
Factorio Learning Envionment 연구 소개
최근 인공지능(AI) 기술이 급격히 발전하면서, 대규모 언어 모델(Large Language Models, LLM)이 다양한 분야에서 뛰어난 성능을 보이고 있습니다. 예를 들어, OpenAI의 GPT-4, Anthropic의 Claude, Google DeepMind의 Gemini 같은 모델들은 텍스트 생성뿐만 아니라, 코드 작성, 문제 해결, 논리적 추론 등의 작업에서도 높은 성과를 보이고 있습니다. 이러한 모델들이 발전하면서, AI 연구자들은 단순히 언어를 이해하는 것뿐만 아니라, AI가 실제 환경에서 장기적인 목표를 설정하고, 문제를 해결하며, 실수를 수정할 수 있는지를 테스트하는 것이 중요해졌습니다.
기존에는 AI의 성능을 평가하기 위해 다양한 벤치마크가 사용되었습니다. 예를 들어, 문제 해결 능력을 평가하는 MATH 데이터셋, 코드 생성 능력을 평가하는 HumanEval, 게임 플레이를 평가하는 ALFWorld 같은 것이 있습니다. 하지만 이러한 기존의 평가 방식에는 한 가지 큰 문제가 있습니다. 대부분의 벤치마크는 완료 조건(completion state)이 명확하게 정해져 있기 때문에, AI가 일정 수준 이상 발전하면 더 이상 도전 과제가 되지 않는다는 한계를 가지고 있습니다. 다시 말해, AI가 너무 뛰어나지면 기존의 테스트 환경에서는 성능 차이를 명확히 구분하기 어렵습니다.
이러한 문제를 해결하기 위해 본 논문에서는 새로운 AI 평가 환경인 Factorio Learning Environment(FLE) 를 소개합니다. FLE는 Factorio라는 게임을 기반으로 만들어진 학습 환경으로, AI가 자원을 채굴하고, 공장을 설계하고, 자동화하여 최대한 효율적으로 생산 시스템을 구축하는 능력을 평가하는 데 초점을 맞추고 있습니다. 기존 벤치마크와는 달리, FLE에는 자연스러운 종료 조건이 없으며, AI가 지속적으로 더 나은 자동화 전략을 학습하고 적용할 수 있는지 평가할 수 있다는 점이 특징입니다.
Factorio는 단순한 게임이 아니라, 자원 관리, 장기적 목표 설정, 공간적 최적화, 문제 해결이 모두 결합된 복잡한 환경입니다. AI가 이 환경에서 잘 작동하려면, 장기적인 계획을 세우고, 실수를 수정하며, 점진적으로 더 나은 공장 설계를 학습하는 능력을 갖추어야 합니다. 따라서 FLE는 단순히 “정답이 있는 문제”를 해결하는 것이 아니라, AI가 실제 세계에서와 같이, 복잡한 문제를 스스로 해결하고 최적화할 수 있는지를 평가하는 새로운 기준이 될 수 있습니다.
Factorio 소개 및 Factorio Learning Envionment(FLE) 개요
Factorio는 2016년 출시된 자원 관리 및 자동화 게임으로, 플레이어는 광산에서 원자재를 채굴하고, 이를 가공하여 부품을 만들고, 최종적으로 로켓을 발사하는 공장을 설계해야 합니다. 이 과정에서 플레이어는 단순한 채굴 작업을 넘어, 대규모 생산 시스템을 설계하고 최적화하는 복잡한 문제를 해결해야 합니다. 게임의 목표는 단순하지만, 점점 복잡한 생산 체계를 만들기 위해 장기적인 계획과 논리적 사고가 필수적입니다.
Factorio Learning Environment(FLE)는 이 게임의 특성을 활용하여, AI가 스스로 공장을 설계하고 최적화하는 능력을 평가하는 환경을 제공합니다. 기존의 AI 평가 벤치마크는 대부분 문제 해결 방식이 고정되어 있지만, FLE는 AI가 스스로 새로운 전략을 찾아야 한다는 점에서 더욱 도전적인 환경이 됩니다.
FLE는 크게 두 가지 모드로 구성됩니다. 첫 번째는 Lab-Play(실험실 모드)이고, 두 번째는 Open-Play(자유 모드)입니다.
- Lab-Play(실험실 모드): AI에게 “철광석을 채굴하고 철판을 생산하라”, “플라스틱을 제조하라” 등과 같이 24개의 사전 정의된 자동화 과제를 부여합니다. 이 과제는 명확한 목표를 지시하고 있으며, AI가 제한된 자원과 환경에서 얼마나 효율적으로 목표를 달성하는지를 평가합니다.
- Open-Play(자유 모드): AI가 아무런 목표 없이 자유롭게 공장을 설계할 수 있는 환경으로, 제한된 시간이 주어지며, AI는 가능한 한 가장 큰 공장을 만들도록 학습합니다. 자유모드의 평가 기준은 생산 속도(Production Score, PS)와 기술 연구(Technology Milestones)의 진행 정도입니다.
이러한 구조 덕분에, FLE는 AI가 기존의 “정답이 있는 문제”를 해결하는 방식이 아니라, 스스로 목표를 설정하고 장기적인 계획을 세우는 능력을 평가할 수 있습니다.
Factorio Learning Envionment(FLE)의 구조 및 동작 방식
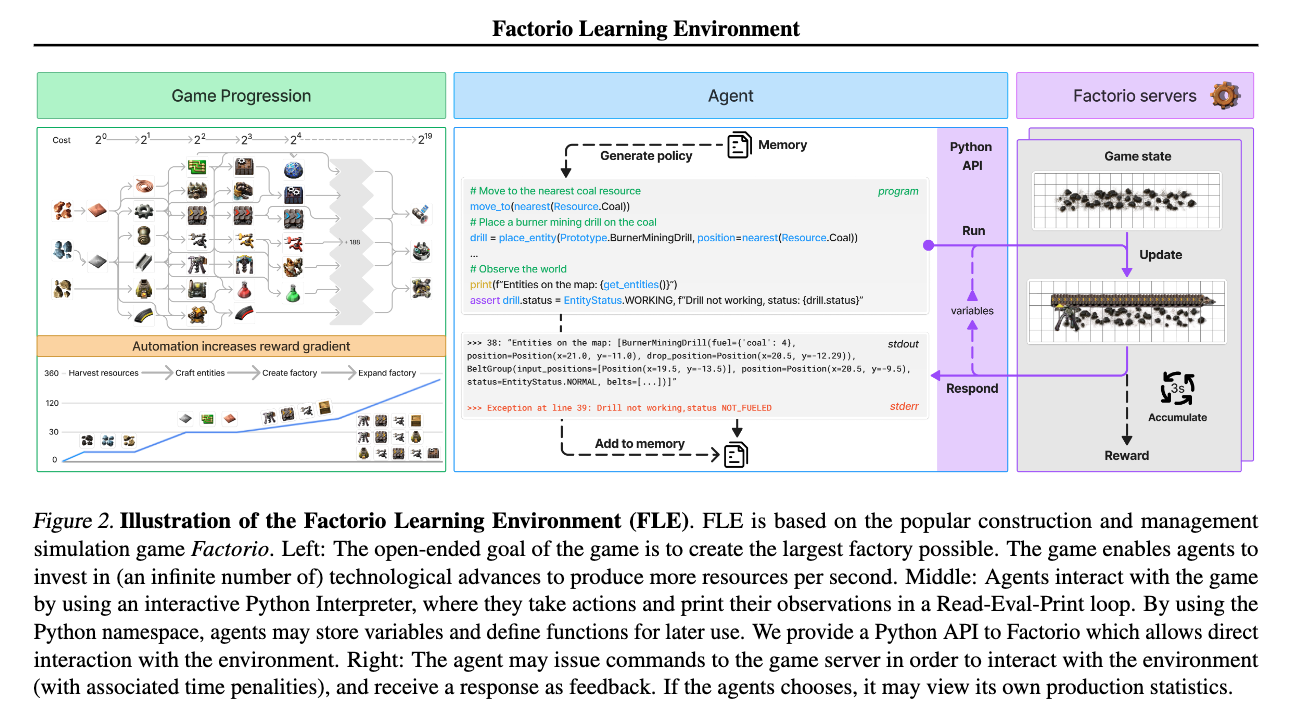

앞에서 살펴본 것처럼, FLE(Factorio Learning Environment)는 AI가 자원을 채굴하고, 공장을 설계하고, 자동화하여 최대한 효율적으로 생산 시스템을 구축하는 능력을 평가하기 위한 환경입니다. 기존 AI 평가 방식은 정해진 문제를 해결하는 것이 목적이지만, FLE에서는 AI가 스스로 전략을 세우고, 시행착오를 통해 학습하며, 장기적인 목표를 달성하는 능력을 테스트할 수 있습니다.
FLE의 역할과 목표
FLE에서 AI의 역할은 Factorio 게임 속에서 인간처럼 공장을 설계하고, 자원을 관리하며, 최적화하는 것입니다. 이를 위해 AI는 Factorio에서 제공하는 다양한 기계와 도구를 활용하여 채굴 → 가공 → 조립 → 대량 생산의 과정을 거쳐 점점 더 효율적인 생산 시스템을 구축해야 합니다.
FLE의 핵심 목표는 다음과 같습니다:
- 자원을 채굴하고, 이를 가공하여 제품을 생산하는 생산 라인을 구축하는 능력 평가
- 공장의 레이아웃을 최적화하여 공간을 효과적으로 활용하는 능력 테스트
- 더 나은 생산 전략을 학습하고, 기존의 실수를 수정할 수 있는지 확인
- 점진적으로 더 복잡한 생산 체계를 설계하고, 연구를 진행하는 능력 측정
AI는 위 목표를 달성하기 위해 Python API를 활용하여 Factorio 환경과 상호작용합니다. 이를 통해 AI는 마치 사람이 코드를 작성하듯이 게임 환경을 분석하고, 명령을 내리며, 피드백을 받아 계획을 수정하는 방식으로 학습합니다.
학습 환경의 단계별 구성
AI가 FLE에서 학습하는 과정은 크게 네 가지 단계로 나누어볼 수 있습니다.
-
1단계: 자원 채굴(Resource Mining): 처음에는 기본적인 자원(철광석, 석탄, 원유 등)을 채굴하는 작업부터 시작합니다. AI는 광산을 자동으로 운영할 수 있는지 테스트되며, 채굴된 자원을 효율적으로 저장하거나 가공할 수 있는지 평가됩니다. 예를 들어, AI는 전기 드릴(Electric Mining Drill)을 사용하여 철광석(Iron Ore)을 자동으로 채굴해야 합니다. 하지만, 이러한 장비를 사용하기 위해서는 에너지원(전기 or 석탄)이 필요하므로, AI는 이를 고려하여 발전기를 먼저 설치해야 합니다.
-
2단계: 자원 가공 및 중간 재료 생산(Material Processing & Intermediate Production): 채굴한 원자재를 바로 사용할 수는 없으므로, 가공하여 새로운 형태로 변환해야 합니다. 예를 들어, 철광석은 용광로(Furnace)에서 가공하여 철판(Iron Plate)으로 변환해야 하는데, AI는 이러한 생산 라인을 자동화하여 생산 효율을 높이는 방법을 학습해야 합니다. 앞의 예시를 구체적으로 살펴보면, AI는 '광산 → 컨베이어 벨트 → 용광로 → 철판 생산 라인'의 생산 과정을 자동화해야 합니다. 이 때, 초기에는 각 단계를 연결하는 수작업(manual 작업)으로 진행할 수도 있지만, 점진적으로 자동화된 시스템을 설계해야 합니다.
-
3단계: 부품 및 제품 조립(Component Assembly & Product Manufacturing): 가공된 재료를 조합하여 더 복잡한 부품을 생산하는 단계입니다. 예를 들어, 철판과 구리판(Copper Plate)을 조합하여 전자 회로(Electronic Circuit)를 제작해야 합니다. AI는 여러 가지 기계를 연결하여 생산 공정을 자동화하는 능력을 테스트받습니다. 컨베이어 벨트를 만들기 위해서는 전자 회로(Electronic Circuit)와 컨베이어 벨트(Conveyor Belt)가 필요한데, 다시 각각의 부품을 생산하기 위해서는 '철판 + 구리판 → 전자 회로(Electronic Circuit)' 및 '전자 회로 + 철판 → 컨베이어 벨트(Conveyor Belt)' 같은 식으로 부품들이 필요합니다. 또한, 여러 부품을 결합하여 더 복잡한 기계(예: 연구소)를 제작할 수 있습니다.
-
4단계: 대량 생산(Mass Production) 및 공장 최적화(Optimization): 마지막 단계에서는 AI가 대규모 생산 시스템을 구축하고, 자원을 최적화하는 능력을 평가합니다. 이 단계에서는 철도 시스템(Train System), 로봇 물류(Logistics Robots), 자동 연구 시스템 등을 활용하여 더 효율적인 생산 체계를 설계해야 합니다. 예를 들어, AI가 연구소를 건설하고, 연구를 진행하여 새로운 기술을 사용할 수 있도록(Unlock) 합니다. 이후 철도를 설치하여 자원을 빠르게 운반하고, 로봇을 활용하여 자동화 수준을 더욱 향상시킵니다.
이러한 과정들을 거치며 AI는 단순한 문제 해결을 넘어서 스스로 계획을 세우고, 최적의 공장 배치를 학습해야 합니다.
Python API 및 실행 방식

FLE는 AI가 직접 게임을 플레이하는 것이 아니라, Python API를 사용하여 Factorio 환경을 제어하는 방식으로 작동합니다. 즉, AI는 코드로 명령을 내려 게임 속 공장을 자동으로 설계하고 운영합니다. FLE(Factorio Learning Environment)는 AI가 직접 마우스와 키보드를 사용하여 게임을 플레이하는 것이 아니라, Python API를 통해 게임 환경을 제어하는 방식으로 작동합니다. 이는 AI가 코드로 명령을 내려 게임 속 공장을 자동으로 설계하고 운영하는 방식을 학습할 수 있도록 하기 위한 것입니다.
AI는 FLE에서 Read-Eval-Print Loop(REPL, 읽기-평가-출력 루프) 방식으로 게임과 상호작용합니다:
-
현재 게임 상태를 확인:
get_entities()와 같은 Python API를 사용하여 현재 게임 상태를 파악합니다. 예를 들어, 공장에 어떠한 기계들이 설치되어 있는지, 공장 내의 모든 기계 상태는 어떠한지, 자원이 충분한지, 현재 생산 속도가 어떠한 지 등을 확인할 수 있습니다. -
행동 계획 및 실행: 파악한 현재 상태를 바탕으로, 무엇을 해야 할지 결정하고, 실행할 명령을 생성합니다. 이 때, Python API를 사용하여 내릴 수 있는 행동은 기계 배치(Placement), 생산 최적화(Optimization), 기술 연구 및 발전(Technology Advancement) 등이 있습니다. 예를 들어, 현재 철광석 채굴 속도가 너무 느리다면
place_entity()와 같은 Python API를 사용하여 새로운 전기 드릴을 추가하는 전략을 선택할 수 있습니다. -
실행 결과 분석 및 오류 수정: 이전의 실행 결과를 다시 분석하여 다음 행동을 결정하고 새로운 전략을 세우는 순환적인 학습 구조를 가집니다. 예를 들어, AI가 컨베이어 벨트를 설치했는데 물류 흐름이 원활하지 않다면 그 원인을 분석해야 합니다.
get_entities()와 같은 Python API를 사용하여 특정 기계 장치의 상태를 파악하고, 실패한 행동을 분석하여 스스로 이를 수정합니다.
이러한 과정이 반복되면서, AI는 점점 더 효율적인 공장을 설계하고, 최적화하는 능력을 키우게 됩니다. 이는 기존 AI 벤치마크와 가장 큰 차이점으로, AI가 단순한 문제 해결이 아닌 “스스로 학습하고 발전하는 과정”을 거친다는 점에서 매우 중요합니다.
FLE에서 다양한 LLM들의 실험 결과
Factorio Learning Environment(FLE)에서 진행된 실험에서는 Claude 3.5, GPT-4o, Deepseek, Gemini-2, Llama 3 등의 최신 대규 언어 모델(LLM)들을 사용하여 공장을 설계하고 자동화하는 능력을 평가했습니다. 실험은 미리 정의된 24개의 자동화 과제를 해결하는 Lab-Play 모드와, AI가 스스로 공장을 확장하는 Open-Play 모드로 나누어 진행되었습니다. 성능 평가는 과제 성공률, 생산 점수(Production Score), 연구 개발 성과를 기준으로 이루어졌습니다.
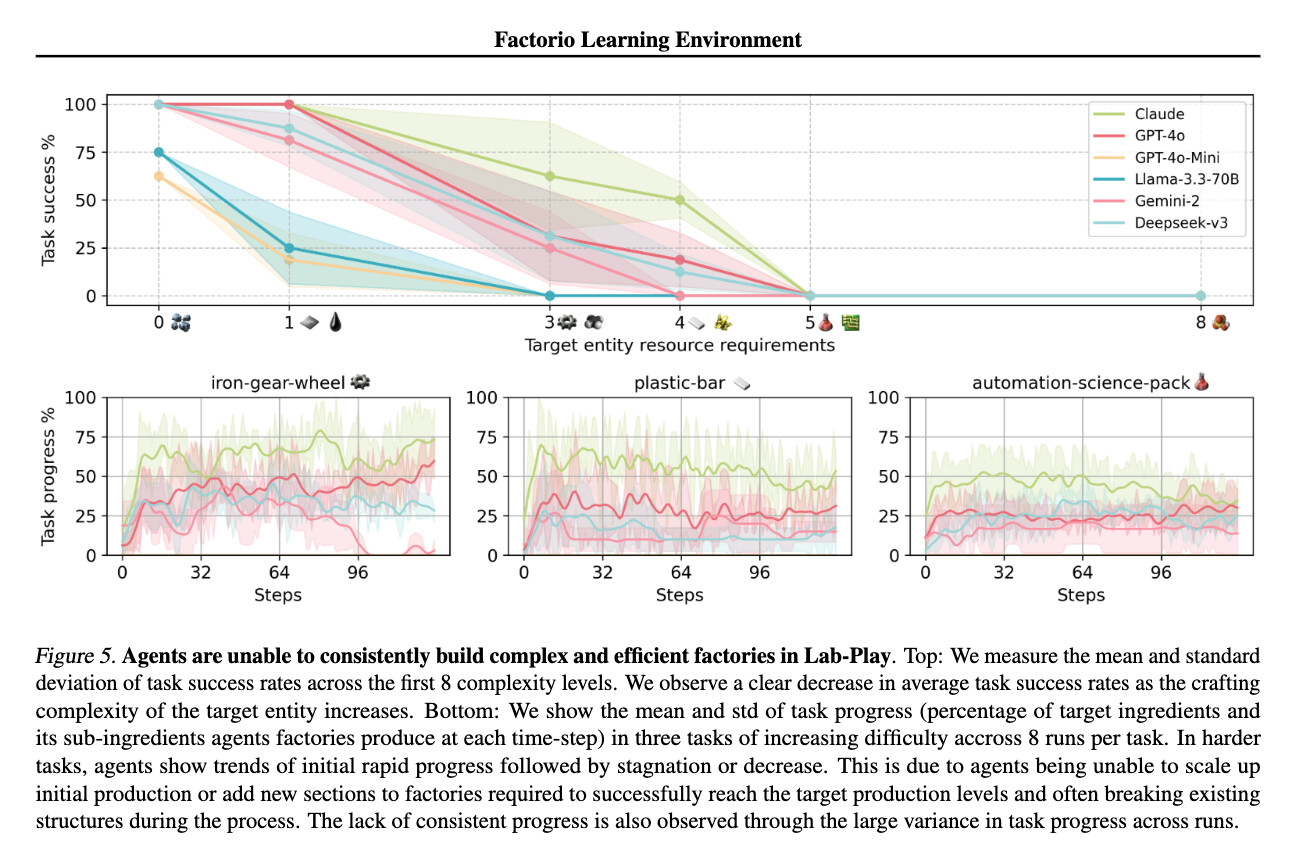
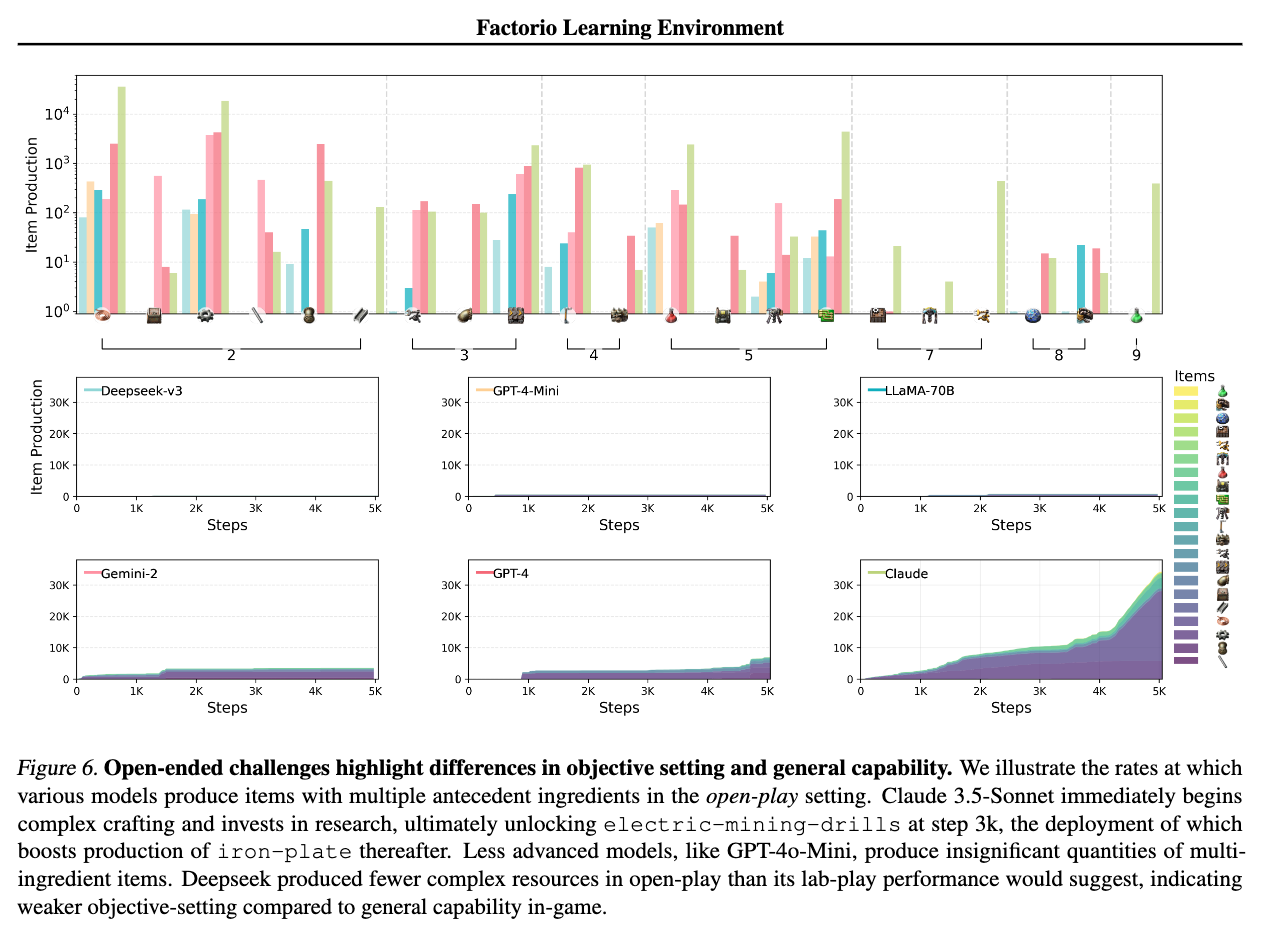
실험 결과, Claude 3.5가 가장 높은 성능을 기록하며, 자동화 과제 해결과 장기적인 생산 최적화에서 우수한 성과를 보였습니다. Open-Play에서 Claude는 최고의 생산 점수(PS 293,206)와 연구 개발 성과(28 milestones)를 기록했으며, 공장 자동화 전략을 지속적으로 개선하는 모습을 보였습니다. 반면, GPT-4o는 초기 생산 라인을 설계하는 데 강했으나, 장기적인 최적화에서 Claude보다 성능이 낮았습니다(PS 162,845, 23 milestones). Deepseek과 Gemini-2는 기본적인 자동화 작업은 수행할 수 있었지만, 다중 재료가 필요한 조립 공정을 효과적으로 구성하는 데 어려움을 겪는 모습을 보였습니다.
공통적으로 모든 모델들이 공간적 추론(Spatial Reasoning)과 장기적인 계획 설정(Long-Term Planning)에 한계를 보였습니다. AI가 컨베이어 벨트, 전력망, 생산 기계를 배치하는 과정에서 비효율적인 설계를 반복하거나, 기존 레이아웃을 효과적으로 활용하지 못하는 문제가 자주 발생하는 것을 확인할 수 있었습니다. 특히 GPT-4o와 Deepseek은 실수를 수정하지 못하고 같은 오류를 여러 번 반복하는 경향을 보였으며, Gemini-2와 Llama 3은 연구 개발 속도가 느려 새로운 기술을 충분히 활용하지 못했습니다.
결과적으로 현재 AI 모델들은 Factorio 환경에서 초기 생산 자동화는 잘 수행하지만, 장기적인 확장과 최적화에는 약점을 보였습니다. 특히, 자원 흐름을 최적화하고, 실수를 인식한 후 수정하는 능력이 부족하다는 점이 실험을 통해 확인되었습니다. 이러한 결과는 FLE가 단순한 문제 해결 능력이 아니라, AI의 장기적인 전략 수립 및 환경 적응 능력을 평가하는 강력한 벤치마크가 될 수 있음을 시사합니다.
결론 및 향후 연구 방향
Factorio Learning Environment(FLE)는 AI가 자원을 관리하고, 공장을 자동화하며, 장기적인 생산 최적화 전략을 학습할 수 있도록 설계된 평가 환경입니다. 기존의 AI 벤치마크는 단기적인 문제 해결 능력을 평가하는 데 초점을 맞췄지만, FLE는 AI가 스스로 계획을 세우고, 환경 변화에 적응하며, 점진적으로 효율성을 높이는 능력을 테스트할 수 있도록 하는 것이 특징입니다. 이번 연구를 통해 Claude 3.5, GPT-4o, Deepseek 등 최신 AI 모델들이 Factorio 환경에서 어떻게 작동하는지 분석하였으며, AI가 기본적인 생산 자동화에는 강하지만, 장기적인 확장과 최적화, 그리고 실수 수정 능력에서는 여전히 한계를 보인다는 점을 확인할 수 있었습니다.
특히, 실험 결과를 통해 AI 모델들이 공간적 추론(Spatial Reasoning)과 장기적 계획 설정(Long-Term Planning)에서 어려움을 겪는다는 점이 명확해졌습니다. 대부분의 모델이 초기 공장 설계는 효과적으로 수행했지만, 점점 복잡한 생산 체계를 구축해야 할 때, 자원 흐름을 최적화하지 못하고 비효율적인 선택을 반복하는 경향을 보였습니다. 또한, AI가 실수를 인식하고 이를 수정하는 과정에서 같은 오류를 여러 번 반복하며, 환경 피드백을 효과적으로 활용하지 못하는 모습도 관찰되었습니다. 이러한 결과는 AI가 Factorio 같은 연속적이고 복잡한 환경에서도 더 나은 의사결정을 내릴 수 있도록 강화학습과 계획 수립 기법을 결합하는 연구가 필요함을 시사하고 있습니다.
결론적으로, FLE는 기존 AI 평가 방식이 다루지 못한 장기적인 문제 해결 능력을 테스트할 수 있는 강력한 벤치마크로 자리 잡을 수 있을 것으로 기대합니다. 향후 연구에서는 AI의 공간적 추론 능력을 강화하고, 실수를 수정하는 능력을 높이며, 보다 복잡한 환경에서도 최적화된 결정을 내릴 수 있도록 하는 새로운 학습 방법이 필요할 것입니다. 이번 연구는 AI가 단순한 문제 해결을 넘어 실제 환경에서도 자율적으로 작동할 수 있도록 발전하는 과정에서 중요한 이정표가 될 것이며, 앞으로도 AI가 더욱 강력한 자동화 및 최적화 능력을 갖출 수 있도록 지속적인 연구가 이루어질 것을 기대합니다.
 Factorio Learning Environment 프로젝트 홈페이지
Factorio Learning Environment 프로젝트 홈페이지
https://jackhopkins.github.io/factorio-learning-environment/
 Factorio Learning Environment 논문
Factorio Learning Environment 논문
 Factorio Learning Environment GitHub 저장소
Factorio Learning Environment GitHub 저장소
https://github.com/JackHopkins/factorio-learning-environment
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()