FlashAttention 돌아보기
어텐션(Attention) 연산은 트랜스포머(Transformer) 구조의 핵심 계층입니다. 하지만 대규모 언어 모델(LLM)을 비롯하여 긴 문맥(long-context)을 활용하는 트랜스포머 구조의 경우, 어텐션 연산 과정은 병목 현상을 일으키는 주요 원인 중 하나입니다.
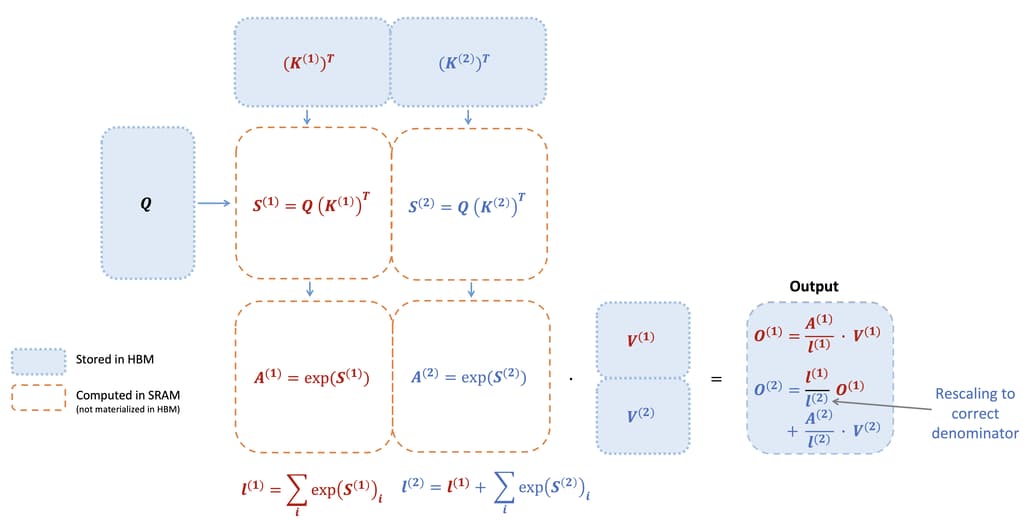
FlashAttention은 어텐션 계산 시 메모리 내에서의 재정렬을 통한 타일링 및 재계산을 활용하여 크게 가속하고 메모리 사용량을 시퀀스 길이에 따라 선형으로 줄이는 알고리즘입니다. 타일링을 사용하여 GPU의 주요 메모리인 HBM에 있는 입력 블록을 더 빠른 캐시로 활용하는 SRAM 영역으로 불러오고, 해당 입력 블록과 관련한 어텐션 연산을 수행하고, 출력을 HBM에 업데이트하는 방식으로 동작합니다.
이러한 어텐션 연산 중간 과정에서 발생하는 큰 어텐션 행렬을 HBM에 저장하지 않음으로써 메모리 읽기/쓰기 양을 줄여 2-4배의 실시간 속도 향상을 가져오는 것이 핵심입니다. 특히, 타일링 및 소프트맥스 재스케일링을 통해 블록 단위로 작업하여 HBM에서 읽기/쓰기 작업을 줄임으로써 전체 연산 시간을 줄이면서도 결과값은 정확하게 일치하는 (= 근사치가 아닌) 출력을 얻을 수 있습니다.
H100 GPU에 최적화한 FlashAttention-3 소개
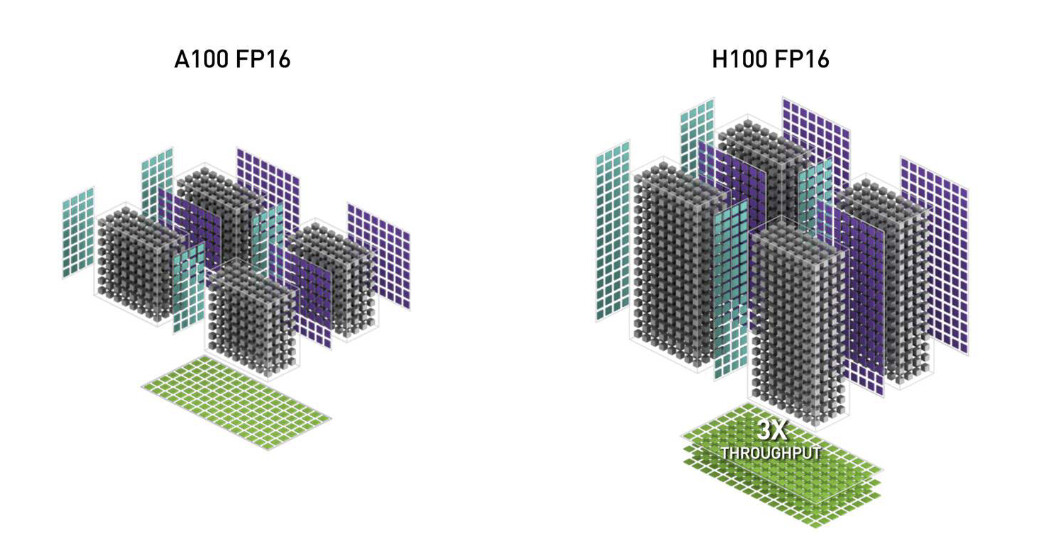
FlashAttention-3는 이전 버전인 FlashAttention-2에 비해 1.5배에서 2배 더 빠른 성능을 자랑하며, 특히 FP16 모드에서 최대 740 TFLOPS, FP8 모드에서는 1.2 PFLOPS의 성능을 달성합니다. 이러한 성능 향상은 NVIDIA의 Hopper GPU, 특히 H100 GPU의 새로운 기능들을 활용하여 이룬 것입니다. FlashAttention-3는 기존보다 더욱 긴 문맥을 처리할 수 있으며, 이는 복잡한 자연어 처리 작업에서 매우 유용합니다. 또한, FlashAttention-3를 사용하는 경우, 대규모 언어 모델의 학습 및 추론 시간 단축에 큰 도움을 줍니다.
TogetherAI의 블로그 글에서는 Hopper GPU에서 어텐션을 가속화하기 위한 세 가지 주요 기술을 설명하고 있습니다:
- WGMMA(Warpgroup Matrix Multiply-Accumulate): 새로운 Tensor Cores를 사용하는 이 기능은 이전의 mma.sync 명령보다 훨씬 높은 처리량을 제공합니다.
- TMA(Tensor Memory Accelerator): 글로벌 메모리와 공유 메모리 간의 데이터 전송을 가속화하는 하드웨어 유닛으로, 모든 인덱스 계산과 범위 초과 예측을 처리하여 타일 크기와 효율성을 증가시킨다.
- 저정밀도 FP8(Low-precision with FP8): 이는 Tensor Core 처리량을 두 배로 증가시키지만, 부동 소수점 숫자를 표현하는 데 더 적은 비트를 사용하여 정확도를 희생한다.

FlashAttention-3는 NVIDIA의 CUTLASS 라이브러리의 강력한 추상화를 사용하여 이러한 새로운 기능을 모두 활용합니다. 그 결과, 이전 버전인 FlashAttention-2보다 1.5-2배 빠르며 FP16(Floating Point 16) 연산에서 최대 740 TFLOPS(즉, H100 이론적 최대 FLOPS의 75%)를 달성할 수 있습니다. FP8 연산에서는 1.2 PFLOPS에 가까운 성능을 발휘하며, 기본 FP8 데이터의 어텐션 연산보다 2.6배 작은 오류를 보이는 것이 특징입니다.
FlashAttention-3에서의 주요 개선 사항은 다음과 같습니다:
-
GPU 활용도 향상: 새로운 기술은 H100 GPU의 최대 용량의 75%까지 사용하여 대형 언어 모델(LLM) 훈련 및 실행 속도를 크게(1.5-2배) 향상시킨다.
-
저정밀도 성능 향상: FlashAttention-3는 FP8과 같은 저정밀도 숫자와도 작동하며, 정확성을 유지한다. 이는 처리 속도를 더욱 빠르게 하고 메모리 사용량을 줄일 수 있다.
-
LLM에서 더 긴 문맥 사용 가능: 어텐션 메커니즘의 속도를 높임으로써 더 긴 텍스트를 보다 효율적으로 처리할 수 있다.
FlashAttention-3의 코드 및 활용 방법은 GitHub 저장소를 참고해주세요. FlashAttention-3 논문은 여기에서 읽을 수 있습니다.
GEMM과 Softmax 연산의 비동기적 처리 및 중첩(Overlapping)
행렬 곱(MatMul, Matrix Multiplication) 연산에 비해, 행렬 곱 연산이 아닌 다른 연산들(non-MatMul operations)은 최신 GPU에서 매우 느립니다. 어텐션 연산에서의 대부분은 Query와 Key 간의 행렬 곱 연산 및 어텐션 확률 P와 Value 간의 행렬 곱 연산에서 발생하는 GEMM(GEneral Matrix Multiply) 연산입니다.
하지만 Exponential과 같은 연산이 포함된 Softmax 연산의 경우에는 부동 소수점 곱셈(floating point multiply-add)이나 행렬 곱셈(matrix multiply-add)과는 다른, 별도의 단위인 다중 함수 단위(multi-function unit)으로 평가되며, 부동 소수점 곱셈보다 처리량이 훨씬 낮습니다.(= 훨씬 느립니다.) 예를 들어, H100 GPU SXM5의 FP16의 행렬 곱 연산은 989TFLOPS지만, 특수 함수의 경우 256배 낮은 처리량인 3.9 TFLOPS에 불과합니다. FP8 연산의 경우에는 행렬 곱 연산은 FP16에 비해 두배 빨라지지만, 지수 함수의 경우에는 속도가 동일합니다.
따라서 행렬 곱 연산(GEMM)과 소프트맥스 연산을 병렬로 작동하여 텐서 코어를 최대한 활용하는 것이 좋습니다. 가장 쉬운 방식은 아무것도 하지 않고, 워프스케줄러(WarpScheduler)가 각 워프그룹(WarpGroup)들 간의 중첩을 수행하도록 기대하는 것입니다. 또는, 아래와 같은 방식으로 2개의 서로 다른 워프그룹들에서 GEMM 연산들 번갈아가며 수행하는 방식(ping-pong)으로 스케줄을 조절합니다. 실제로는 이렇게 깔끔하게 스케줄링되는 어렵지만, 그럼에도 약간의 성능 향상을 기대할 수는 있습니다.
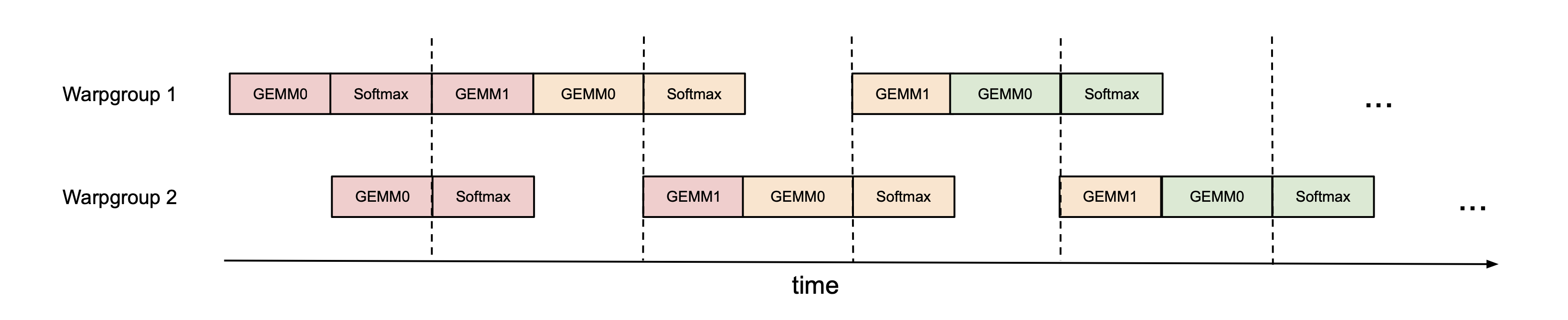
다른 방식은 아래 그림처럼 하나의 워프그룹 내에서 GEMM 연산과 Softmax 연산을 병렬적으로 처리하는 것입니다. 이러한 경우 더 많은 레지스터가 필요하지만 전반적으로 처리량이 증가합니다
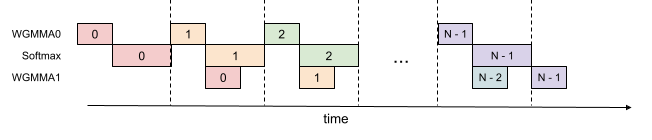
그 외에도, FP8과 같은 낮은 정밀도에서도 양자화 오류를 감소시켰습니다. LLM 등의 경우 종종 다른 값들보다 큰 이상치 값(outlier)이 포함되어 양자화(Quantization) 시 더 큰 오류를 발생시키곤 합니다. 이를 해결하기 위해 QuIP 등과 같은 양자화 기법에서 사용하는 '통일성 없는 처리(Incoherent Processing)' 기법을 사용하였습니다. 이는 Query와 Key에 임의의 직교 행렬(orthogonal matrix)을 곱하여 이상치를 분산(spread out)시키는 방식으로, 여기에서는 무작위 부호를 사용하는 하다마드 변환(Hadamard Transformation)을 활용하였습니다. (자세한 내용은 논문을 참고해주세요. ![]() )
)
어텐션 벤치마크
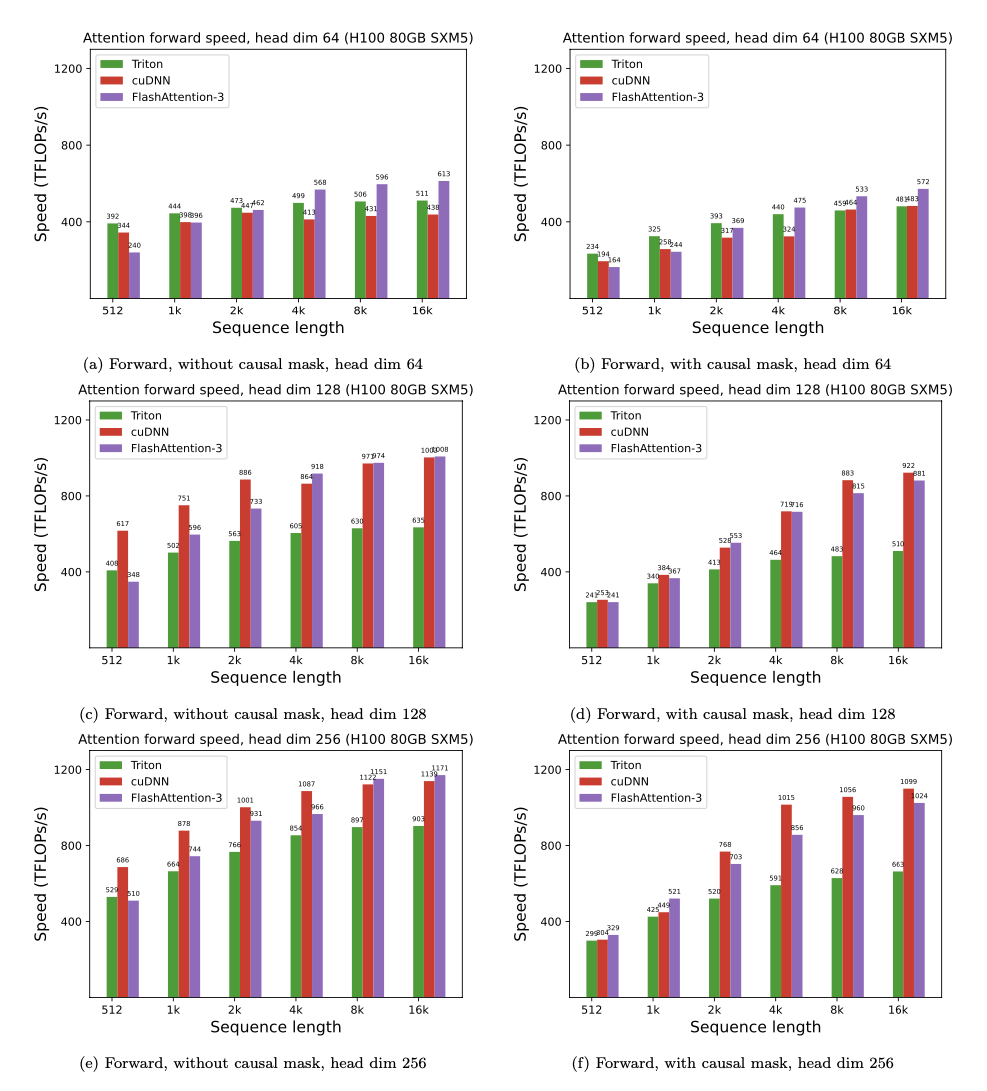
FlashAttention-3 구현체에 대한 벤치마크 결과, FlashAttention-2 대비는 물론이고, 이미 Hopper GPU에 최적화된 cuDNN이나 Triton보다도 더 빨라진 것을 확인할 수 있었습니다.
아래 표에서 볼 수 있듯, FP16 연산에서는 약 1.6-1.8배 가량의 속도 개선을 보였습니다.
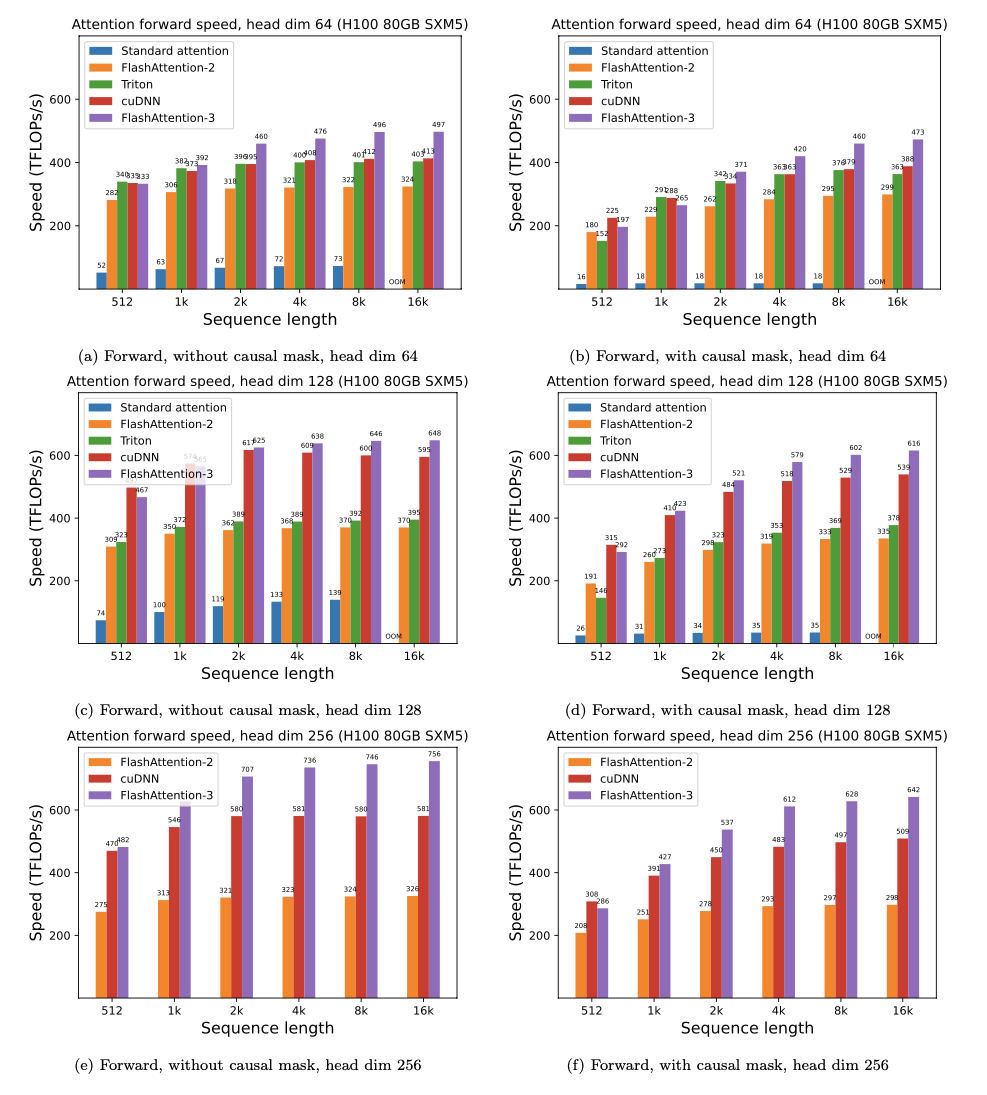
또한, FP8 연산 시에도 약 1.2페타플롭스(PFLOPS)에 근접하게 도달하는 속도를 보였습니다.
더 읽어보기
TogetherAI의 FlashAttention-3 글
 FlashAttention 구현체 저장소
FlashAttention 구현체 저장소
https://github.com/Dao-AILab/flash-attention
 FlashAttention-3 논문
FlashAttention-3 논문
FlashAttention 논문
NVIDIA H100 GPU 백서(Whitepaper)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()