
FutureBench 소개
인공지능(AI) 분야의 주요 평가 지표는 대부분 과거의 지식에 기반한 질문에 얼마나 정확히 답할 수 있는지를 기준으로 삼고 있습니다. HLE나 GPQA 같은 고정형 지식 기반 문제나, BrowseComp, GAIA처럼 확장된 정보 접근이 가능한 벤치마크조차도 과거에 존재하는 데이터를 바탕으로 평가를 진행하죠. 하지만 Hugging Face에서는 한 걸음 더 나아가, AI의 진정한 가치를 ‘과거의 데이터를 기반으로 미래를 얼마나 잘 예측할 수 있는가’에 있다고 보고 있습니다.

미래 예측은 단순한 패턴 매칭을 넘어서, 다양한 정보를 종합하고 불확실성을 판단하며 복잡한 인과관계를 이해해야 하는 고차원의 인지 능력을 요구합니다. 이는 곧 실생활에서 유용하게 활용될 수 있는 AI 지능의 본질과 맞닿아 있는 문제이기도 합니다. Hugging Face는 이러한 문제의식에서 출발해, AI 에이전트가 실제 미래 사건을 얼마나 정확하게 예측할 수 있는지를 평가하는 새로운 벤치마크, FutureBench를 개발했습니다.
특히 이 벤치마크는 기존 평가에서 문제가 되었던 데이터 누출(Data Contamination) 문제를 구조적으로 차단합니다. 왜냐하면 미래에 대한 데이터는 아직 존재하지 않기 때문이죠. 또한, 시간이 지나면 해당 예측이 맞았는지 틀렸는지를 명확히 확인할 수 있어, 평가 결과의 신뢰성이 극대화됩니다. 이런 점에서 FutureBench는 단순한 기술적 실험이 아닌, AI 평가 방식 자체에 대한 새로운 접근을 제시하는 중요한 시도입니다.
미래를 예측할 수 있는가? AI 에이전트의 역할
FutureBench의 중심 질문은 명확합니다: “AI는 과연 미래를 예측할 수 있을까?”
이는 단순한 예 / 아니오의 문제라기보다는, 어떤 종류의 질문에 대해서 어느 정도까지 예측할 수 있느냐는 복합적인 문제입니다. 예를 들어, 어떤 기업의 분기 실적이나 선거 결과와 같은 주제는 전문가들이 다양한 정보를 바탕으로 예측하는 대표적인 예이며, AI 역시 동일한 방식으로 정보를 수집하고 종합하여 판단할 수 있어야 합니다.
FutureBench는 이러한 인지적 판단 능력을 실질적으로 평가할 수 있는 구조를 가지고 있습니다. 에이전트가 검색과 수집 도구를 활용하여 정보를 모으고, 그 정보를 분석하여 정량적·정성적으로 예측을 수행하는 과정은, 사실상 실생활에서 인간이 의사결정을 내리는 과정과 유사하다고 할 수 있습니다.
FutureBench의 두 가지 질문 생성 방식: 뉴스 기반 vs. 예측 시장 기반

FutureBench는 예측 평가를 위해 다음 두 가지 주요 질문 생성 방식으로 구성됩니다:
-
뉴스 기반 질문 생성: SmolAgents 기반 에이전트를 사용하여 주요 뉴스 사이트를 스크래핑하고, 이들 기사로부터 예측할 수 있는 사건을 추출합니다. 예를 들어, 연준의 금리 결정, 지정학적 사건, 기술 기업의 발표와 같은 실질적이고 시의성 있는 주제를 중심으로 미래 결과를 예측하는 질문을 자동 생성합니다.
- 사용 모델: DeepSeek-V3
- 수집 도구: Firecrawl (웹 스크래핑), Tavily (검색)
- 특징: 약 1주일 이내 결과가 나오는 사건 중심
-
Polymarket 기반 질문 수집: Polymarket은 사용자가 실제 돈을 걸고 미래 사건에 대한 예측을 진행하는 예측 시장 플랫폼입니다. 이 플랫폼에서 생성된 질문을 수집하여 벤치마크에 포함합니다. 다만 사건 발생 시점이 불규칙하므로 데이터의 수집 빈도와 구조는 뉴스 기반에 비해 상대적으로 느슨합니다.
FutureBench의 3단계 평가 구조
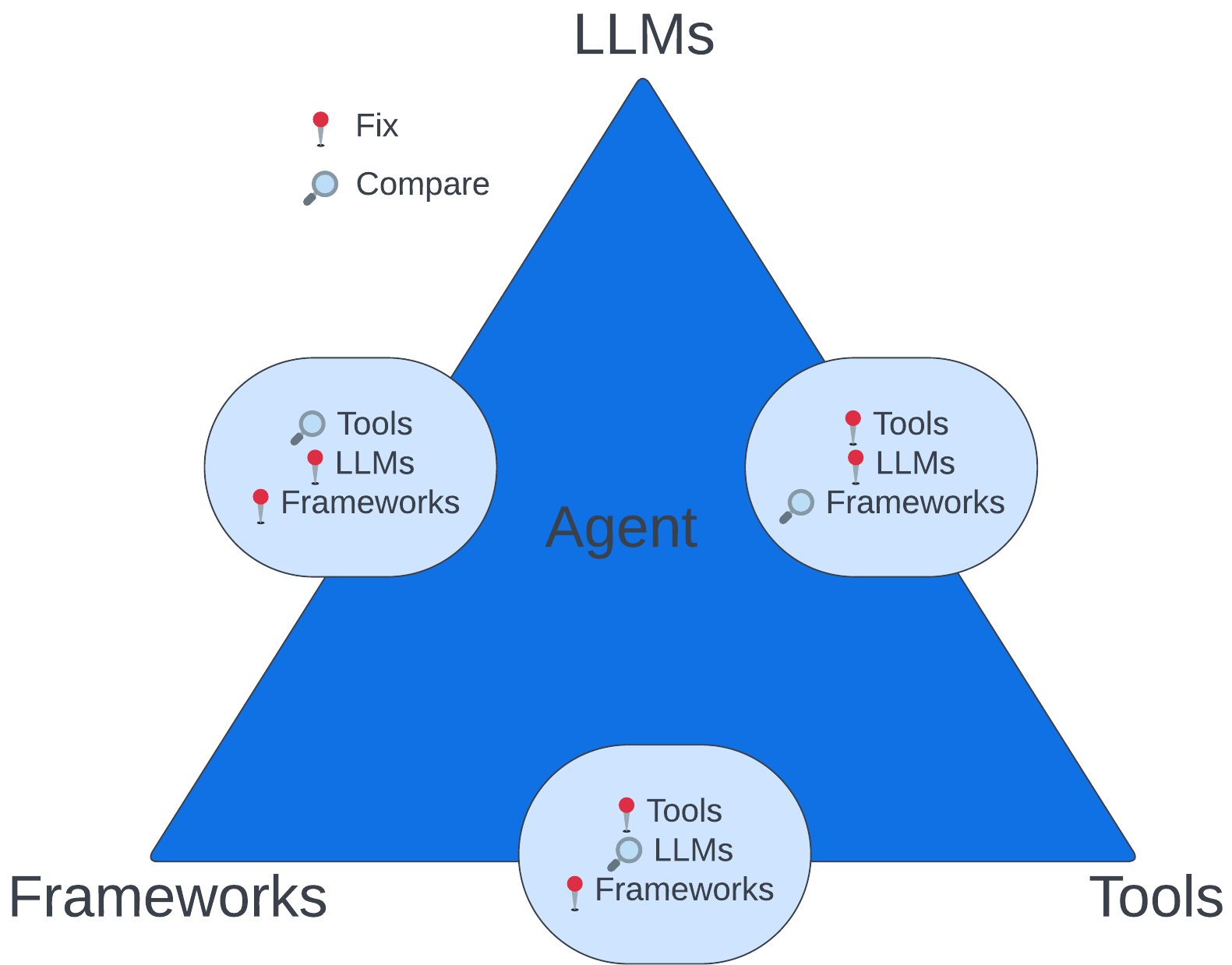
FutureBench는 평가를 체계화하기 위해 다음의 3단계 구조를 따릅니다:
-
1단계. 프레임워크 비교: LangChain vs CrewAI 등 동일한 모델과 도구를 사용하면서 프레임워크만 바꾸어 비교합니다.
-
2단계. 도구의 성능 비교: 모델과 프레임워크는 고정한 채, 다양한 검색 엔진(Google, Bing, Tavily 등)의 영향을 비교합니다.
-
3단계. 모델 능력 평가: 같은 도구와 프레임워크를 사용하되, 모델만 DeepSeek, GPT-4, Claude 등으로 변경해 순수한 추론 능력을 평가합니다.
이러한 다층적 접근 방식은 AI 시스템 내에서 어떤 요소가 실제 성능에 기여하는지를 보다 정밀하게 파악할 수 있도록 도와줍니다.
예측 결과와 분석
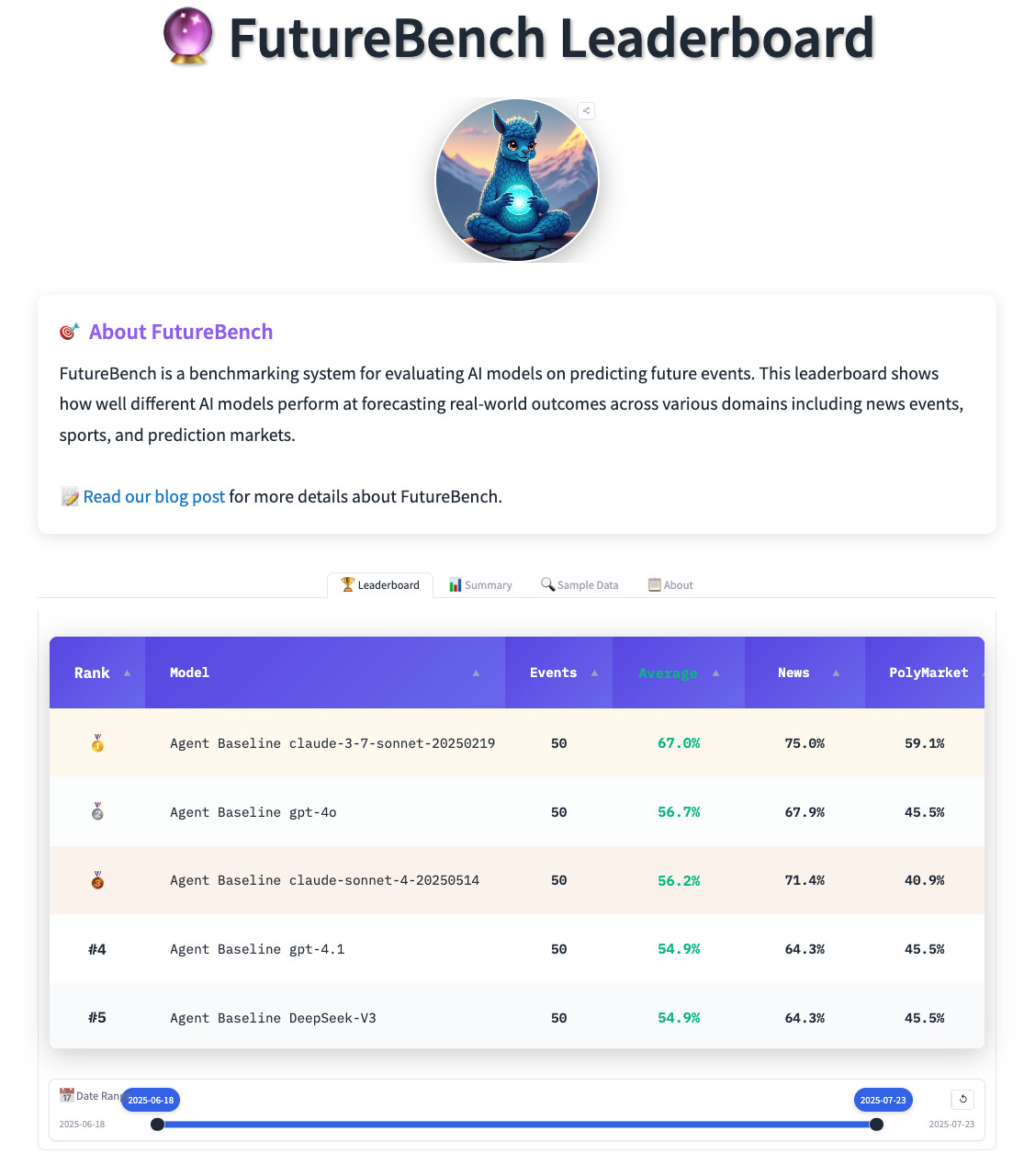
SmolAgents 기반으로 구축된 FutureBench 실험에서 다음과 같은 초기 분석 결과가 나왔습니다:
- GPT-4.1은 검색 기반 정보를 중시하고,
- Claude 3.7/4는 웹 스크래핑을 적극적으로 사용하여 더 많은 정보를 수집함,
- DeepSeek-V3는 비교적 간결하고 체계적인 분석을 수행하는 경향이 있습니다.
특히 Claude는 Bureau of Labor Statistics (.gov) 웹사이트까지 스크래핑하려 했지만 정책상 차단되는 등, 모델별로 정보 접근 방식에 차이가 있다는 점이 흥미로운 발견이었습니다.
 FutureBench 소개 블로그
FutureBench 소개 블로그
 FutureBench 리더보드
FutureBench 리더보드
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()