Dragonfly: 다중 해상도 줌을 갖춘, Llama-3 기반 Vision-Language 모델 (feat. TogetherAI)
소개
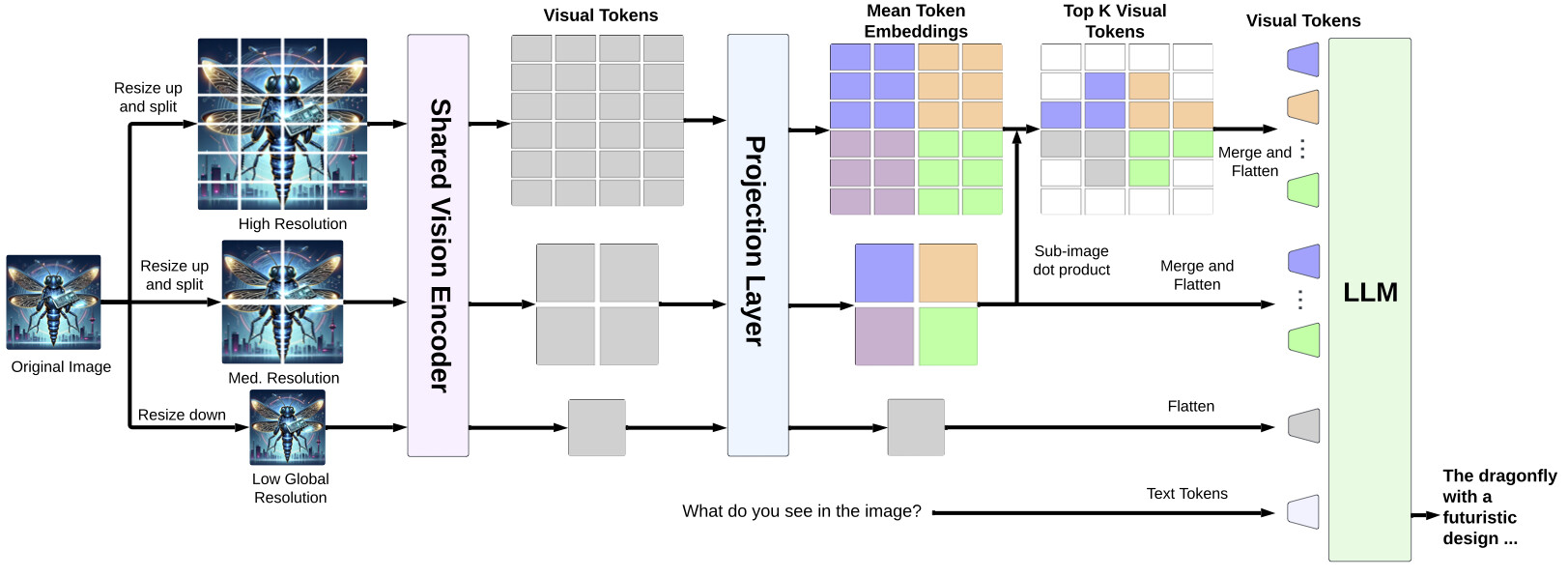
TogetherAI에서 공개한 Dragonfly는 Llama-3 기반의 새로운 비전-언어 아키텍처 모델로, 대규모 멀티모달 모델(LMM)의 발전을 기반으로 한 새로운 아키텍처입니다. 고해상도 이미지가 시각적 세부 사항을 이해하는 데 중요한 역할을 하지만, 고해상도 입력은 언어 모델의 컨텍스트 길이를 연장시켜 비효율을 초래하고, 시각적 특성의 복잡성을 증가시켜 더 많은 훈련 데이터나 복잡한 아키텍처를 필요로 합니다.
이를 해결하기 위해 Dragonfly는 멀티 해상도 시각 인코딩과 줌인 패치 선택이라는 두 가지 주요 전략을 사용합니다. 이러한 전략을 통해 모델은 고해상도 이미지를 효율적으로 처리하면서도 적절한 컨텍스트 길이를 유지할 수 있습니다. Dragonfly는 여덟 가지 인기 벤치마크에서 경쟁력 있는 성능을 보여주며, 생의학 지침에 대한 미세 조정을 통해 다양한 생의학 작업에서 최첨단 결과를 달성했습니다.
기존의 비전-언어 모델들과 비교하여, Dragonfly는 다중 해상도 처리와 선택적 패치 분석을 통해 보다 세밀하고 정확한 이미지 이해를 가능하게 합니다. Dragonfly는 기존의 대규모 시각-언어 모델(LMM)들과 비교했을 때 고해상도 이미지 처리에 있어 뛰어난 성능을 보여줍니다. 예를 들어, Path-VQA 데이터셋에서 92.3%의 정확도를 기록하며 Med-Gemini의 83.3%를 능가합니다. 또한, 생의학 이미지 캡션 작성 등에서 최고 성능을 기록했습니다.
주요 특징
-
멀티 해상도 시각 인코딩: 고해상도 이미지를 처리하여 세밀한 시각적 이해를 제공합니다.
-
줌인 패치 선택: 효율적인 고해상도 이미지 처리를 가능하게 합니다.
-
다양한 벤치마크 성능: 시각적 상식 추론 및 생의학 이미지 분석에서 우수한 성과를 보여줍니다.
-
풍부한 훈련 데이터셋: 550만 개의 일반 도메인 이미지-지시 샘플 및 140만 개의 생의학 도메인 샘플로 구성된 데이터셋을 사용하여 훈련되었습니다.
모델 아키텍처
Dragonfly 모델이 갖는 주요 특징은 다음과 같습니다:
-
드래곤플라이는 멀티 해상도 시각 인코딩과 줌-인 패치 선택이라는 두 가지 주요 전략을 사용합니다. 이를 통해 모델은 이미지 영역의 세밀한 디테일을 더 잘 이해하고 상식적인 추론을 제공합니다. 모델이 세밀한 이미지 디테일을 캡처하도록 최적화되었음에도 불구하고, 표준 이미지 이해 벤치마크에서 좋은 제로 샷 성능을 보입니다.
-
Dragonfly 모델은 고해상도 이미지 영역의 세밀한 이해를 필요로 하는 생물의학 작업에서도 이해 및 추론 능력을 입증합니다. 140만 개의 생물의학 이미지-텍스트 쌍을 포함한 생물의학 지침 튜닝 데이터셋으로 일반 도메인 모델을 미세 조정하여 Drgaonfly-Med 모델은 시각적 질문 응답, 이미지 캡션 생성, 방사선 보고서 생성 등의 여러 생물의학 벤치마크에서 최고 성능을 달성합니다.
Dragonfly 모델 성능 평가
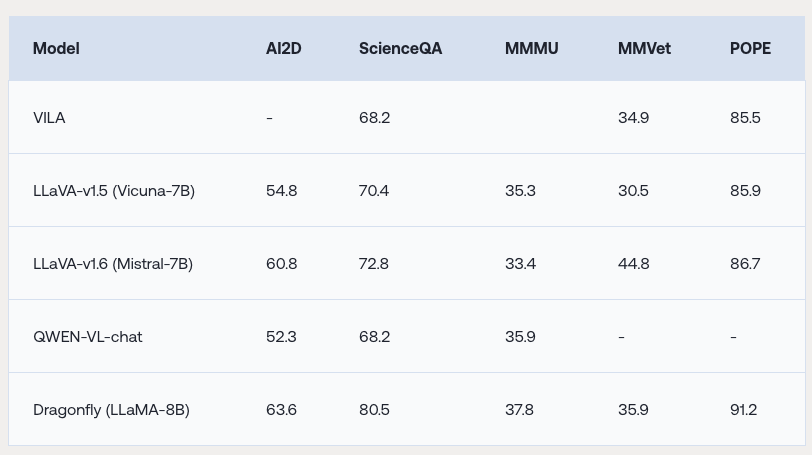
Drgaonfly 모델은 AI2D, ScienceQA, MMMU, MMVet, POPE와 같은 다섯 가지 인기 있는 비전-언어 벤치마크에서 평가되었습니다. 이들 벤치마크는 강력한 상식적 추론과 세부적인 이미지 이해를 요구합니다. 드래곤플라이는 이러한 벤치마크에서 경쟁력 있는 성능을 보였으며, 이미지 영역의 세부 이해와 상식적 추론의 효율성을 입증했습니다.
Dragonfly-Med (의료용) 모델 성능 평가
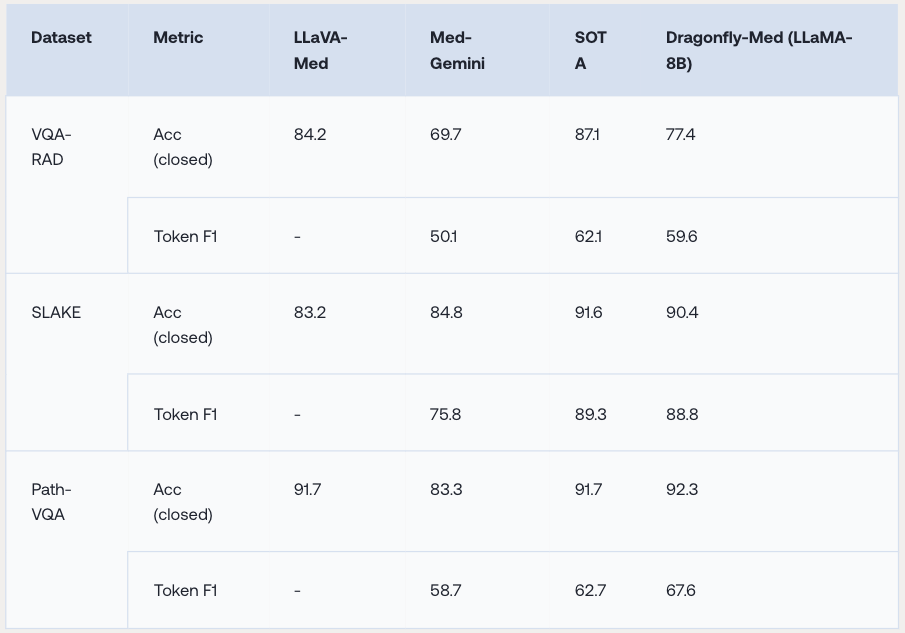
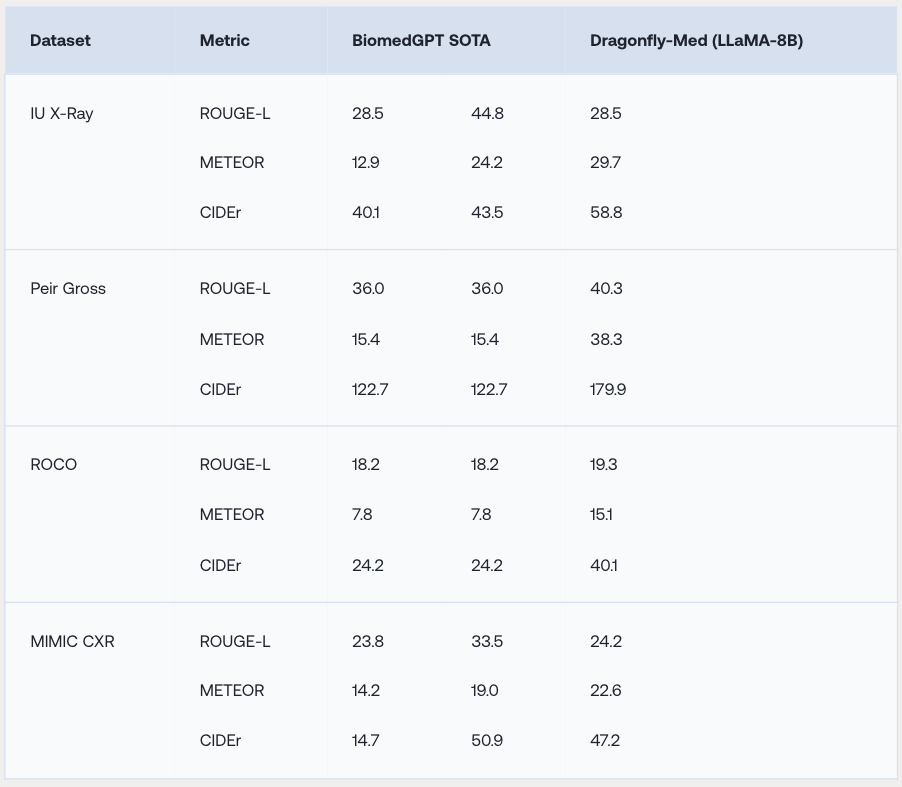
Stanford Medicine의 Zou 그룹과 협력하여 Dragonfly 모델에 추가 140만 개의 생물의학 이미지 지침(instruction-following) 데이터로 미세 조정하여 생물의학 버전인 Dragonfly-Med를 개발 및 함께 공개하였습니다. Dragonfly-Med는 시각적 질문 응답, 의학 이미지 캡션 생성, 임상 보고서 생성 평가에서 Med-Gemini를 능가하며, 여러 벤치마크에서 최고 성능을 달성했습니다.
모델을 사용한 추론 코드 예시
다음은 모델을 사용하여 이미지를 처리하는 예제입니다.
import torch
from PIL import Image
from transformers import AutoProcessor, AutoTokenizer
from dragonfly.models.modeling_dragonfly import DragonflyForCausalLM
from dragonfly.models.processing_dragonfly import DragonflyProcessor
device = torch.device("cuda:0")
tokenizer = AutoTokenizer.from_pretrained("togethercomputer/Llama-3-8B-Dragonfly-v1")
clip_processor = AutoProcessor.from_pretrained("openai/clip-vit-base-patch32")
image_processor = clip_processor.image_processor
processor = DragonflyProcessor(image_processor=image_processor, tokenizer=tokenizer, image_encoding_style="llava-hd")
model = DragonflyForCausalLM.from_pretrained("togethercomputer/Llama-3-8B-Dragonfly-v1")
model = model.to(torch.bfloat16)
model = model.to(device)
image = Image.open("./test_images/skateboard.png")
image = image.convert("RGB")
images = [image]
text_prompt = "<|start_header_id|>user<|end_header_id|>\n\nSummarize the visual content of the image.<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n"
inputs = processor(text=[text_prompt], images=images, max_length=2048, return_tensors="pt", is_generate=True)
inputs = inputs.to(device)
temperature = 0
with torch.inference_mode():
generation_output = model.generate(**inputs, max_new_tokens=1024, eos_token_id=tokenizer.encode("<|eot_id|>"), do_sample=temperature > 0, temperature=temperature, use_cache=True)
generation_text = processor.batch_decode(generation_output, skip_special_tokens=False)
print(generation_text)
라이선스
이 프로젝트는 META LLAMA 3 커뮤니티 라이센스 계약 하에 공개 및 배포되고 있습니다.
 Dragonfly 모델 논문
Dragonfly 모델 논문
 Dragonfly 모델의 GitHub 저장소
Dragonfly 모델의 GitHub 저장소
 Dragonfly 모델의 가중치 저장소
Dragonfly 모델의 가중치 저장소
Dragonfly-Med 모델의 가중치 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()