표준화된 것으로, 복원된 이미지의 품질을 정량적으로 측정하는 데 사용됩니다.
이러한 전통적인 지표 외에도, 저자들은 텍스트 유사도 지표인 CLIP 점수를 사용하여 이 방법을 평가했습니다. 이 지표는 복원된 이미지와 장면에 대한 텍스트 설명 사이의 일치를 측정하며, 텍스트 기반 복원 과정이 얼마나 효과적인지를 평가합니다. 결과는 DifuzCam이 고품질 이미지를 생성할 뿐만 아니라, 텍스트로부터 제공된 의미 정보를 성공적으로 통합하여 복원 품질을 더욱 향상시킬 수 있음을 보여줍니다.
하지만 이 방법은 여전히 몇 가지 한계를 가지고 있습니다. 예를 들어, 재구성된 이미지가 원본 이미지와 완전히 일치하지 않는 경우가 있으며, 이는 이미지 획득 과정에서 손실된 세부 정보를 모델이 생성하는 과정에서 발생할 수 있습니다. 이러한 문제는 모델의 학습 과정에서 발생하는 불가피한 특성으로, 오히려 재구성 품질을 향상시키는 데 기여할 수 있을 것입니다.
 DifuzCam 논문
DifuzCam 논문
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()