Distil-Text2SQL(Text2SQirreL) 소개
Distil-Text2SQL(Text2SQirreL) 은 자연어 질문을 SQL 쿼리로 변환하는 Text-to-SQL 작업에 특화된 오픈소스 경량 언어 모델 프로젝트입니다. 최근 기업 환경에서 데이터베이스에 대한 비전문가의 접근성을 높이기 위해 자연어를 SQL로 변환하는 기술이 필수적으로 대두되고 있습니다. 하지만 OpenAI의 GPT 모델이나 Anthropic의 Claude와 같은 범용 대규모 언어 모델(LLM)을 이 작업에 사용하기에는 비용이 높고, 네트워크를 통해야 하기 때문에 응답 속도(Latency)가 느릴 수 있으며, 데이터 프라이버시 문제로 인해 온프레미스(On-premise) 구축이 어렵다는 한계가 있었습니다.
Distil-Text2SQL 모델을 개발 및 공개한 Distil Labs는 이러한 문제를 해결하기 위해 지식 증류(KD, Knowledge Distillation) 기법을 활용했습니다. 이는 대규모 모델이 가진 추론 능력과 SQL 생성 지식을 훨씬 작은 모델에 압축하여 전달하는 방식입니다. Text2SQirrel 모델은 DeepSeek-V3 685B 모델이 가진 지식을 4B 모델에 학습시킨 것으로, 그 결과물인 Distil-Qwen3-Text2SQL 모델들은 파라미터 수가 매우 적음에도 불구하고, 복잡한 데이터베이스 스키마를 이해하고 정확한 SQL 쿼리를 생성하는 데 있어 놀라운 성능을 보여줍니다.
Distil-Text2SQL vs. 일반적인 LLM 비교
Distil-Text2SQL 모델은 일반적으로 사용하는 대규모 언어 모델(LLM)과 비교할 때 효율성 및 특화성에서 큰 차이를 보입니다. GPT 모델이나 Claude 등과 같은 범용 LLM 모델은 다양한 지식을 가지고 있지만, 단순한 SQL 쿼리 하나를 생성하기 위해 과도한 연산 자원을 소모합니다. 반면 Distil-Text2SQL은 SQL 생성에 불필요한 지식을 덜어내고, 오직 스키마 해석과 쿼리 작성에 집중하도록 튜닝되어 적은 리소스로도 동등 수준의 정확도를 제공합니다.
또한, Distil-Text2SQL 모델들은 Qwen 시리즈를 베이스로 하지만, 단순한 미세 조정(Fine-tuning)을 넘어선 강화 학습과 정제된 데이터셋을 통해 추가로 학습하였습니다. 이를 통해 베이스 모델보다 질문 속 단어가 DB의 어떤 테이블/컬럼에 해당하는지 연결하는 스키마 링크(Schema Linking) 능력이 훨씬 뛰어납니다.
특히, Distil-Text2SQL-0.6B 모델의 경우, 라즈베리 파이(Raspberry Pi)나 모바일 기기 같은 엣지 디바이스에서도 구동이 가능할 정도로 가볍습니다. 이는 서버 비용을 획기적으로 절감할 수 있음을 의미합니다.
Distil-Text2SQL의 특징
이 프로젝트는 다양한 환경에 맞춰 선택할 수 있는 여러 크기의 모델을 제공하며, 각 모델은 최적의 SQL 생성 성능을 위해 고도로 튜닝되었습니다.
주요 모델 라인업
Distil-Labs는 사용자의 하드웨어 환경과 요구 사항에 따라 활용할 수 있는 0.6B 및 4B 규모의 두 가지 모델을 공개했습니다:
Distil-Qwen3-4B-Text2SQL은 엔터프라이즈급 성능을 목표로 하는 4B 규모의 모델입니다. 복잡한 JOIN 연산이나 다중 조건문(Nested Queries)이 필요한 환경에서 높은 정확도를 보입니다. 3~4GB 정도의 VRAM만 있어도 원활하게 구동 가능하므로 일반적인 소비자용 GPU에서도 서버급 성능을 냅니다.
Distil-Qwen3-0.6B-Text2SQL은 극단적인 경량화를 추구하는 0.6B 크기의 모델입니다. 리소스가 매우 제한적인 환경이나, 매우 빠른 응답 속도가 필요한 실시간 애플리케이션에 적합합니다. 작은 크기임에도 불구하고 기본적인 SQL 쿼리 생성 능력은 타협하지 않았습니다.
| 모델명 | 모델 크기 | LLM-as-a-Judge 성능 | Exact Match 성능 |
|---|---|---|---|
| DeepSeek-V3 (teacher) | 685B | 80% | 48% |
| Distil-Qwen3-4B-Text2SQL (tuned) | 4B | 80% | 60% |
| Distil-Qwen3-0.6B-Text2SQL (tuned) | 0.6B | 74% | 40% |
| Qwen3-4B (base) | 4B | 62% | 16% |
| Qwen3-0.6B (base) | 0.6B | 36% | 24% |
학습 방법론 (Knowledge Distillation)
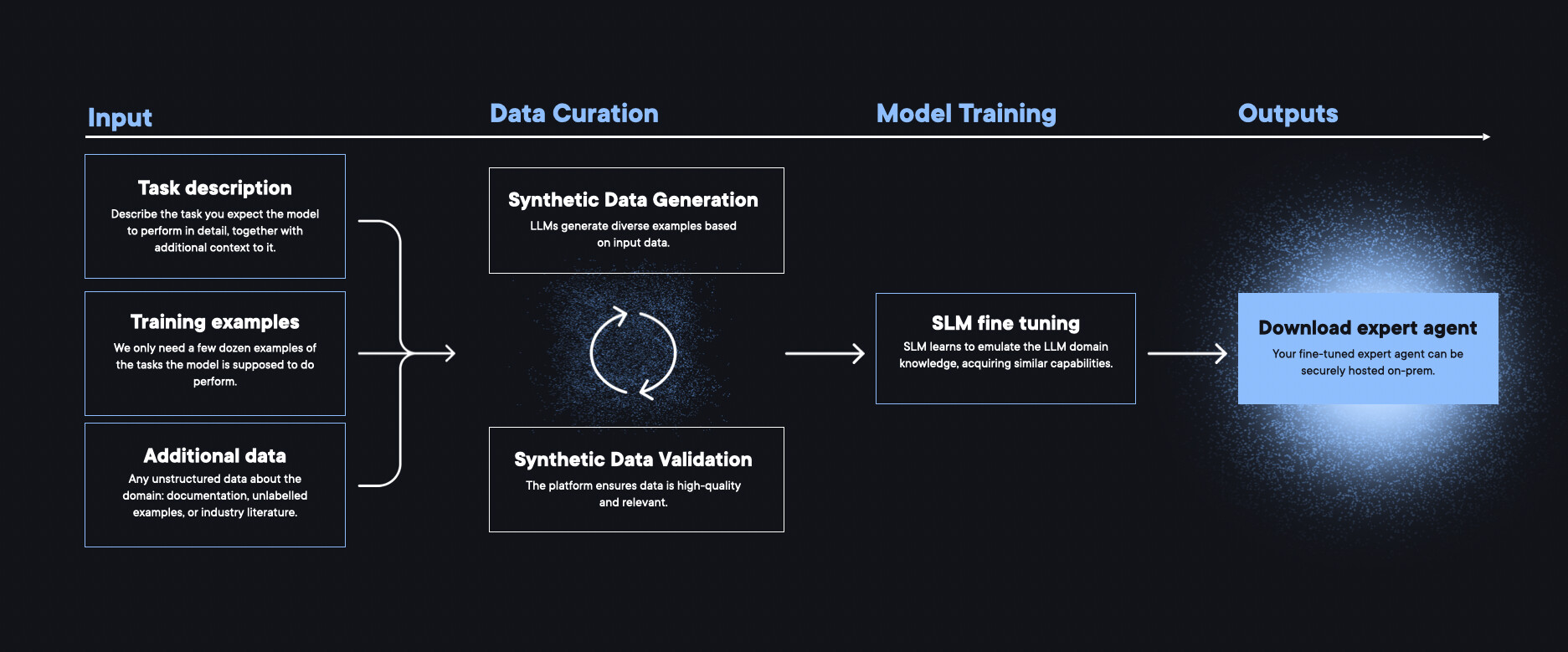
이 모델들의 핵심은 학습 데이터와 과정에 있습니다. 단순히 (질문, SQL) 쌍(pair)만 학습한 것이 아니라, 사고의 연쇄(CoT, Chain-of-Thought) 데이터를 활용하여 모델이 생각하는 법을 배우도록 했습니다. 이 과정은 다음과 같은 3단계를 거쳐 진행하였습니다:
-
1단계. 시드 데이터 (Seed Data) 학습: 사람이 직접 작성한 약 50개의 예제로 시작했습니다. 단순 조회(Simple queries)부터 조인(JOINs), 집계(Aggregations), 서브쿼리(Subqueries) 등 다양한 난이도의 SQL 패턴을 포함하여 모델이 기초 문법을 익히도록 했습니다.
-
2단계. 합성 확장 (Synthetic Expansion): Distil Labs가 자체 개발한 데이터 합성 파이프라인을 사용하여 50개의 시드 데이터를 약 10,000개의 학습 예제로 확장했습니다. 여기에는 전자상거래(E-commerce), 인사(HR), 헬스케어 등 다양한 도메인의 스키마를 포함시켜 모델의 범용성을 확보했습니다.
-
3단계: 모델 파인튜닝 (Fine-tuning): 확장된 10,000개의 데이터를 사용하여 4 Epoch 동안 전체 파인튜닝(Full Fine-tuning)을 진행했습니다. 베이스 모델로는 효율성과 성능 밸런스가 가장 뛰어난 Qwen3-4B가 사용되었습니다.
Distil-Text2SQL 설치 및 사용 예제 (Python)
Hugging Face의 transformers 라이브러리를 사용하여 간단하게 모델을 테스트할 수 있습니다.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 원하는 모델 사이즈 선택 (4B 또는 0.6B)
model_id = "distil-labs/distil-qwen3-4b-text2sql"
# 토크나이저 및 모델 로드
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype=torch.float16
)
# 프롬프트 구성 (스키마 정보 포함 필수)
schema = """
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT,
city VARCHAR(50)
);
"""
question = "서울에 사는 30세 이상 사용자의 이름을 찾아줘."
prompt = f"### Schema:\n{schema}\n\n### Question:\n{question}\n\n### SQL:\n"
# 쿼리 생성
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=100)
generated_sql = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 생성한 쿼리 출력
print(generated_sql)
 Distil Labs의 데이터 생성 및 학습 과정 블로그
Distil Labs의 데이터 생성 및 학습 과정 블로그
 Distil-Text2SQL 프로젝트 GitHub 저장소
Distil-Text2SQL 프로젝트 GitHub 저장소
 Distil-Qwen3-Text2SQL 모델 다운로드
Distil-Qwen3-Text2SQL 모델 다운로드
Distil-Qwen3-4B-Text2SQL 모델 (4B)
Distil-Qwen3-0.6B-Text2SQL 모델 (0.6B)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()