flask-htmx-llm 프로젝트 소개
오늘날 대규모 언어 모델(LLM)을 웹 애플리케이션에 통합하려는 시도가 활발히 이루어지고 있습니다. 하지만 대부분의 프로젝트는 복잡한 프론트엔드 프레임워크와 과도한 백엔드 설정으로 인해 초보자들이 접근하기 어려운 경우가 많습니다. 이러한 상황에서 flask-htmx-llm 프로젝트는 간결하고 직관적인 학습용 구조로 주목받고 있습니다.
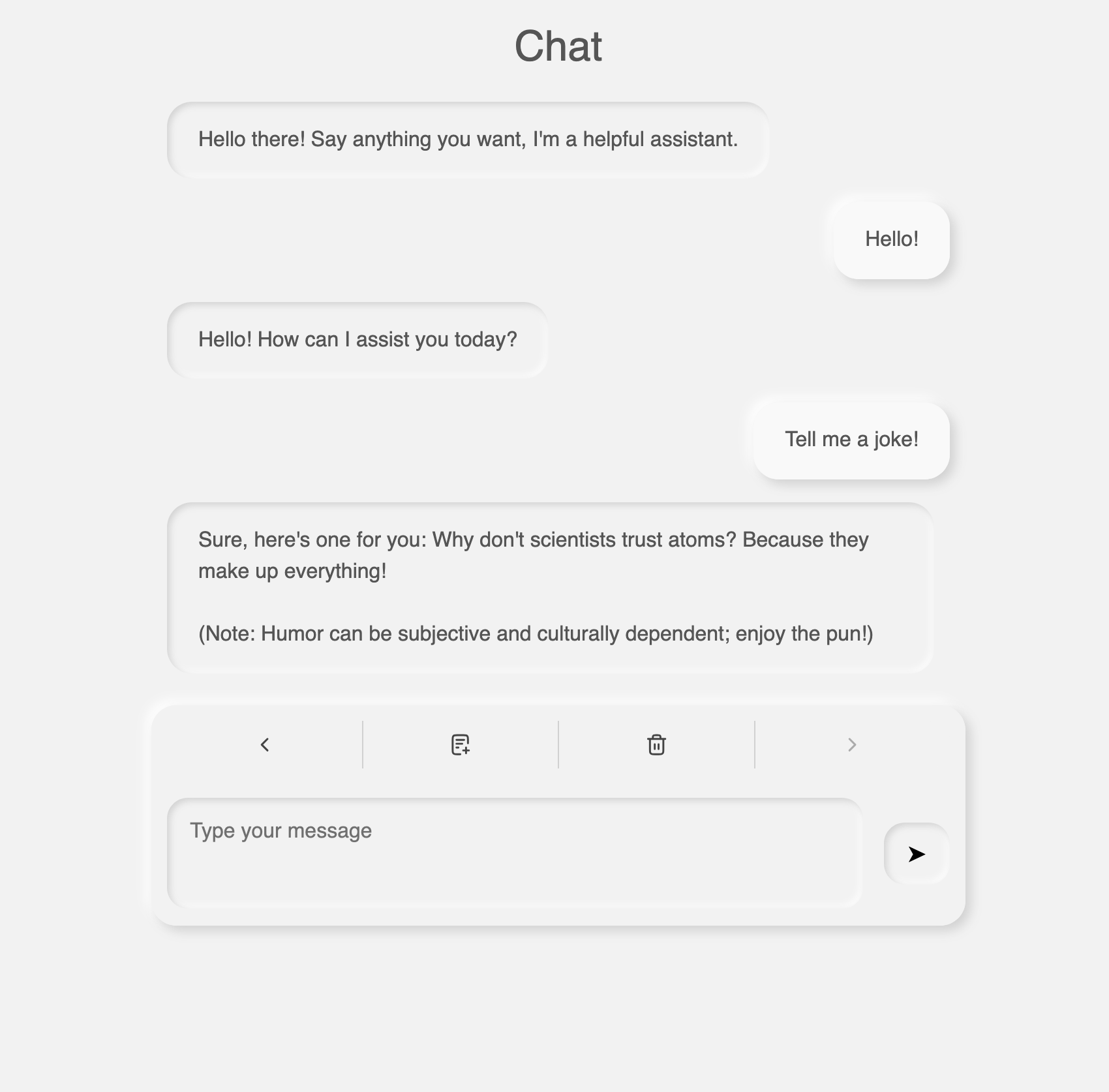
flask-htmx-llm 프로젝트는 Flask, HTMX, LangChain, 그리고 llama.cpp를 결합하여 구축된 미니멀한 LLM 챗봇 인터페이스로, 실습을 통한 학습에 초점을 맞춘 구조입니다. 특히 이 프로젝트는 프론트엔드에 복잡한 JavaScript 프레임워크를 사용하지 않고 HTMX를 활용하여 간단하고 직관적인 사용자 경험을 구현하고 있으며, 백엔드에서는 Server-Sent Events(SSE)를 통해 모델 응답을 스트리밍하는 방식을 채택하고 있습니다.
![]() 이 프로젝트는 프로덕션 환경에 적합하지 않지만, 로컬에서 안전하게 실험하며 기술을 익히기에 매우 좋은 출발점이 됩니다. LLM을 웹 앱에 통합하고 싶은 개발자라면 한 번쯤 직접 실행해보는 것을 추천합니다.
이 프로젝트는 프로덕션 환경에 적합하지 않지만, 로컬에서 안전하게 실험하며 기술을 익히기에 매우 좋은 출발점이 됩니다. LLM을 웹 앱에 통합하고 싶은 개발자라면 한 번쯤 직접 실행해보는 것을 추천합니다. ![]()
LLM 기반 챗봇을 만들기 위한 프레임워크로는 LangChain 외에도 LlamaIndex, Haystack 등 다양한 라이브러리가 존재합니다. 그러나 LangChain은 워크플로우 구성과 다양한 모델, 툴 연동에 특화되어 있어 학습용으로 가장 널리 사용되는 도구 중 하나입니다.
또한 프론트엔드 측에서는 React, Vue.js, Svelte 등 다양한 대안이 있지만, HTMX는 HTML 속성 기반으로 인터랙티브한 UI를 구축할 수 있어, 복잡한 JS 코드 없이도 실시간 사용자 경험을 구현할 수 있다는 장점이 있습니다. 이 프로젝트는 그러한 장점을 잘 활용하여 최대한 간결한 구조로 챗봇 인터페이스를 구성하고 있습니다.
flask-htmx-llm의 주요 구성 요소
LangChain + llama.cpp 기반 LLM 백엔드
flask-htmx-llm 프로젝트는 로컬에서 실행 가능한 LLM 엔진인 llama.cpp를 LangChain을 통해 제어합니다. 이를 통해 외부 API 호출 없이 로컬에서 모델 추론이 가능하며, 개인용 학습 및 실험에 적합합니다. Phi-3.5-mini-instruct와 같은 경량화된 모델이 권장되며, .gguf 포맷의 모델 파일을 이용합니다.
LangChain은 모델 호출뿐 아니라 입력 처리, 출력 포맷팅, 상태 관리 등도 담당할 수 있어 챗봇 구성에 유용합니다. 이 구조는 또한 추후 RAG(Retrieval-Augmented Generation)이나 도메인 특화 챗봇으로의 확장도 가능하게 합니다.
HTMX 기반 프론트엔드
HTMX는 HTML 요소에 속성만 추가함으로써 서버와의 상호작용을 정의할 수 있게 해주는 프론트엔드 도구입니다. 이 프로젝트에서는 JavaScript 코드 없이 HTMX를 이용하여 채팅 인터페이스의 메시지 전송과 응답 렌더링을 처리하고 있으며, UI는 최소한의 Neumorphic 디자인으로 구성되어 있습니다.
Flask 백엔드와 SSE 기반 스트리밍
Flask는 웹 애플리케이션의 라우팅과 서버 사이드 로직을 담당합니다. 모델 응답은 Server-Sent Events(SSE)를 통해 실시간으로 프론트엔드에 스트리밍되며, 사용자에게 자연스러운 대화 경험을 제공합니다. 이는 ChatGPT와 같은 “점점 생성되는 답변” UI를 간단하게 구현할 수 있게 해줍니다.
또한 SQLite 기반의 세션별 대화 저장 기능, 단일 스레드 큐 기반의 모델 호출 관리 기능도 포함되어 있어, 초보자가 상태 관리와 동기화 문제를 학습하기에 적합한 구조입니다.
실행 방법
설치 및 실행
- uv 패키지 매니저 설치
- Phi-3.5-mini-instruct GGUF 모델 다운로드 후
.env또는 환경변수에 경로 설정:CHAT_MODEL_GGUF=/path/to/your/model.gguf - 프로젝트 실행:
uv run flask --app main run - 코드 변경 시 자동 재시작:
export FLASK_DEBUG=1 - (선택) GPU 가속(CUDA) 사용 시:
CMAKE_ARGS="\ -DGGML_CUDA=on \ -DLLAMA_BUILD_TESTS=OFF \ -DLLAMA_BUILD_EXAMPLES=OFF \ -DLLAMA_BUILD_TOOLS=OFF" \ uv add --force-reinstall --no-cache-dir llama-cpp-python
하드웨어 요구사항
- 빠른 CPU 및 RAM
- NVIDIA GPU (CUDA 가속 시)
한계점 및 주의사항
![]() flask-htmx-llm 프로젝트는 학습용 실험에 초점을 맞추고 있으며, 다음과 같은 이유로 프로덕션에는 부적합합니다:
flask-htmx-llm 프로젝트는 학습용 실험에 초점을 맞추고 있으며, 다음과 같은 이유로 프로덕션에는 부적합합니다:
- 인증/세션 보안 미구현
- 에러 핸들링 미비
- 입력값 검증 미구현
- 단일 스레드 큐 기반의 동기식 모델 호출
따라서 실제 서비스에 적용하려면 전반적인 보안, 병렬 처리, 에러 로깅 등의 리팩터링이 필요합니다.
라이선스
flask-htmx-llm 프로젝트는 MIT 라이선스로 공개되어 있으며, 상업적 사용이 가능하지만 보증이 없으며 직접적인 위험에 대한 책임은 사용자에게 있습니다.
 flask-htmx-llm 프로젝트 GitHub 저장소
flask-htmx-llm 프로젝트 GitHub 저장소
https://github.com/joelkuiper/flask-htmx-llm
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()