Dive into Claude Code: 소개
우리는 매일 AI 코딩 에이전트에게 "이 테스트 좀 고쳐줘"라고 말하지만, 그 한 줄의 요청이 내부에서 어떤 경로를 거쳐 실제 셸 명령과 파일 수정으로 바뀌는지는 거의 들여다보지 않습니다. 마치 자동차의 핸들과 페달만 알 뿐 엔진룸을 열어본 적이 없는 운전자와 비슷합니다.
이 논문 Dive into Claude Code 는 바로 그 엔진룸을 여는 작업입니다. 저자들은 공개된 Claude Code의 TypeScript 소스 코드(버전 v2.1.88, 약 $1,884$개 파일, $51$만여 줄)를 직접 분석하여, 이 상용 에이전트가 "안전, 컨텍스트 관리, 확장성, 위임"이라는 반복되는 설계 질문에 어떻게 답하고 있는지를 소스 파일 단위로 추적합니다. 그리고 같은 질문에 다른 방식으로 답하는 오픈소스 에이전트 OpenClaw 와 비교하여, 배포 맥락이 달라지면 같은 질문이 어떻게 다른 아키텍처로 귀결되는지를 보여줍니다. 이 글은 그 분석을 따라가며 "프로덕션 AI 에이전트는 실제로 무엇으로 만들어지는가"를 정리합니다.
논문은 MBZUAI(Mohamed bin Zayed University of Artificial Intelligence)의 VILA Lab과 University College London이 함께 작성한 기술 보고서입니다. 분석에 사용한 모든 자료는 공개된 소스이며, 소스 코드의 지적 재산권은 Anthropic에 있다는 점을 명시하고 있습니다.
자동 완성에서 자율 에이전트까지: 설계 공간이라는 관점
AI 기반 소프트웨어 개발은 GitHub Copilot 같은 자동 완성 도구에서 출발해, Cursor처럼 IDE에 통합된 어시스턴트를 거쳐, 이제는 스스로 여러 단계의 수정을 계획하고 셸 명령을 실행하며 자기 출력을 반복적으로 고치는 완전한 에이전트 시스템으로 진화했습니다. 제안에서 자율적 행동으로 넘어가는 이 전환은, 단순 완성 도구에는 존재하지 않던 새로운 아키텍처 요구사항을 만들어냅니다.
저자들은 이 요구사항들을 설계 공간(design space) 이라고 부릅니다. 즉 모든 코딩 에이전트가 반드시 풀어야 하는 반복되는 질문들의 집합입니다. "추론(reasoning)은 어디에서 일어나는가", "반복 루프는 어떻게 구성하는가", "기본 안전 태세는 무엇인가", "컨텍스트는 어떻게 관리하는가" 같은 질문이 여기에 속합니다. 중요한 점은 이런 질문에 대한 답이 하나가 아니라는 것입니다.
기존 시스템들은 같은 질문에 서로 다르게 답해 왔습니다. LangGraph 같은 프레임워크는 의사결정 로직을 타입이 지정된 엣지를 가진 명시적 상태 그래프(state graph)로 인코딩합니다. 즉 최소한의 하네스(harness)보다 풍부한 스캐폴딩(scaffolding)을 택한 방식입니다. SWE-Agent 와 OpenHands 는 계층화된 정책 집행 대신 Docker 컨테이너 격리에 의존합니다. Aider 는 deny-first 평가 대신 Git 롤백을 1차 안전장치로 사용합니다.
Claude Code의 원칙 집합이 독특한 이유는 이 선택지들을 한쪽만 고르지 않고 결합했다는 데 있습니다. 최소한의 의사결정 스캐폴딩과 계층화된 정책 집행을 함께 쓰고, 규칙 기반이 아니라 가치 기반 판단을 deny-first 기본값과 결합하며, 점진적 컨텍스트 관리와 조합 가능한 확장성을 동시에 추구합니다.
1.6%의 AI, 98.4%의 인프라
이 논문에서 가장 자주 인용되는 발견은 한 문장으로 요약됩니다. 논문이 인용한 커뮤니티 분석에 따르면, Claude Code 코드베이스에서 실제 "AI 의사결정 로직"에 해당하는 부분은 약 1.6\% 에 불과하고, 나머지 98.4\% 는 권한 게이트, 컨텍스트 관리, 도구 라우팅, 복구 로직 같은 결정론적(deterministic) 운영 인프라입니다.
여기서 핵심 발상의 전환이 드러납니다. 모델은 무엇을 할지 추론하고, 하네스는 그 행동을 집행한다 는 분리입니다. 모델은 응답의 일부로 tool_use 블록을 내보낼 뿐이고, 하네스가 이를 파싱하고 권한을 확인한 뒤 도구 구현으로 전달하고 결과를 수집합니다. 모델은 파일시스템에 직접 접근하거나 셸 명령을 실행하거나 네트워크 요청을 보내지 않습니다. 이 분리에는 보안적 함의가 있습니다. 추론과 집행이 별도의 코드 경로를 차지하므로, 설령 모델이 적대적으로 조작되더라도 하네스에 구현된 샌드박싱, 권한 검사, deny-first 규칙을 무력화할 수 없습니다.
이는 에이전트 엔지니어링의 지배적 패턴과 정반대입니다. 더 똑똑한 플래너나 더 정교한 상태 그래프로 모델의 선택을 제약하는 대신, Claude Code는 풍부한 운영 하네스 안에서 모델에게 최대한의 결정 재량을 줍니다. 엔지니어링 복잡도는 모델의 결정을 제약하기 위해서가 아니라 가능하게 하기 위해 존재합니다.
5가지 가치에서 13개 설계 원칙으로
저자들은 아키텍처가 임의로 만들어진 것이 아니라 그 제작자들이 "무엇이 중요한가"에 대해 믿는 바를 반영한다고 봅니다. 그래서 먼저 아키텍처를 움직이는 다섯 가지 인간 중심 가치를 식별합니다.
- 인간의 결정 권한(Human Decision Authority): 인간이 시스템의 행동에 대한 최종 결정권을 가집니다. Anthropic, 운영자(operator), 사용자로 이어지는 주체 계층(principal hierarchy)으로 형식화됩니다. Anthropic이 사용자들이 권한 프롬프트의 약 93\% 를 승인한다는 사실을 발견했을 때, 대응은 경고를 더 추가하는 것이 아니라 문제를 재구조화하는 것이었습니다. 즉 행동마다 승인을 받는 대신, 에이전트가 자유롭게 일할 수 있는 경계(샌드박싱, 자동 모드 분류기)를 정의하는 방식입니다.
- 안전, 보안, 프라이버시(Safety, Security, Privacy): 인간이 부주의하거나 실수하더라도 시스템이 사용자와 코드, 데이터, 인프라를 보호합니다. 결정 권한이 "선택할 힘"에 관한 것이라면, 안전은 "그 힘이 작동하지 않을 때조차 보호할 의무"에 관한 것입니다.
- 신뢰할 수 있는 실행(Reliable Execution): 에이전트가 사용자가 실제로 의도한 바를 수행하고, 시간이 지나도 일관성을 유지하며, 성공을 선언하기 전에 자기 작업을 검증합니다. Anthropic 문서는 이를 "맥락 수집, 행동, 결과 검증"의 3단계 루프로 설명합니다.
- 역량 증폭(Capability Amplification): 단위 노력과 비용당 인간이 해낼 수 있는 일의 양을 실질적으로 늘립니다. 제작자들은 Claude Code를 "전통적 제품이 아니라 유닉스 유틸리티"로 묘사합니다. Anthropic 내부 설문에서 AI 보조 작업의 약 27\% 가 "도구가 없었다면 시도조차 하지 않았을 일"이었다는 결과는, 이 아키텍처가 기존 작업을 빠르게 하는 것을 넘어 질적으로 새로운 워크플로우를 가능하게 함을 시사합니다.
- 맥락적 적응성(Contextual Adaptability): 시스템이 사용자의 프로젝트, 도구, 관습, 숙련도에 맞춰지고 관계가 시간에 따라 개선됩니다. 종단 데이터에 따르면 자동 승인 비율은 50 세션 미만에서 약 20\% 였다가 750 세션에 이르면 40\% 이상으로 증가합니다. 신뢰는 고정된 상태가 아니라 궤적으로 다뤄집니다.
이 다섯 가치는 13개의 설계 원칙 으로 구체화됩니다. 각 원칙은 프로덕션 코딩 에이전트가 반드시 답해야 하는 질문 하나에 대응합니다. 예를 들면 다음과 같습니다.
| 설계 원칙 | 답해야 하는 설계 질문 |
|---|---|
| Deny-first with human escalation | 인식되지 않은 행동을 허용할까, 차단할까, 인간에게 넘길까? |
| Graduated trust spectrum | 고정된 권한 레벨인가, 시간에 따라 이동하는 스펙트럼인가? |
| Defense in depth | 단일 안전 경계인가, 여러 겹의 중첩 경계인가? |
| Context as scarce resource | 단일 패스 잘라내기인가, 점진적 파이프라인인가? |
| Append-only durable state | 가변 상태인가, 스냅샷인가, 추가 전용(append-only) 로그인가? |
| Minimal scaffolding, maximal harness | 스캐폴딩에 투자할까, 운영 인프라에 투자할까? |
| Values over rules | 경직된 절차인가, 결정론적 가드레일을 갖춘 맥락적 판단인가? |
| Isolated subagent boundaries | 서브에이전트가 컨텍스트와 권한을 공유하는가, 격리되는가? |
여기에 더해 저자들은 여섯 번째 관점인 장기 역량 보존(Long-term Capability Preservation) 을 평가의 렌즈로 도입합니다. 이는 동등한 설계 가치라기보다, 단기적 역량 증폭이 장기적인 인간 이해도, 코드베이스 일관성, 개발자 양성 파이프라인을 희생하지 않는지를 가로지르며 묻는 질문입니다. 이 관점이 중요한 이유는 뒤에서 다시 다룹니다.
아키텍처 개요: 7개 컴포넌트와 4가지 설계 질문
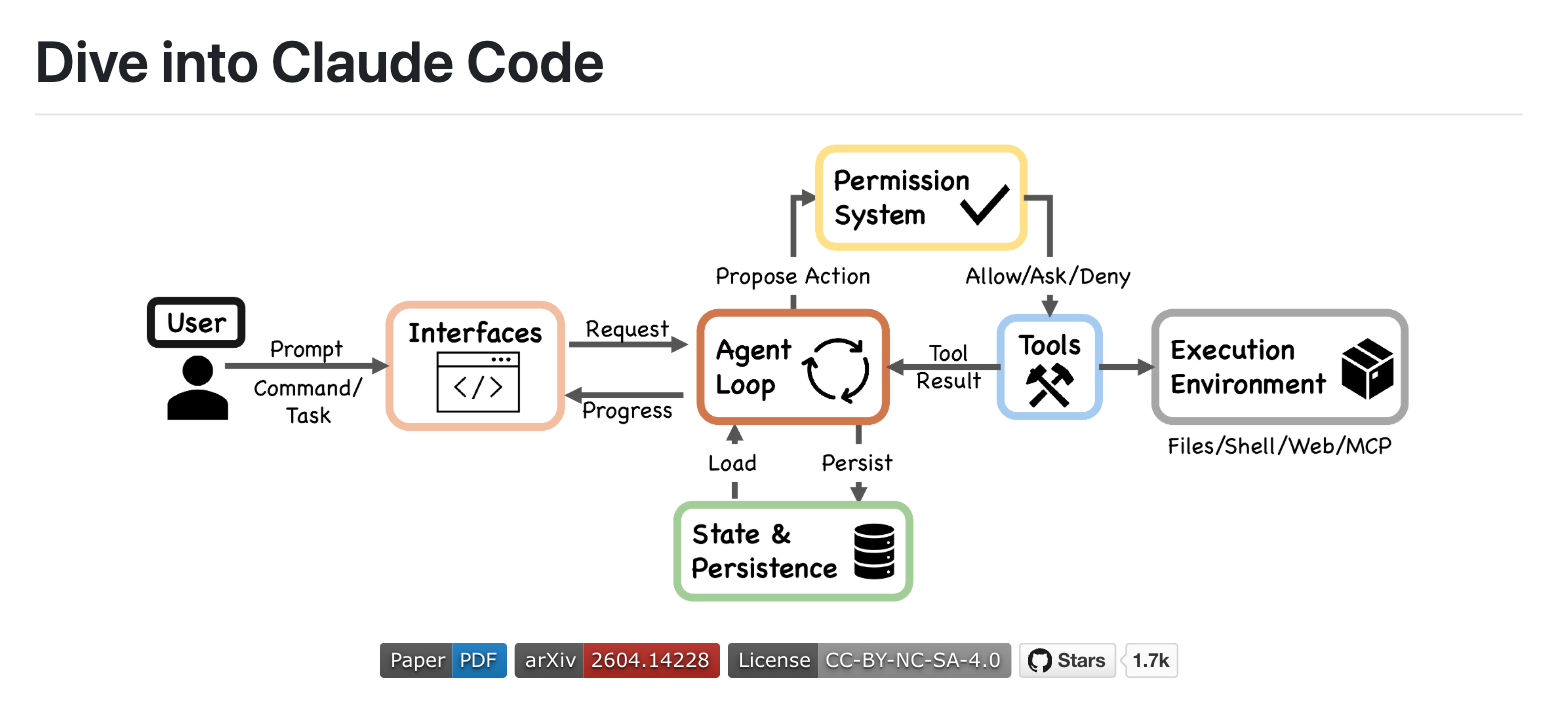
구현 수준에서 시스템은 하나의 주 데이터 흐름으로 연결된 7개 컴포넌트로 나뉩니다. 사용자가 여러 인터페이스 중 하나를 통해 프롬프트를 제출하면, 이것이 공유된 에이전트 루프로 들어갑니다. 루프는 컨텍스트를 조립하고 모델을 호출하며, 도구 사용 요청이 포함된 응답을 받아 이를 권한 시스템으로 라우팅하고, 승인된 행동을 실제 도구로 보내 실행 환경과 상호작용합니다. 그 과정 내내 상태 및 지속성 메커니즘이 대화 기록을 남기고 세션 정체성을 관리하며 재개(resume), 분기(fork), 되감기(rewind)를 지원합니다.
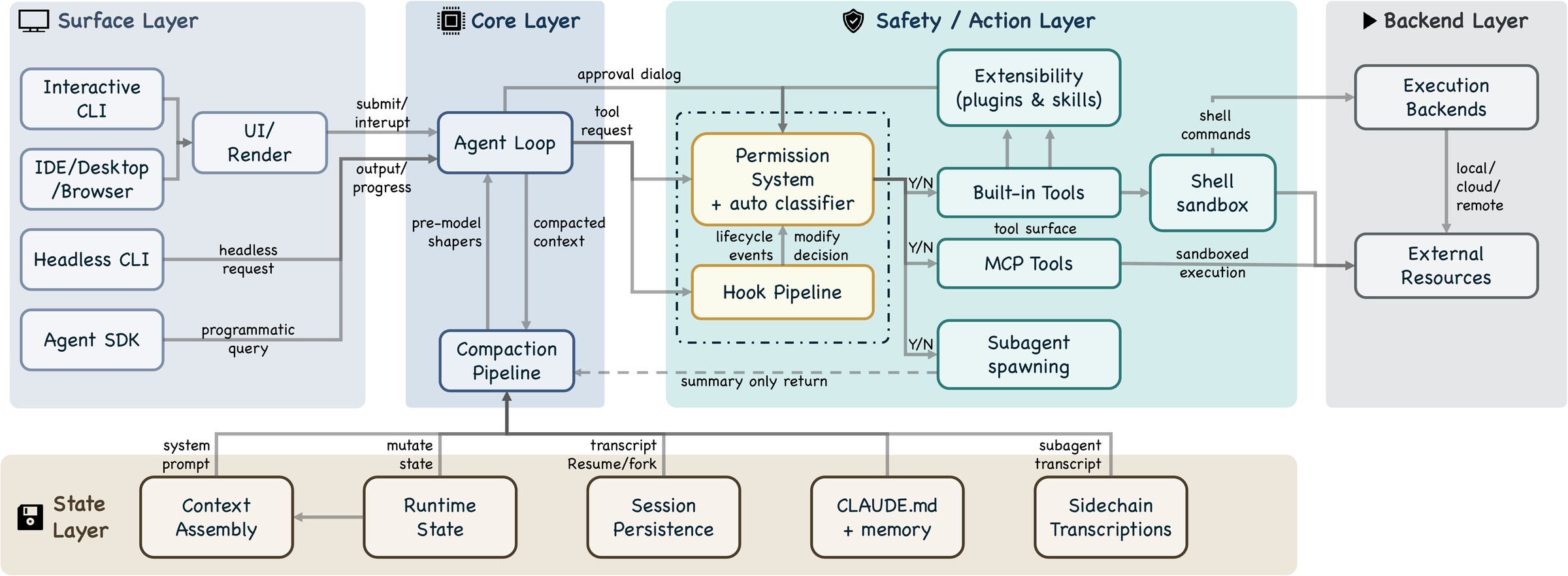
이 7개 컴포넌트 모델은 다시 다섯 개의 서브시스템 계층으로 확장되며, 각 계층은 구체적인 소스 디렉토리에 대응합니다. 표면 계층(surface)은 진입점과 렌더링을, 코어 계층(core)은 에이전트 루프와 압축 파이프라인을, 안전/행동 계층(safety/action)은 권한 시스템과 훅, 확장성, 도구, 샌드박스, 서브에이전트 생성을, 상태 계층(state)은 컨텍스트 조립과 세션 지속성, 메모리를, 백엔드 계층(backend)은 실행 백엔드와 외부 자원을 담당합니다.
저자들은 이 아키텍처를 네 가지 반복 설계 질문에 대한 답으로 읽습니다.
- 추론은 어디에 사는가? 모델이 추론하고 하네스가 집행합니다. 앞서 본 1.6\% 대 98.4\% 의 비율이 이 답을 정량적으로 보여줍니다.
- 실행 엔진은 몇 개인가? 단 하나입니다. 대화형 터미널이든 헤드리스 CLI든 Agent SDK든 IDE 통합이든, 모두 동일한
queryLoop()함수를 거칩니다. 오직 렌더링과 사용자 상호작용 계층만 달라집니다. - 기본 안전 태세는 무엇인가? Deny-first에 인간 에스컬레이션을 더한 방식입니다. deny 규칙이 ask 규칙을, ask 규칙이 allow 규칙을 이깁니다. 인식되지 않은 행동은 조용히 허용되는 대신 사용자에게 올라갑니다.
- 구속하는 자원 제약은 무엇인가? 컨텍스트 윈도우입니다(구형 모델은 200K, Claude 4.6 계열은 1M 토큰). 모든 모델 호출 전에 다섯 가지 컨텍스트 축소 전략이 실행됩니다.
이 글은 논문을 따라 하나의 작업, "auth.test.ts의 실패하는 테스트를 고쳐줘" 를 각 섹션에 꿰어 추적합니다. 이 단순해 보이는 요청 하나가 도구 호출, 권한 검사, 컨텍스트 선택, 반복적 수정, 위임, 세션 지속성이라는 여러 아키텍처 계층을 어떻게 활성화하는지 보면 시스템의 동작이 구체적으로 잡힙니다.
에이전트 루프: 단순한 while 루프 한 바퀴
사용자가 "auth.test.ts의 실패하는 테스트를 고쳐줘"를 입력하면, 입력은 반응형(reactive) 루프로 들어갑니다. 이 루프는 ReAct 패턴 을 따릅니다. 모델이 추론과 도구 호출을 생성하고, 하네스가 행동을 실행하며, 결과가 다음 반복으로 피드백됩니다.
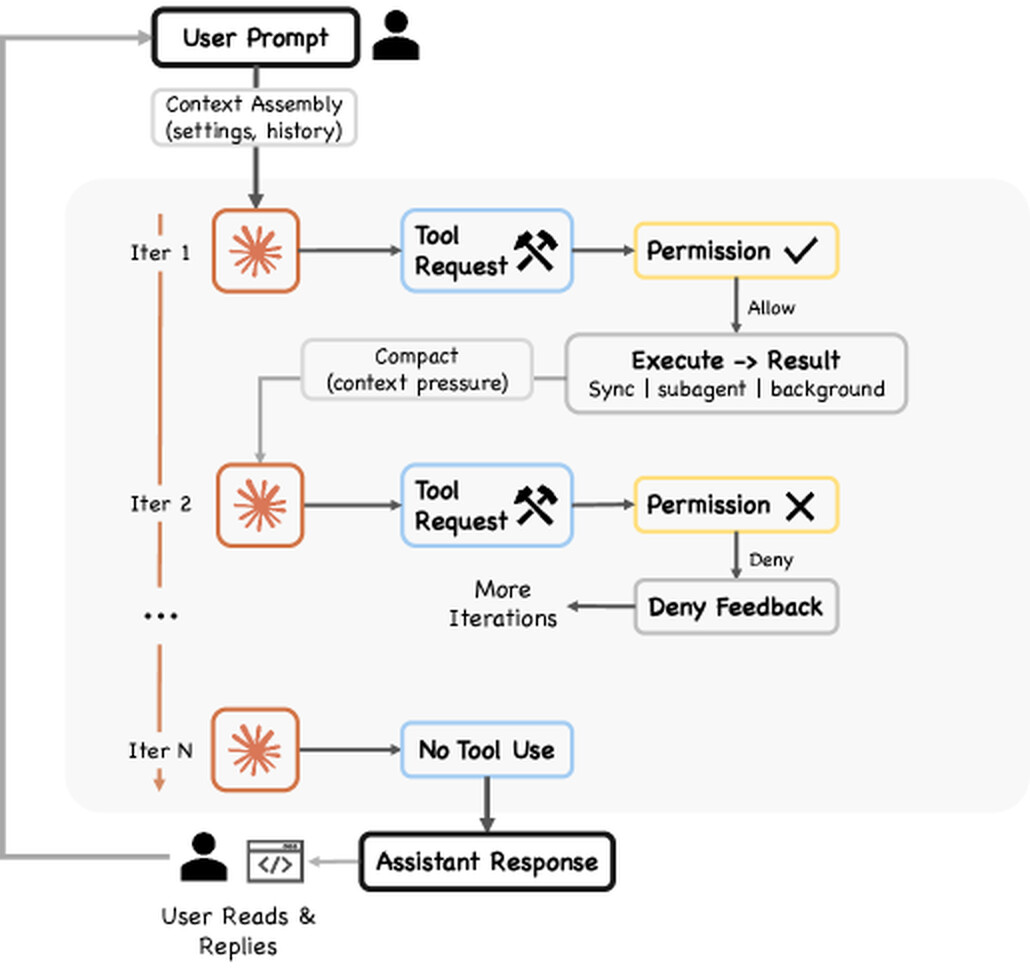
각 턴은 query.ts에 정의된 고정된 9단계 시퀀스를 따릅니다.
- 설정 해석:
queryLoop()함수가 시스템 프롬프트, 사용자 컨텍스트, 권한 콜백, 모델 구성 같은 불변 파라미터를 구조 분해합니다. - 가변 상태 초기화: 단일
State객체가 반복 간의 모든 가변 상태를 저장합니다. 루프의 일곱 개 continue 지점은 각 필드를 개별로 변경하는 대신 객체 전체를 한 번에 통째로 대입합니다. - 컨텍스트 조립: 마지막 압축 경계 이후의 메시지를 가져와, 압축된 내용은 원본 대신 요약으로 표현되게 합니다.
- 모델 호출 전 컨텍스트 셰이퍼: 다섯 개의 셰이퍼가 순차 실행됩니다(아래 컨텍스트 섹션 참고).
- 모델 호출:
for await루프가 모델 응답을 스트리밍하며 조립된 메시지, 시스템 프롬프트, 사고(thinking) 구성, 사용 가능한 도구 집합 등을 전달합니다. - 도구 사용 디스패치: 응답에
tool_use블록이 있으면 도구 오케스트레이션 계층으로 흐릅니다. - 권한 게이트: 각 도구 요청이 권한 시스템을 통과합니다.
- 도구 실행 및 결과 수집: 결과가
tool_result메시지로 대화에 추가되고 루프가 계속됩니다. - 종료 조건: 응답에
tool_use블록이 없으면(텍스트만 있으면) 턴이 완료됩니다.
흥미로운 점은 도구 실행 방식입니다. 읽기 전용 연산은 병렬로 실행될 수 있지만, 셸 명령처럼 상태를 바꾸는 연산은 직렬화됩니다. StreamingToolExecutor 는 모델 응답에서 도구가 스트리밍되어 들어오는 즉시 실행을 시작해 다중 도구 응답의 지연을 줄입니다. 다만 결과는 도구가 받아진 순서대로 버퍼링되어 방출됩니다. 모델이 자신의 도구 사용 요청과 같은 순서로 결과를 기대하기 때문입니다. 이 "병렬 읽기, 직렬 쓰기" 모델은 완전 직렬 디스패치와, 미래의 도구 호출을 미리 추측 실행하는 PASTE 같은 공격적 추측 방식 사이의 중간 지점을 차지합니다.
루프는 또한 여러 복구(recovery) 메커니즘을 갖추고 있습니다. 출력 토큰 상한에 도달하면 한도를 높여 재시도하고(턴당 최대 3 회), 컨텍스트가 가득 차면 반응형 압축으로 공간을 확보하며, prompt_too_long 오류가 나면 먼저 컨텍스트 축소와 반응형 압축을 시도한 뒤에야 종료합니다. 즉 시스템은 오류에 곧바로 실패하는 대신 조용히 복구를 시도하고, 인간의 주의는 정말로 복구 불가능한 상황을 위해 아껴 둡니다.
권한과 안전: Deny-first 방어 심층화
Claude가 도구를 실행하기로 결정하면(예를 들어 npm test 를 실행해 테스트 실패를 재현하려 하면) 그 요청은 권한 파이프라인으로 들어갑니다. 모든 도구 호출은 권한 시스템을 통과하며, 기본 동작은 조용히 허용하는 것이 아니라 거부하거나 묻는 것입니다.
이 기본값을 정당화하는 것은 문서화된 행동 패턴입니다. Anthropic의 자동 모드 분석에 따르면 사용자들은 권한 프롬프트의 약 93\% 를 승인합니다. 이는 승인 피로(approval fatigue) 때문에 대화형 확인이 단독 안전 메커니즘으로서는 행동적으로 신뢰할 수 없음을 뜻합니다. 사용자가 습관적으로 검토 없이 승인하므로, 시스템은 인간의 주의력과 무관하게 안전을 유지해야 합니다.
권한 시스템에는 7가지 모드 가 있습니다.
plan: 모델이 계획을 세워야 하고, 사용자 승인 후에만 실행이 진행됩니다.default: 표준 대화형 사용. 대부분 연산이 사용자 승인을 요구합니다.acceptEdits: 작업 디렉토리 내 편집과 일부 파일시스템 셸 명령은 자동 승인되고, 그 외 셸 명령은 승인을 요구합니다.auto: ML 기반 분류기가 빠른 경로 검사를 통과하지 못한 요청을 평가합니다.dontAsk: 프롬프트는 없지만 deny 규칙은 여전히 집행됩니다.bypassPermissions: 대부분의 권한 프롬프트를 건너뛰지만, 안전 핵심 검사와 우회 불가 규칙은 그대로 적용됩니다.bubble: 서브에이전트가 부모 터미널로 권한을 에스컬레이션하기 위한 내부 전용 모드입니다.
규칙은 deny-first 순서로 평가됩니다. deny 규칙은 더 구체적인 allow 규칙이 있더라도 항상 우선합니다. "모든 셸 명령 거부"라는 넓은 deny는 "npm test 허용"이라는 좁은 allow로 덮을 수 없습니다. 주목할 점은 거부가 단순한 정지가 아니라 라우팅 신호 로 다뤄진다는 것입니다. 분류기나 deny 규칙이 행동을 막으면 모델은 거부 사유를 받고, 접근 방식을 수정해 다음 반복에서 더 안전한 대안을 시도합니다. 즉 권한 집행은 에이전트를 멈추는 것이 아니라 그 행동을 형성합니다.
안전은 여러 독립 계층으로 구성됩니다. 도구 풀 조립 시점에 차단된 도구를 모델의 시야에서 아예 제거하는 사전 필터링, deny-first 규칙 엔진, auto 모드의 ML 분류기, 그리고 Bash/PowerShell 명령에 대한 선택적 셸 샌드박싱이 병렬로 작동합니다. 권한 승인과 샌드박싱은 서로 다른 축(인가 대 격리)에서 동작하므로, 어떤 명령은 권한 승인을 받고도 샌드박스 안에서 실행될 수 있습니다.
하지만 저자들은 이 방어 심층화(defense in depth)가 독립성 가정 에 기대고 있음을 지적합니다. 한 계층이 실패해도 다른 계층이 위반을 잡아낸다는 가정입니다. 그런데 여러 계층이 공통의 성능 제약을 공유합니다. 보안 연구자들은 부분 명령(subcommand)이 50 개를 넘는 명령이 부분 명령별 deny 규칙 검사 대신 단일 일반 승인 프롬프트로 폴백된다는 점을 문서화했습니다. 부분 명령별 파싱이 UI 멈춤을 유발했기 때문입니다. 이는 방어 심층화가 그 계층들이 실패 모드를 공유할 때 함께 무너질 수 있음을 보여줍니다.
더 근본적인 약점은 시간적 순서에 있습니다. 독립 보안 연구는 프로젝트 초기화 중 실행되는 코드(훅, MCP 서버 연결, 설정 파일 해석)가 대화형 신뢰 대화 상자가 사용자에게 표시되기 전에 실행된다는 것을 밝혔습니다. 이 "신뢰 이전(pre-trust)" 실행 창은 deny-first 평가 파이프라인 바깥에 있어, 권한 보장이 아직 적용되지 않는 구조적으로 특권화된 단계를 만듭니다. 실제로 이와 관련된 4개의 CVE가 보고되었으며(모두 공개 후 수 주 내에 패치됨), 이는 확장성이 조합적 복잡도뿐 아니라 초기화 순서를 통해서도 공격 표면을 만든다는 점을 드러냅니다.
확장성: MCP, 플러그인, 스킬, 훅
코딩 에이전트의 반복 설계 질문 하나는 확장 표면을 어떻게 구조화하느냐입니다. 단일 통합 메커니즘인가, 소수의 특화 메커니즘인가, 아니면 서로 다른 컨텍스트 비용을 가진 계층화된 스택인가? Claude Code는 네 가지 메커니즘을 택했고, 각각은 에이전트 루프의 서로 다른 지점에 끼어듭니다. 모든 에이전트 루프에는 세 개의 주입 지점이 있습니다. assemble() 은 모델이 무엇을 보는지를, model() 은 무엇에 닿을 수 있는지를, execute() 는 행동이 실제로 실행되는지와 어떻게 실행되는지를 통제합니다.
왜 하나나 둘이 아니라 넷일까요? 답은 서로 다른 종류의 확장성이 컨텍스트 윈도우에 서로 다른 비용을 부과한다는 관찰에 있습니다. 단일 메커니즘으로는 컨텍스트 비용이 0인 라이프사이클 훅부터 스키마가 무거운 도구 서버까지의 전 범위를 불필요한 트레이드오프 없이 아우를 수 없습니다.
| 메커니즘 | 고유 역량 | 컨텍스트 비용 | 삽입 지점 |
|---|---|---|---|
| MCP 서버 | 외부 서비스 통합(다중 전송) | 높음(도구 스키마) | model(): 도구 풀 |
| 플러그인 | 다중 컴포넌트 패키징 + 배포 | 중간(가변) | 세 지점 모두 |
| 스킬 | 도메인 특화 지시 + 메타 도구 호출 | 낮음(설명만) | assemble(): 컨텍스트 주입 |
| 훅 | 라이프사이클 가로채기 + 이벤트 자동화 | 기본적으로 0 | execute(): 도구 전후 |
이 점진적 컨텍스트 비용 순서(훅은 0, 스킬은 낮음, 플러그인은 중간, MCP는 높음)는 의미가 있습니다. 값싼 확장은 컨텍스트 윈도우를 소진하지 않고 폭넓게 확장될 수 있고, 비싼 확장은 정말로 새로운 도구 표면이 필요한 경우를 위해 아껴집니다. 스킬은 도구를 늘리는 것이 아니라 에이전트가 어떻게 사고하는지 를 최소 비용으로 형성하는데, 전체 내용이 아니라 프론트매터 설명만 프롬프트에 머물기 때문입니다. 훅은 기본적으로 컨텍스트 발자국 없이 도구 호출을 차단, 재작성, 주석할 수 있습니다.
도구 풀 자체는 assembleToolPool() 함수가 조립합니다. 기본 도구 열거(최대 54 개 도구: 19 개는 항상 포함, 35 개는 기능 플래그와 환경 변수, 사용자 유형에 따라 조건부), 모드 필터링, deny 규칙 사전 필터링, MCP 도구 통합, 그리고 이름 기준 중복 제거의 다섯 단계를 거칩니다. 요청 시점에 일부 지연(deferred) 도구는 ToolSearch 로 명시적으로 조회되기 전까지 모델 컨텍스트에서 숨겨질 수 있습니다.
컨텍스트와 메모리: 희소 자원의 점진적 관리
이 시점에서 작업에는 상태가 쌓여 있습니다. 원래 요청, npm test 권한 결과, 조립된 도구 풀, 그동안 모은 파일 읽기와 명령 출력입니다. 이 늘어나는 상태를 다음 모델 호출 전에 어떻게 한정된 컨텍스트 윈도우에 담을까요?
핵심 설계 원칙은 압축 파이프라인의 점진성 입니다. 단일 전략 대신 다섯 계층이 순차로 적용되며, 점점 공격적으로 압축합니다.
Budget reduction(항상 활성): 도구 결과별 크기 한도를 강제하고, 초과 출력은 콘텐츠 참조로 대체합니다.Snip: 오래된 기록 구간을 가볍게 잘라냅니다.Microcompact: 캐시를 인식하는 세밀한 압축으로,tool_use_id기준으로만 동작해 내용을 검사하지 않습니다.Context collapse: 대화 기록 위에 읽기 시점 투영(read-time projection)을 적용합니다. 저장된 기록을 변경하지 않고 모델에게 보이는 뷰만 압축본으로 바꾸므로, 전체 기록은 재구성을 위해 그대로 남습니다.Auto-compact(기본 활성, 비활성화 가능): 모델이 생성한 전체 요약입니다. 앞의 네 셰이퍼를 거친 뒤에도 압력 임계값을 넘을 때만 발동하는 최후의 수단입니다.
이 "점진적 열화(lazy-degradation)" 원칙은 가장 덜 파괴적인 압축을 먼저 적용하고, 값싼 전략이 부족할 때만 더 비싼 전략으로 올라갑니다. 많은 프레임워크가 쓰는 단일 패스 잘라내기나 단일 요약 단계와 대비됩니다. 다만 이 접근의 비용은 복잡성입니다. 다섯 개의 상호작용하는 압축 계층은 사용자가 완전히 예측하기 어려운 동작을 만들고, 특히 context collapse는 사용자에게 보이는 출력 없이 동작합니다.
메모리 쪽에서도 일관된 철학이 보입니다. 저장된 컨텍스트는 사용자가 검사하고 편집할 수 있어야 한다 는 원칙입니다. CLAUDE.md 파일은 구조화된 설정이나 불투명한 데이터베이스 항목이 아니라 평문 마크다운입니다. 사용자는 에이전트가 보는 모든 지시를 읽고, 편집하고, 버전 관리하고, 삭제할 수 있습니다. 이는 표현력 대신 감사 가능성을 택한 트레이드오프입니다. 실제로 시스템은 메모리 검색에 임베딩이나 벡터 유사도 인덱스를 쓰지 않습니다. 대신 메모리 파일 헤더를 LLM으로 스캔해 관련 파일을 최대 5 개까지 선택하며, 항목(entry) 단위가 아니라 파일 단위로 표면화합니다.
CLAUDE.md 는 네 단계 계층으로 로드됩니다. 관리 메모리(OS 수준 정책), 사용자 메모리(~/.claude/CLAUDE.md), 프로젝트 메모리(코드베이스에 체크인됨), 로컬 메모리(gitignore되는 개인 지시)입니다. 한 가지 중요한 구조적 함의가 있습니다. CLAUDE.md 내용은 시스템 프롬프트가 아니라 사용자 컨텍스트(사용자 메시지) 로 전달됩니다. 따라서 이 지시에 대한 모델의 준수는 보장된 것이 아니라 확률적입니다. 결정론적 집행 계층은 어디까지나 deny-first 권한 규칙이 담당합니다. 이렇게 지침(CLAUDE.md, 확률적) 과 집행(권한 규칙, 결정론적) 사이에 의도적인 분리가 만들어집니다.
서브에이전트 위임과 격리
Claude가 auth 테스트 수정을 위해 먼저 인증 모듈의 구조를 탐색해야 한다고 판단하면, 이 탐색을 서브에이전트에게 위임할 수 있습니다. 위임 메커니즘은 Agent 도구이며(Task 는 레거시 별칭으로 유지), 모델은 위임 프롬프트, 선택적 서브에이전트 유형, 격리 모드, 권한 오버라이드, 작업 디렉토리 구성을 담은 구조화된 입력으로 호출합니다.
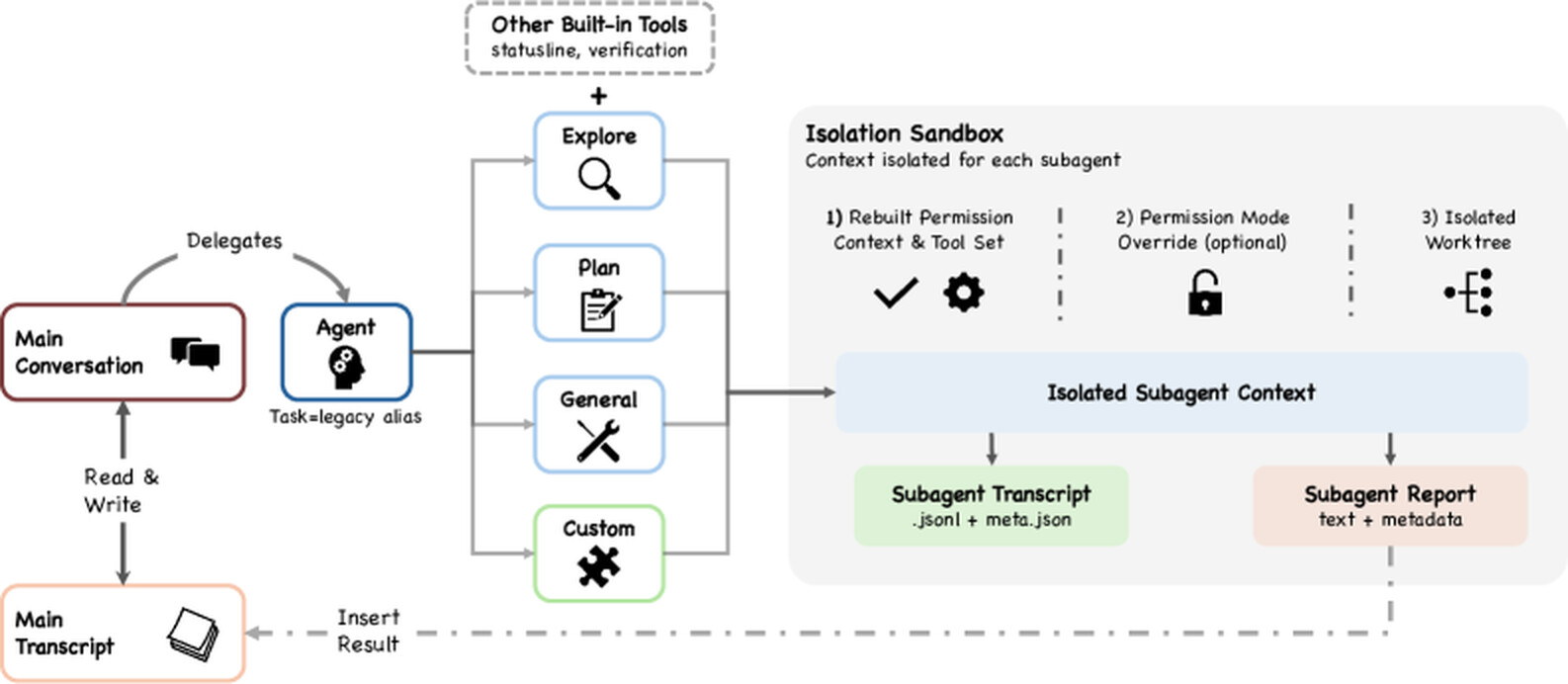
Claude Code는 기능 플래그와 진입점에 따라 최대 6종의 내장 서브에이전트를 제공합니다. 읽기/검색 중심의 Explore(쓰기와 편집 도구는 deny 목록에 있음), 구조화된 계획을 세우는 Plan, 폭넓게 유능한 General-purpose, 온보딩을 돕는 Claude Code Guide, 검증을 실행하는 Verification, 그리고 터미널 상태줄 설정에 특화된 Statusline-setup 입니다. 내장 외에도 사용자는 .claude/agents/*.md 파일로 커스텀 서브에이전트를 정의할 수 있고, 마크다운 본문이 그 에이전트의 시스템 프롬프트가 됩니다. 이렇게 정의된 커스텀 에이전트는 자체 도구, 모델, 권한, 훅, 메모리 범위, 격리 모드를 가진 완전히 구성된 격리 하위 시스템이 될 수 있습니다.
격리는 세 가지 모드를 지원합니다. Worktree 는 임시 git worktree를 만들어 서브에이전트에게 저장소의 자체 사본을 주어 부모의 작업 트리에 영향 없이 수정하게 합니다. Remote(내부 전용)는 원격 환경에서 항상 백그라운드로 실행됩니다. In-process(기본값)는 파일시스템은 공유하되 대화 컨텍스트는 격리합니다. 이 worktree 기반 격리는 컨테이너 오케스트레이션을 도입하지 않고 Git의 내장 메커니즘을 활용해, 외부 의존성 없이 파일시스템 수준 분리를 제공합니다.
서브에이전트의 핵심 설계는 요약만 반환(summary-only return) 입니다. 각 서브에이전트는 자체 .jsonl 전사(sidechain transcript)를 별도 파일로 기록하지만, 부모 대화로 돌아오는 것은 최종 응답 텍스트와 메타데이터뿐입니다. 전체 서브에이전트 기록은 결코 부모의 컨텍스트 윈도우로 들어오지 않아 "컨텍스트는 병목"이라는 원칙을 지킵니다. 이는 전체 전사를 공유하는 대화 기반 프레임워크가 에이전트 수가 늘수록 겪는 컨텍스트 폭발을 피하기 위한 의도적 선택입니다. 그럼에도 격리된 병렬성은 비용이 큽니다. 플랜 모드의 에이전트 팀은 표준 세션의 약 7\times 토큰을 소비합니다.
세션 지속성과 복구
auth 테스트 작업이 이 단계에 이르면 세션에는 원래 프롬프트, 도구 호출과 결과, 압축 경계, 그리고 인증 모듈 탐색에서 얻은 서브에이전트 요약이 담겨 있습니다. 이 중 무엇이 영구 기록되고, 무엇을 나중에 복구할 수 있을까요?
Claude Code의 지속성은 추가 전용 JSONL 을 따릅니다. 세션 전사는 프로젝트별 경로에 대부분 추가 전용 JSONL 파일로 저장됩니다(명시적 정리 재작성은 예외). 세 개의 지속성 채널이 독립적으로 작동합니다. 세션 전사(세션당 한 파일), 전역 프롬프트 기록(history.jsonl, 위쪽 화살표와 ctrl+r 탐색 지원), 그리고 서브에이전트 사이드체인입니다. 추가 전용 형식은 질의 능력 대신 감사 가능성과 단순성을 택한 선택입니다. 모든 이벤트가 사람이 읽을 수 있고 버전 관리 가능하며 특수 도구 없이 재구성됩니다.
가장 흥미로운 안전 결정은 재개와 분기가 권한을 복원하지 않는다 는 점입니다. --resume 은 전사를 재생해 대화를 재구성하고 fork는 기존 세션에서 새 세션을 만들지만, 어느 쪽도 세션 범위 권한을 복원하지 않습니다. 사용자는 새 세션에서 권한을 다시 부여해야 합니다. 이는 세션을 격리된 신뢰 도메인으로 취급하는 의도적 선택입니다. 이전에 부여된 권한을 재개 시 복원하면 편의는 늘지만, 바뀐 맥락에 오래된 신뢰 결정을 끌고 들어올 위험이 생깁니다. 아키텍처는 암묵적 지속 대신 재부여를 택하며, 사용자 마찰을 "신뢰는 항상 현재 세션에서 확립된다"는 안전 불변식의 비용으로 받아들입니다.
OpenClaw와의 비교: 같은 질문, 다른 답
발견을 보정하기 위해 저자들은 Claude Code를 독립 오픈소스 에이전트 OpenClaw 와 비교합니다. OpenClaw는 약 20여 개의 메시징 표면(WhatsApp, Telegram, Slack, Discord 등)을 내장 에이전트 런타임에 연결하는 로컬 우선 WebSocket 게이트웨이입니다. Claude Code가 단일 저장소 세션에 묶인 CLI 코딩 하네스라면, OpenClaw는 다중 채널 개인 비서를 위한 지속적 제어 평면(control plane)입니다.
비교가 드러내는 것은 두 시스템이 여러 차원에서 정반대 베팅을 한다는 점입니다. Claude Code는 행동마다의 점진적 안전 평가에 투자하고, OpenClaw는 경계(perimeter) 수준의 신원 및 접근 제어에 투자합니다. Claude Code는 에이전트 루프를 아키텍처의 중심에 두고, OpenClaw는 게이트웨이 제어 평면을 중심에 두고 에이전트 루프를 하나의 구성 요소로 임베드합니다. Claude Code의 확장은 단일 컨텍스트 윈도우를 수정하고, OpenClaw의 플러그인은 모든 에이전트에 걸친 공유 게이트웨이 표면을 확장합니다.
이 역전들은 임의적이지 않습니다. 서로 다른 신뢰 모델과 배포 토폴로지에서 따라 나옵니다. 그리고 흥미롭게도 두 시스템은 배타적 대안이 아니라 조합 가능합니다. OpenClaw는 ACP(Agent Client Protocol)를 통해 Claude Code를 외부 코딩 하네스로 호스팅할 수 있습니다. 이는 AI 에이전트의 설계 공간이 평면적 분류가 아니라, 게이트웨이 수준 시스템과 작업 수준 하네스가 서로 쌓일 수 있는 계층적 공간임을 시사합니다.
한계와 시사점: 단기 증폭 대 장기 역량
이 모든 설계 답을 함께 읽으면, 일관된 철학이 드러납니다. 풍부한 결정론적 하네스 안에서의 모델 판단 입니다. 추정된 1.6\% 의 의사결정 로직 비율이 이를 정량적으로 포착합니다. 하네스는 모델의 선택을 제약하는 것이 아니라, 모델이 잘 결정할 수 있는 조건(도구 라우팅, 권한 집행, 컨텍스트 조립, 복구 로직)을 만듭니다. 프런티어 모델들이 코딩 작업에서 실용적 역량이 수렴할수록, 주변 운영 하네스의 품질이 주된 차별점이 됩니다. 에이전트 빌더에게 이는 점점 유능해지는 모델 주위에 계획 스캐폴딩을 더하기보다, 컨텍스트 관리와 안전 계층화, 복구 메커니즘 같은 결정론적 인프라에 투자하는 편이 더 큰 신뢰성 향상을 낳을 수 있음을 뜻합니다.
다만 다섯 가치는 서로를 제약하는 긴장을 낳습니다. 승인 피로 대 보호(authority 대 safety), 성능 대 방어 깊이(safety 대 capability), 확장성 대 공격 표면(adaptability 대 safety), 그리고 속도 대 일관성(capability 대 reliability) 입니다. 특히 마지막 긴장은 구조적 예측으로 이어집니다. 한정된 컨텍스트 윈도우는 에이전트가 전체 코드베이스를 동시에 인식하지 못하게 하고, 서브에이전트 격리는 이를 더 키웁니다. 병렬 에이전트들이 이미 존재하는 해법을 독립적으로 재구현할 수 있기 때문입니다. 따라서 에이전트가 생성한 코드는 전체 코드베이스 가시성 아래 만들어진 코드보다 패턴 중복과 관습 위반 비율이 높을 것으로 아키텍처적으로 예측됩니다.
여기서 여섯 번째 평가 렌즈, 장기 역량 보존 이 다시 등장합니다. 저자들은 인접 시스템에 대한 실증 연구를 인용합니다. 경험 많은 개발자 16 명을 대상으로 한 무작위 대조 시험에서 AI 도구는 개발자를 19\% 더 느리게 만들었지만, 정작 본인들은 20\% 빨라졌다고 인식했습니다. 807 개 저장소에 대한 Cursor 도입 인과 분석은 코드 복잡도가 40.7\% 증가했음을 발견했고, 한 EEG 연구는 LLM 사용자가 AI를 제거한 뒤에도 지속되는 약화된 신경 연결성을 보였다고 보고합니다. 독립 연구에서는 AI 보조 조건의 개발자가 이해도 시험에서 17\% 낮은 점수를 받았습니다. 이 증거들은 Claude Code의 아키텍처를 특정해 겨냥하지는 않지만(한정된 컨텍스트와 도구 사용 루프를 가진 모든 에이전트에 적용됩니다), 단기 역량 증폭과 장기 지속가능성 사이의 긴장이 개인 생산성을 넘어 개발자 양성 파이프라인까지 확장됨을 시사합니다.
저자들은 이를 진단이 아니라 설계 문제로 재구성하자고 제안하며, 미래 에이전트 시스템을 위한 여섯 가지 열린 방향을 제시합니다. 관측 가능성과 평가 사이의 간극(배포된 에이전트의 지배적 실패 모드는 충돌이 아니라 조용한 실수 라는 점), 세션을 넘어서는 메모리와 장기적 동료 관계의 지속, 하네스 경계의 진화(에이전트가 어디서, 언제, 무엇에, 누구와 행동하는가), 세션에서 과학적 연구 프로그램으로의 지평 확장(horizon scaling), 규모에 따른 거버넌스, 그리고 장기 인간 역량을 일급 설계 문제로 다루는 것입니다.
결론적으로 이 논문은 프로덕션 코딩 에이전트가 마주하는 반복 설계 선택지들을 하나의 일관된 설계점으로 정리합니다. 추론이 하네스에 대해 어디에 사는가, 반복 루프를 어떻게 구성하는가, 기본 안전 태세를 무엇으로 둘 것인가, 확장 표면을 어떻게 분할하는가, 컨텍스트를 어떻게 조립하고 압축하는가, 서브에이전트를 어떻게 위임하는가, 세션을 어떻게 지속하는가. Claude Code의 답은 풍부한 운영 하네스 안에서 모델의 자율성을 우선하는 한 점이며, 저자들은 코딩 에이전트가 코어 루프를 커널로 삼고 나머지를 운영체제로 삼는 OS 유사 추상으로 수렴하고 있는지를 묻습니다. 이 글의 분석은 고정된 최적해가 아니라 함께 진화하는 시스템의 한 스냅숏으로 읽혀야 합니다.
 Dive into Claude Code: The Design Space of Today's and Future AI Agent Systems 논문
Dive into Claude Code: The Design Space of Today's and Future AI Agent Systems 논문
Claude Code의 공개 TypeScript 소스 코드를 분석해 그 아키텍처를 기술하고, 다섯 가지 가치와 열세 개 설계 원칙을 구체적 구현 선택으로 추적합니다. 핵심 에이전트 루프는 단순한 while 루프이지만, 대부분의 코드는 권한 시스템, 5계층 압축 파이프라인, 네 가지 확장 메커니즘, 서브에이전트 위임 같은 그 주변 시스템에 있습니다.
 Dive-into-Claude-Code GitHub 저장소
Dive-into-Claude-Code GitHub 저장소
논문 본문과 함께, 에이전트 빌더를 위한 설계 가이드, 커뮤니티 분석 모음, 시스템 간 비교를 정리한 저장소입니다.
더 읽어보기
- ReAct: Synergizing Reasoning and Acting in Language Models
- SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
- OpenHands: An Open Platform for AI Software Developers as Generalist Agents
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다!
로 보내드립니다!
텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()