
dots.llm1 모델 소개
RedNote HiLab이 발표한 dots.llm1은 전체 파라미터 142B 중 14B만 활성화하는 Mixture-of-Experts(MoE) 구조의 오픈소스 대형 언어 모델입니다. 이 모델은 Qwen2.5‑72B와 비슷한 성능을 유지하면서도 학습/추론 비용은 1/4 수준으로 절감한 것이 특징입니다. 또한, 학습 중간의 체크포인트들과 도커 이미지, vLLM 서버 구성까지 함께 공개되어 있어 LLM 학습에 대한 연구나 모델 튜닝, 효율성 분석 등 다양한 연구에 매우 유용할 것으로 보입니다.
dots.llm1은 RedNote(小红书)가 공개한 최신 LLM으로, 다음과 같은 특징을 갖습니다:
- 142B 규모의 파라미터 중 14B만 활성화 (top-6 + 2 shared MoE)
- 고품질 비합성 웹 데이터 기반 11.2T 토큰 사전학습
- Qwen2.5-72B와 동급의 성능을 달성하면서 GPU 시간은 4배 절감
- 각 토큰마다 다른 전문가를 동적으로 활성화, 높은 계산 효율성과 확장성을 동시에 달성
- 중국어와 영어 모두 대응하는 데이터 구성과 평가 체계
- 32K 컨텍스트 지원을 위한 Long Context 학습까지 완료
또한, 모델과 함께 공개한 기술 문서에는 모델의 아키텍처 뿐만 아니라, 데이터 처리, 학습 스케줄링, MoE 통신 최적화, 체크포인트 설계까지 포괄적으로 다루고 있어 연구자에게 큰 가치가 있습니다. dots.llm1 모델을 최신 다른 모델들과 비교하면 다음과 같습니다:
| 모델 | 총 파라미터 | 활성화 파라미터 | MoE 구조 | GPU 시간 (11T) | 특징 |
|---|---|---|---|---|---|
| dots.llm1 | 142B | 14B | top-6/128 + 2 공유 | 1.46M hrs | 중간 체크포인트 공개 |
| Qwen2.5-72B | 72B | 72B | Dense | 6.12M hrs | 성능 기준 |
| DeepSeek-V3 | 671B | 37B | top-8 + shared | - | 최고 수준 MoE |
| LLaMA3-70B | 70B | 70B | Dense | - | 대표 오픈 dense |
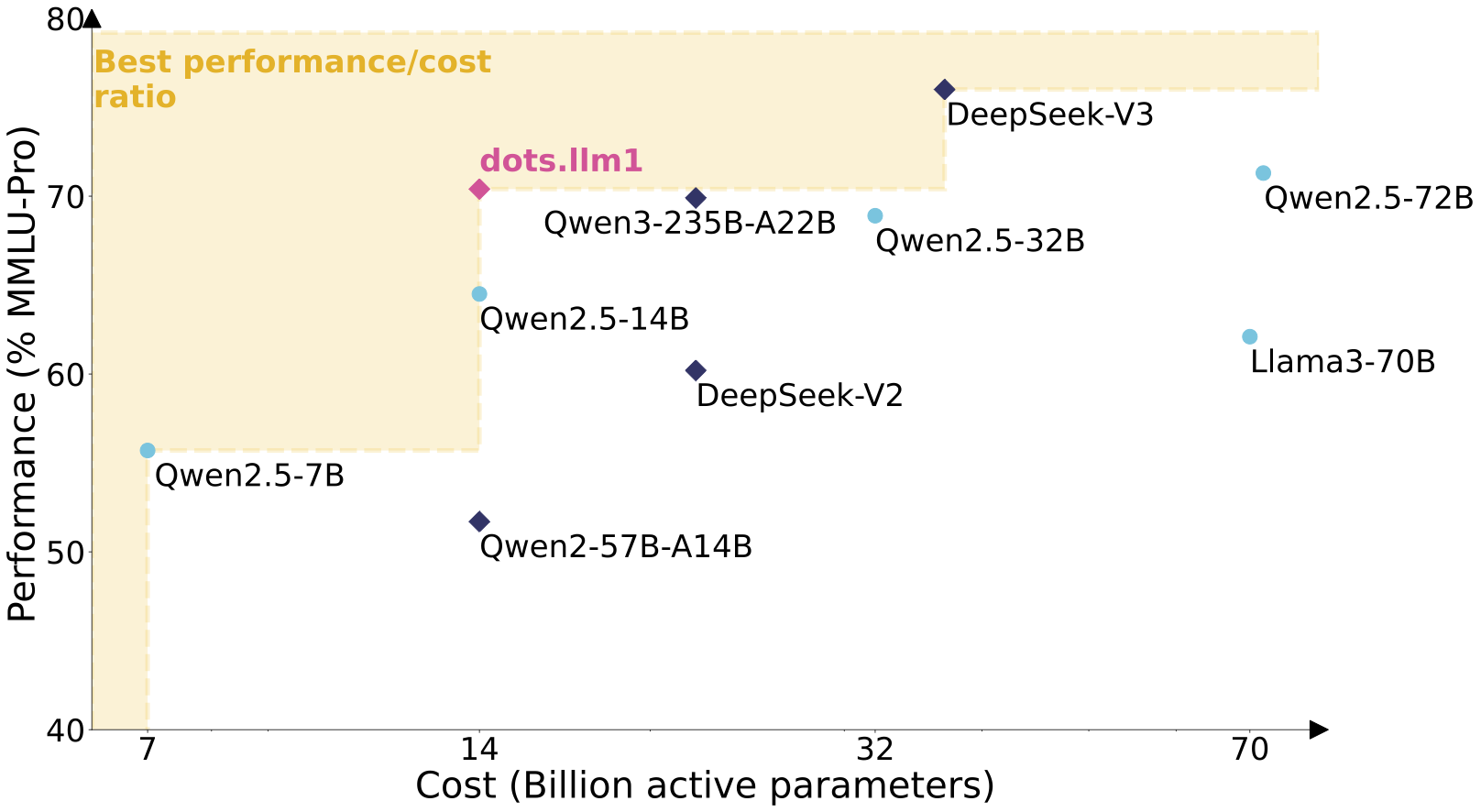
dots.llm1은 적은 활성화 파라미터로도 Qwen2.5‑72B 이상 성능을 보여주는 동시에, DeepSeek-V3와 유사한 수준의 효율성과 구조 안정성을 보여줍니다.
dots.llm1 모델의 주요 특징
모델 구조
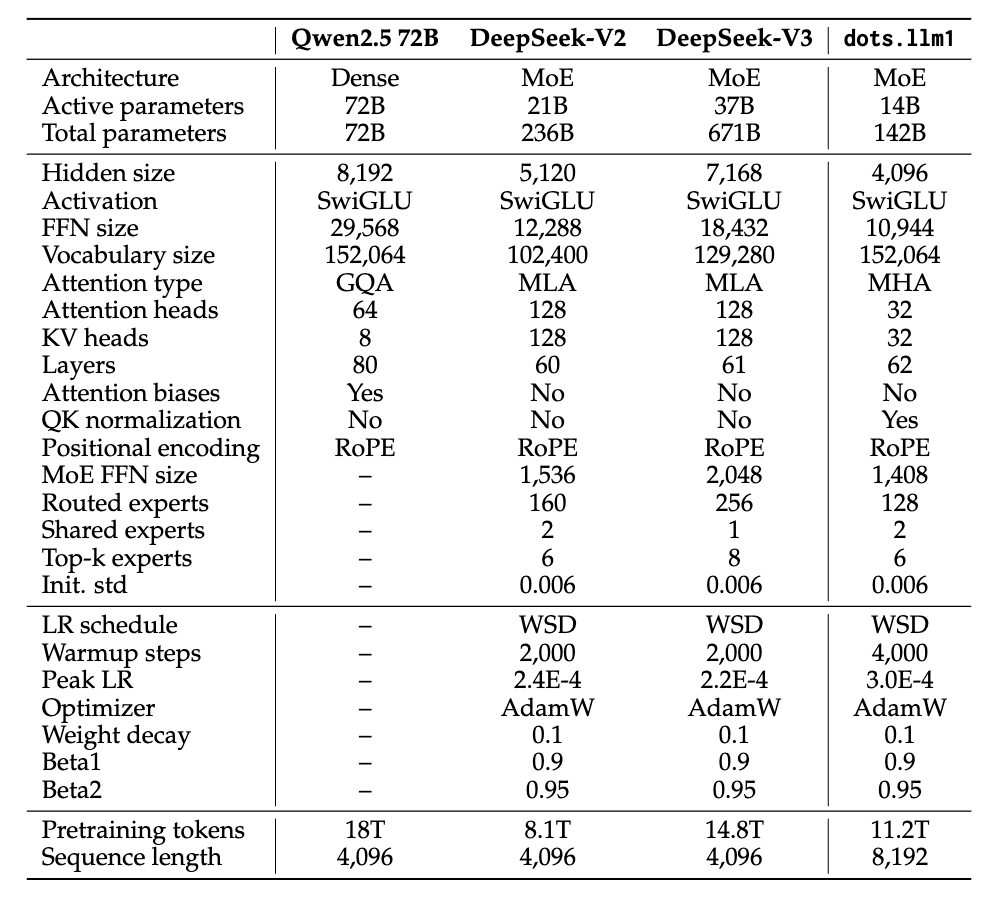
- Decoder-only Transformer , 총 62 레이어
- FFN → MoE로 대체 (128 experts + 2 shared)
- SwiGLU 활성화 함수 , FP32 게이팅 계산으로 정밀한 expert routing
- QK-Norm , RMSNorm , Auxiliary loss-free balancing 로 안정적인 MoE 학습 구현
학습 데이터 파이프라인
- 3단계 전처리: 문서 준비 → 규칙기반 필터링 → 모델 기반 정제
- Web Clutter Removal 모델 사용하여 반복/광고 제거
- 200개 카테고리 기반 분포 조절 로 지식 기반 콘텐츠 우선
- 합성 데이터 미사용 , 중국어:영어 = 1:1 비율 유지
인프라 구조
- Cybertron 프레임워크 (Megatron-Core 기반)
- Interleaved 1F1B 파이프라인, NVIDIA 협업으로 통신과 계산 오버랩 최적화
- Grouped GEMM 최적화로 14% 이상 forward 속도 향상
dots.llm1 모델 사용법
Docker (vLLM 기반)
docker run --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-p 8000:8000 \
--ipc=host \
rednotehilab/dots1:vllm-openai-v0.9.0.1 \
--model rednote-hilab/dots.llm1.inst \
--tensor-parallel-size 8 \
--trust-remote-code \
--served-model-name dots1
Hugging Face Transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
tok = AutoTokenizer.from_pretrained("rednote-hilab/dots.llm1.base")
model = AutoModelForCausalLM.from_pretrained("rednote-hilab/dots.llm1.base", device_map="auto", torch_dtype="bfloat16")
라이선스
dots.llm1 모델 코드는 MIT License로 공개 및 배포되고 있습니다.
 dots.llm1 모델 기술 문서
dots.llm1 모델 기술 문서
 dots.llm1 모델 GitHub 저장소
dots.llm1 모델 GitHub 저장소
https://github.com/rednote-hilab/dots.llm1
 dots.llm1 모델 다운로드
dots.llm1 모델 다운로드
| Model | #Total Params | #Activated Params | Context Length | Download Link |
|---|---|---|---|---|
| dots.llm1.base | 142B | 14B | 32K | |
| dots.llm1.inst | 142B | 14B | 32K |
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()