
FlashTensors 소개
FlashTensors는 대규모 AI 모델을 초고속으로 로드하고, 단일 GPU 환경에서도 수십~수백 개 모델을 유연하게 핫스왑하며 운용할 수 있도록 설계된 고성능 추론 엔진입니다. 특히 모델을 SSD에서 GPU 메모리로 로딩하는 데 있어서 기존 로더보다 최대 10배 빠른 속도를 자랑하며, TTFT(Time to First Token)도 2초 미만으로 단축시킵니다.
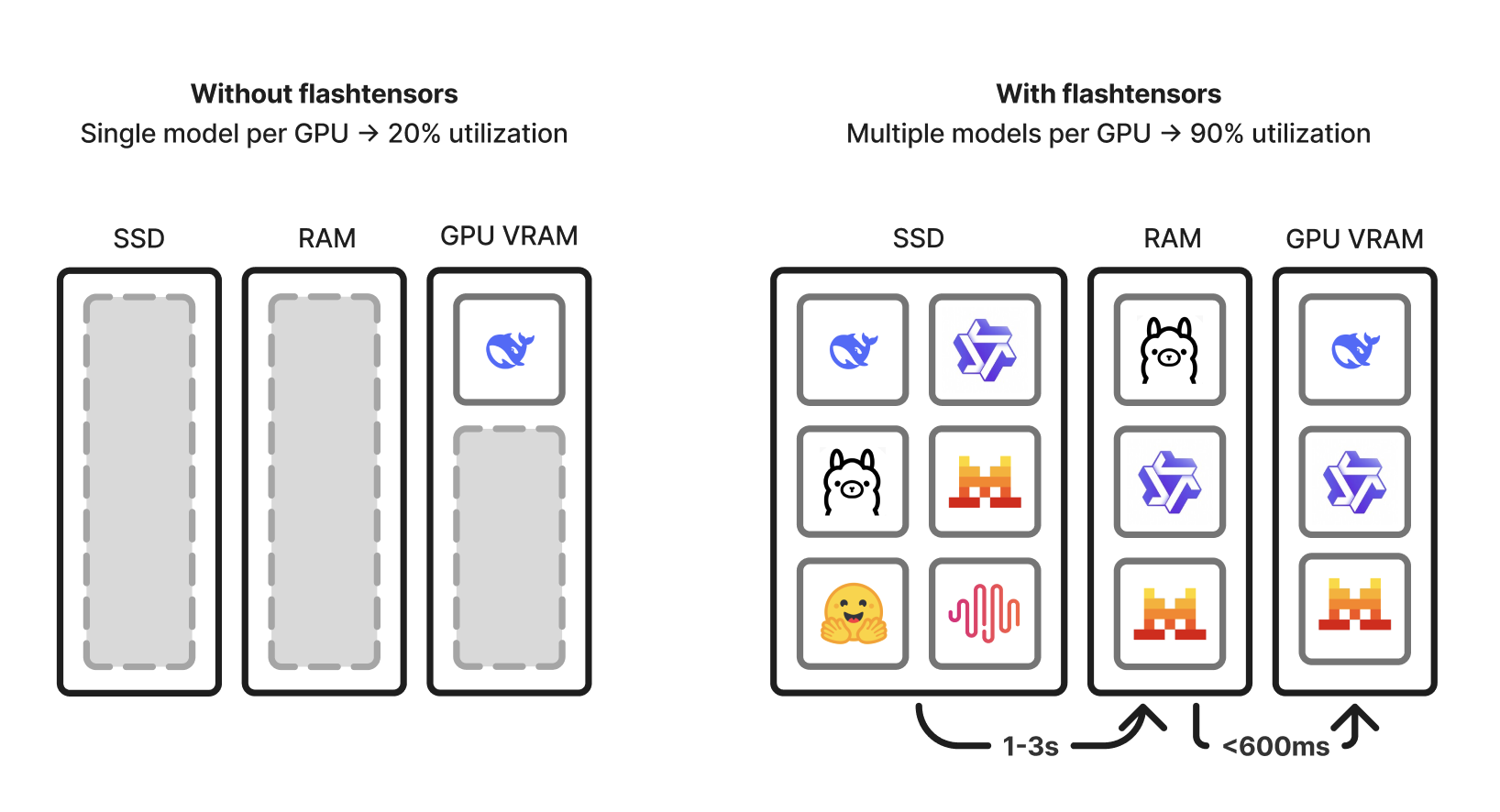
현대 AI 환경에서는 수많은 모델을 빠르게 교체하며 서비스해야 하는 경우가 많습니다. 그러나 기존의 safetensors나 torch.load() 기반 모델 로더는 이 과정에서 병목을 유발하며, 사용자 경험에 영향을 줄 수 있습니다. FlashTensors는 이러한 문제점을 해결하기 위해 모델을 불러오는 속도를 빠르게 하는 설계를 채택하였으며, 로컬에서 여러 모델을 동시에 다뤄야 하는 에이전트 기반 워크플로우나 로봇 등의 경량 환경에도 적합합니다.
이러한 기술은 특히 개인화 AI, 서버리스 추론, 로컬 배포, 로보틱스 등 다양한 도메인에서 활용될 수 있습니다. 단일 GPU에서 수십 개 모델을 동시에 핸들링하며 핫스왑이 가능하다는 점은 기존 인프라 비용을 줄이고, 개발 유연성을 극대화하는 데 핵심적인 역할을 합니다.
특히, FlashTensors는 safetensors 대비 모델 로딩 속도에서 약 4~6배 정도 빠르며, 특히 대규모 모델에서 그 효과가 극대화됩니다. 예를 들어, Qwen 3-32B 모델은 safetensors로 로딩 시 약 24초가 걸리지만, FlashTensors를 사용하면 4초 수준으로 단축됩니다. 또한 coldstart 시간도 일관되게 5초 미만으로 유지됩니다.
| 모델 | FlashTensors (초) | safetensors (초) | 속도 배율 |
|---|---|---|---|
| Qwen3-0.6B | 2.74 | 11.68 | ~4.3배 |
| Qwen3-4B | 2.26 | 8.54 | ~3.8배 |
| Qwen3-8B | 2.57 | 9.08 | ~3.5배 |
| Qwen3-14B | 3.02 | 12.91 | ~4.3배 |
| Qwen3-32B | 4.08 | 24.05 | ~5.9배 |
FlashTensors 사용법
FlashTensors는 Python 3.11 이상에서 다음 명령어로 간단하게 설치할 수 있습니다:
pip install git+https://github.com/leoheuler/flashtensors.git
CLI를 통한 모델 실행
FlashTensors는 CLI에서 다음과 같은 방식으로 모델을 로드하고 실행할 수 있습니다:
flash start # 서버 실행
flash pull Qwen/Qwen3-0.6B # 모델 다운로드
flash run Qwen/Qwen3-0.6B "Hello world" # 모델 실행
SDK를 이용한 프로그래밍적 제어
FlashTensors는 Python SDK도 제공합니다. vllm 백엔드를 통한 로딩 최적화 예시는 다음과 같습니다:
import flashtensors as ft
from vllm import SamplingParams
ft.configure(storage_path="/tmp/models", mem_pool_size=1024**3*30)
ft.activate_vllm_integration()
# 모델 등록 및 로딩
model_id = "Qwen/Qwen3-0.6B"
ft.register_model(model_id=model_id, backend="vllm", torch_dtype="bfloat16")
llm = ft.load_model(model_id=model_id, backend="vllm", dtype="bfloat16")
# 추론 실행
prompts = ["Hello, my name is", "The capital of France is"]
sampling_params = SamplingParams(temperature=0.1, top_p=0.95, max_tokens=50)
outputs = llm.generate(prompts, sampling_params)
또한 사용자 정의 모델에 대해서도 state_dict 기반으로 저장 및 로드가 가능합니다. torch.nn.Module 기반 모델을 저장하고 불러오는 과정도 매우 간단하게 처리할 수 있도록 설계되어 있습니다.
벤치마크 결과
FlashTensors는 NVLink 기반 H100 GPU 환경에서 측정한 결과를 기준으로 safetensors보다 4~6배 빠른 성능을 보입니다. 이 성능은 Cold Start 시간뿐 아니라 GPU 메모리 활용도에서도 높은 효율을 보장합니다.
또한 메모리 풀 방식(Chunked Memory Pooling)을 통해 메모리 재사용을 극대화하고, GPU 메모리 사용률을 사용자 정의할 수 있도록 하여, 제한된 리소스 환경에서도 유연하게 대응할 수 있습니다.
라이선스
FlashTensors 프로젝트는 Apache-2.0 라이선스로 공개 및 배포되고 있습니다. 상업적 사용에 제한은 없습니다.
 FlashTensors 프로젝트 GitHub 저장소
FlashTensors 프로젝트 GitHub 저장소
https://github.com/leoheuler/flashtensors
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()