
문서 레이아웃 분석(DLA, Document Layout Analysis)은 문서 이해 시스템에서 핵심적인 역할을 하지만, 속도와 정확성 간의 절충 문제가 발생합니다. 텍스트와 시각적 특징을 동시에 사용하는 다중 모달(multimodal) 접근 방식은 높은 정확성을 제공하지만, 지연 시간이 길어집니다. 반면, 시각적 정보만을 사용하는 단일 모달(unimodal) 방법은 처리 속도가 빠르지만 정확도가 떨어집니다. 이러한 문제를 해결하기 위해 DocLayout-YOLO를 도입하여 속도와 정확성을 모두 개선할 수 있도록 설계되었습니다.
DocLayout-YOLO 개요
DocLayout-YOLO는 문서 레이아웃 분석을 위한 새로운 YOLO 기반 모델입니다. 이 모델은 문서 구조를 이해하는 데 특화된 사전 학습을 포함하여, 전역에서부터 로컬까지 다양한 스케일의 문서 요소를 인식할 수 있도록 설계되었습니다. 이를 위해 대규모 합성 데이터셋인 DocSynth-300K를 활용하여 다양한 문서 구조를 학습하며, 전역에서 로컬로 적응하는 인식 모듈인 Global-to-Local Controllable Receptive Module (GL-CRM)을 도입해 복잡한 문서 레이아웃에서 뛰어난 성능을 보여줍니다.
DocLayout-YOLO는 기존 다중 모달 및 단일 모달 방식을 결합하여 속도와 정확성 모두를 향상시켰으며, 실시간 응용에 적합한 모델로 발전하였습니다.
DocSynth-300K 데이터셋과 주요 기여
Mesh-candidate BestFit 알고리즘
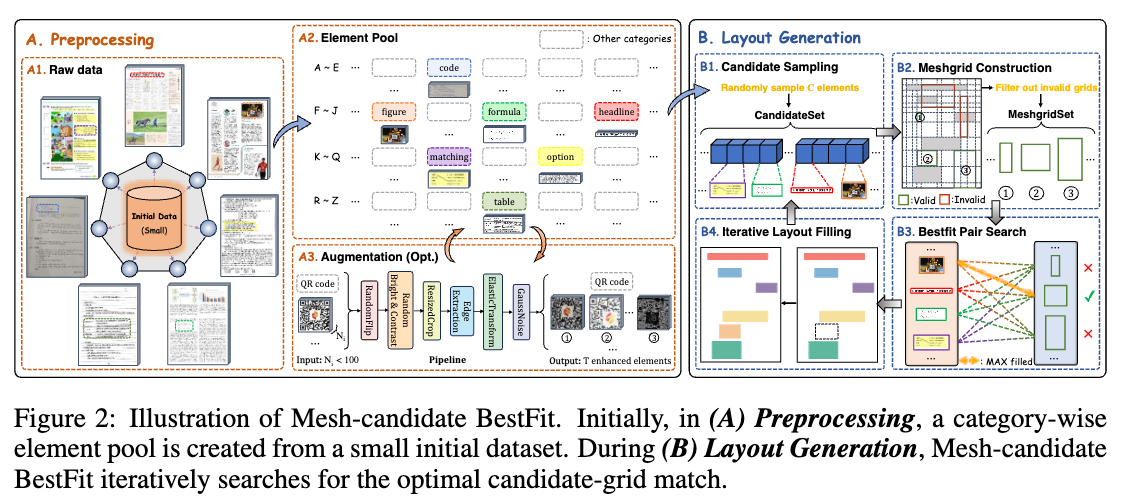
Mesh-candidate BestFit 알고리즘은 문서 내 텍스트, 이미지, 표 등과 같은 문서의 다양한 요소들을 문서 레이아웃에 배치하여 문서를 생성하는 것을 2차원 빈 패킹(2D bin-packing) 문제로 간주하고 최적의 배치를 찾습니다. 이를 통해 대규모 합성 문서 데이터셋인 DocSynth-300K가 생성되었으며, 이 데이터셋은 다양한 문서 레이아웃을 학습하는데 사용합니다.

이 알고리즘은 각 요소가 차지하는 영역을 계산하여 최적의 배치 위치를 찾고, 이를 반복하여 문서의 레이아웃을 생성합니다. 이로써 매우 다양한 형식의 문서 레이아웃을 만들 수 있으며, 실제 문서 레이아웃과 유사한 합성 데이터를 제공하여 모델의 사전 학습에 중요한 역할을 합니다.
이를 통해 생성한 DocSynth-300K를 데이터셋은 다양한 문서 유형에 대해 모델을 사전 학습하여 성능을 크게 향상시킵니다.

Global-to-Local Controllable Receptive Module (GL-CRM)
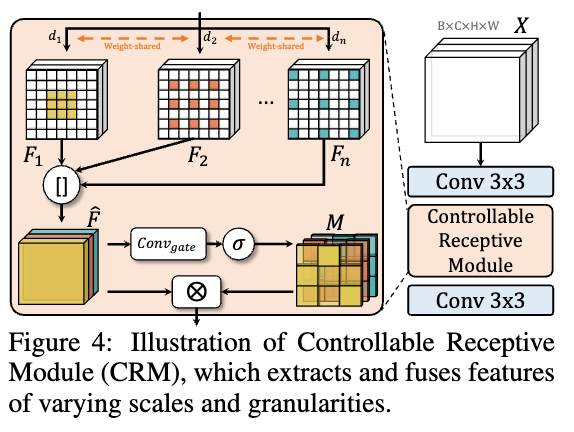
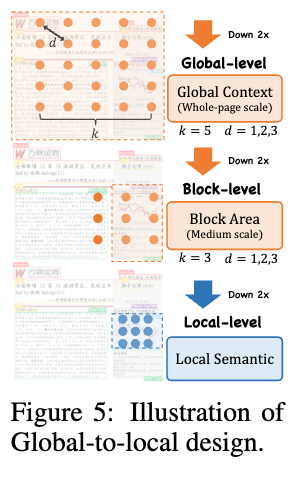
GL-CRM은 문서 내에서 크기가 다양한 요소들을 처리할 수 있도록 설계된 모듈입니다. 문서에는 단일 줄의 제목부터 페이지 전체를 차지하는 표나 이미지까지 다양한 크기의 요소들이 존재합니다. 이러한 다양한 스케일의 요소를 효과적으로 인식하기 위해, GL-CRM은 전역적인 문서 구조를 파악한 후 점진적으로 로컬 정보를 인식하는 계층적 구조를 제공합니다.
이 모듈은 여러 수준의 스케일에서 특징을 추출하고 이를 융합하여 다양한 크기의 문서 요소를 정확하게 감지할 수 있도록 돕습니다. 이를 통해, DocLayout-YOLO는 문서의 전반적인 레이아웃부터 세부적인 텍스트와 이미지까지의 다양한 요소들을 효과적으로 인식 및 분석할 수 있습니다.
DocStructBench 벤치마크
DocStructBench는 DocLayout-YOLO의 성능을 평가하기 위해 개발된 벤치마크로, 다양한 유형의 문서 구조를 포함하고 있습니다. 이 벤치마크는 학술 문서, 교과서, 마케팅 분석 보고서, 금융 문서 등 여러 종류의 문서를 다루며, 실제 환경에서의 모델 성능을 검증하는 데 사용됩니다.
DocStructBench는 복잡한 문서 구조를 포함하고 있어, 모델이 다양한 형식의 문서를 어떻게 처리하는지를 평가하는 데 매우 유용합니다. DocLayout-YOLO는 이 벤치마크에서 뛰어난 성능을 발휘했으며, 특히 다양한 문서 레이아웃을 처리하는 데 있어 기존 모델보다 높은 정확도를 달성했습니다.
실험 및 구현
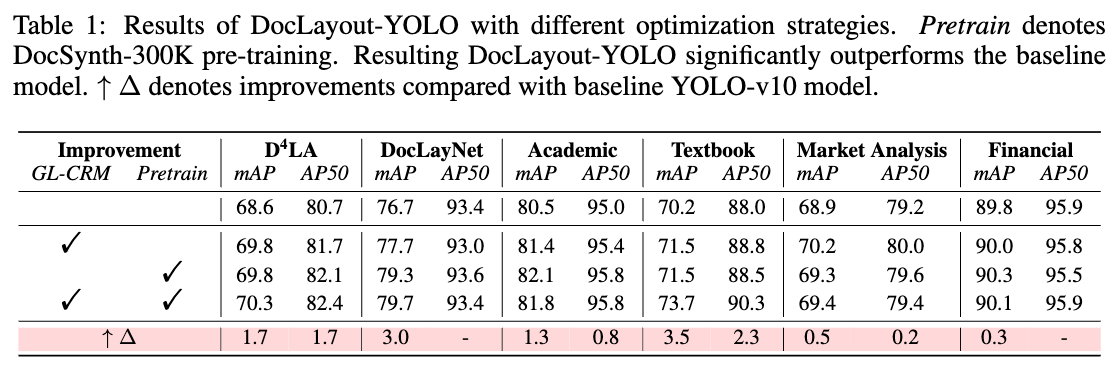
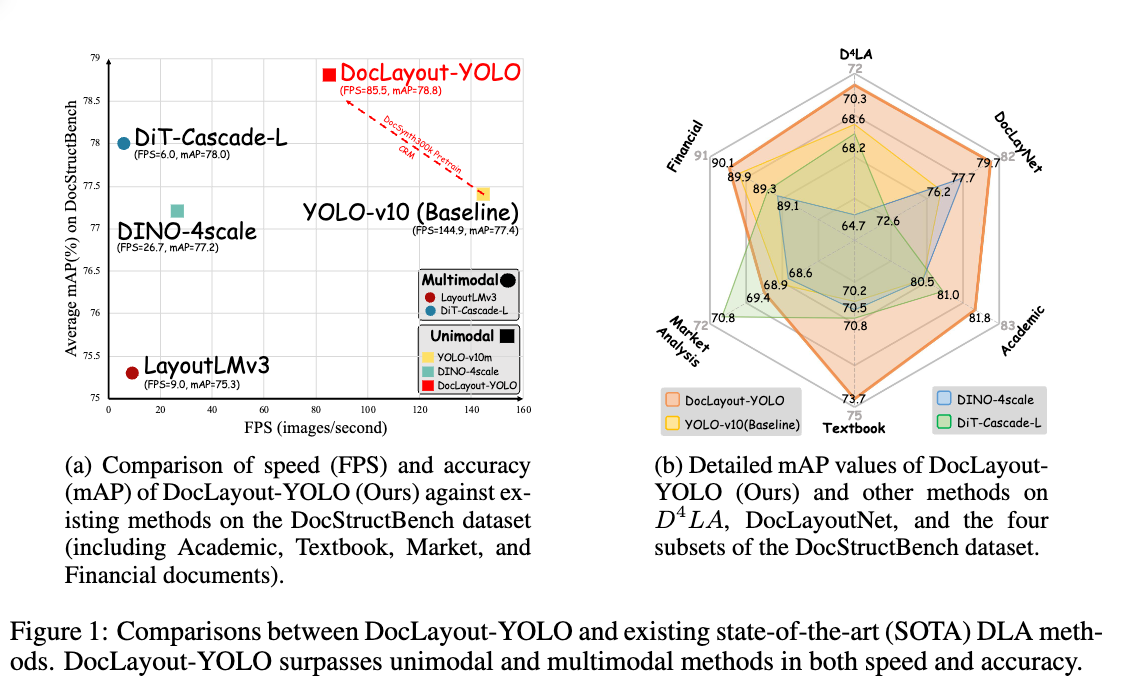
DocLayout-YOLO는 다양한 문서 레이아웃 분석 모델들과 성능을 비교하였습니다. 특히, D^4LA 와 DocLayNet 데이터셋에서 실험한 결과, DocLayout-YOLO는 기존의 YOLO-v10 및 DINO-4scale 모델에 비해 더 높은 정확도와 빠른 처리 속도를 보여주었습니다. 또한, 다중 모달 방식의 LayoutLMv3 및 DiT-Cascade 모델과 비교해도 정확도에서 우위를 점했습니다.
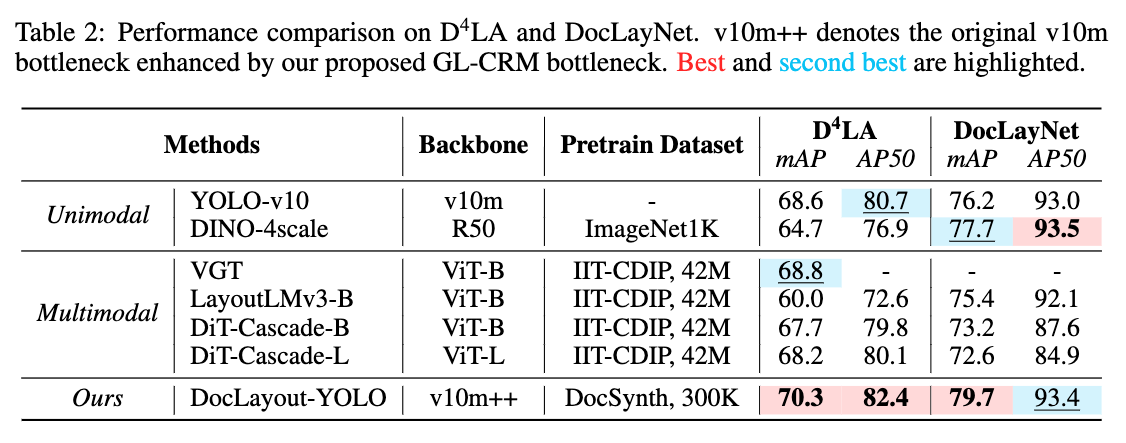
DocLayout-YOLO는 문서의 다양한 구조와 레이아웃을 효율적으로 분석할 수 있으며, 복잡한 문서에서도 정확하고 빠른 성능을 보여줍니다.
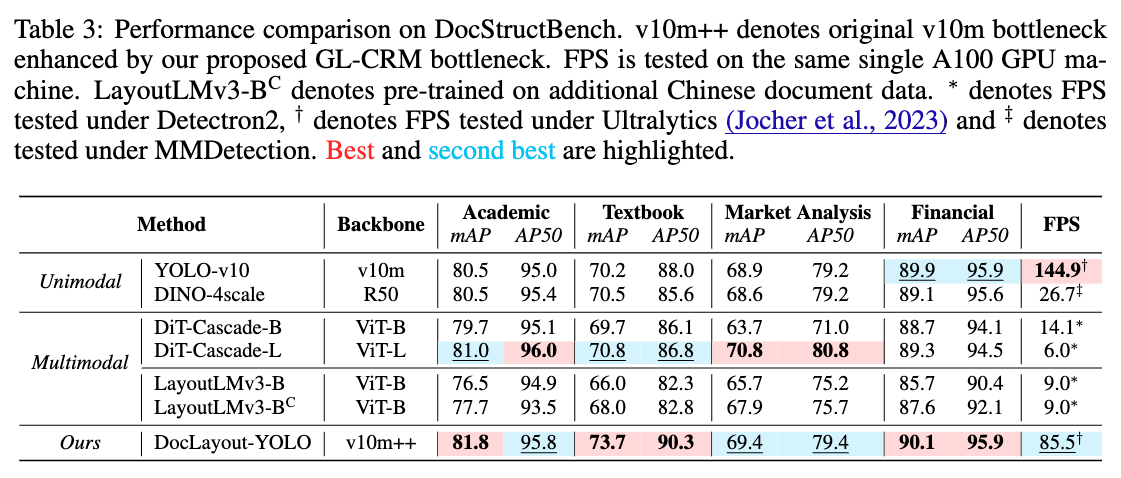
DocLayout-YOLO는 DocSynth-300K 데이터셋을 사용하여 사전 학습을 수행하였으며, 이를 기반으로 다양한 문서 데이터셋에서 뛰어난 성능을 보였습니다. 특히, PubLayNet 및 DocBank와 같은 공개 데이터셋과 비교하여 DocSynth-300K로 학습한 모델이 다양한 문서 레이아웃을 더 효과적으로 처리할 수 있음을 확인했습니다.
DocSynth-300K는 더 다양한 문서 요소와 레이아웃을 포함하고 있어, 문서 레이아웃 분석에서 더 일반화된 성능을 발휘할 수 있도록 도와줍니다.
결론
DocLayout-YOLO는 사전 학습 데이터셋과 모델 최적화를 통해 문서 레이아웃 분석에서 속도와 정확성을 동시에 향상시킨 새로운 모델입니다. 특히, Mesh-candidate BestFit 알고리즘과 GL-CRM을 통해 다양한 문서 레이아웃을 효과적으로 처리할 수 있으며, DocStructBench를 통한 평가에서 우수한 성능을 보였습니다. 이 모델은 실시간 문서 처리에도 적합하며, 다양한 응용 분야에서 사용할 수 있습니다.
 DocLayout-YOLO 논문
DocLayout-YOLO 논문
 DocLayout-YOLO GitHub 저장소
DocLayout-YOLO GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()