Gemma 모델군의 아키텍처에 대한 설명 글 소개

Gemma는 다양한 연구와 기술을 바탕으로 만들어진 가벼운 오픈 모델들의 패밀리로, 다양한 용도와 모달리티에 맞게 설계되었습니다. Gemma의 다양한 변형은 다음과 같이 다양한 사용 사례와 양식에 맞게 설계되었습니다:
- 단일 모달리티(Single Modality: 텍스트 입력, 텍스트 출력)
- 코딩 사용 사례를 위한 전문화
- 멀티 모달리티(Multi Modality: 텍스트 및 이미지 입력, 텍스트 출력)
- 다양한 하드웨어 유형, 추론 요구 사항 및 기타 제약 조건에 따른 다양한 크기.
- “새로운” 아키텍처
이러한 모든 모델은 유사한 DNA를 공유하기 때문에 Gemma 제품군은 최신 LLM 시스템에서 사용할 수 있는 아키텍처와 디자인 선택에 대해 배울 수 있는 독특한 방법을 제시합니다. 이를 통해 개방형 모델의 풍부한 생태계에 기여하고 LLM 시스템의 작동 방식에 대한 이해를 증진할 수 있기를 바랍니다.
이 글에서 다룰 내용은 다음과 같습니다:
- Gemma 1(2B, 7B) - 트랜스포머 기반 텍스트 대 텍스트 모델.
- CodeGemma(2B 및 7B) - 코드 완성 및 생성을 위해 최적화된 Gemma의 미세 조정 버전입니다.
- Gemma 2(2B, 9B, 27B) - 더 큰 모델에서 증류를 통해 학습된 2B 및 9B 버전으로 최신 아키텍처로 학습된 업데이트된 텍스트-텍스트 모델입니다.
- RecurrentGemma(2B, 9B) - 새로운 그리핀 아키텍처를 기반으로 구축된 모델입니다. 이 아키텍처는 국부적 주의와 선형 재귀를 혼합하여 긴 시퀀스를 생성할 때 빠른 추론을 달성합니다.
- PaliGemma(3B) - 텍스트와 이미지를 받아 텍스트 출력을 제공할 수 있는 시각 언어 모델입니다.
Gemma 아키텍처
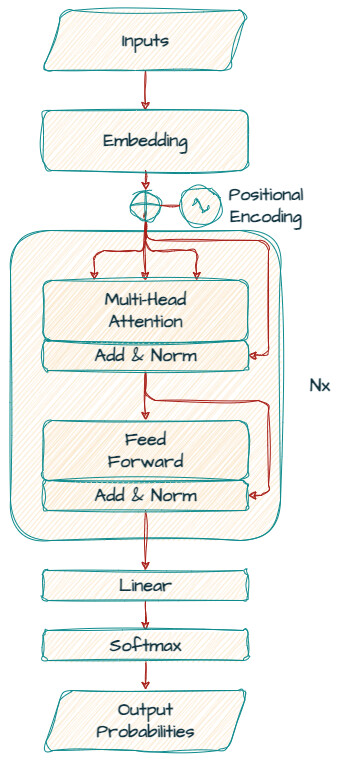
Gemma는 주로 텍스트 생성을 위한 "디코더 전용" 모델입니다. 주요 아키텍처는 "Attention Is All You Need" 논문에서 제안된 트랜스포머 디코더에 기반하고 있으며, Gemma는 다양한 크기와 구성으로 제공됩니다. Gemma 아키텍처의 핵심 요소를 살펴보겠습니다.
torchinfo나 Keras 모델 클래스 API의 summary()를 사용하여 모델 내부를 직접 탐색할 수도 있습니다. Gemma 아키텍처의 핵심 매개변수는 아래 표와 같습니다:
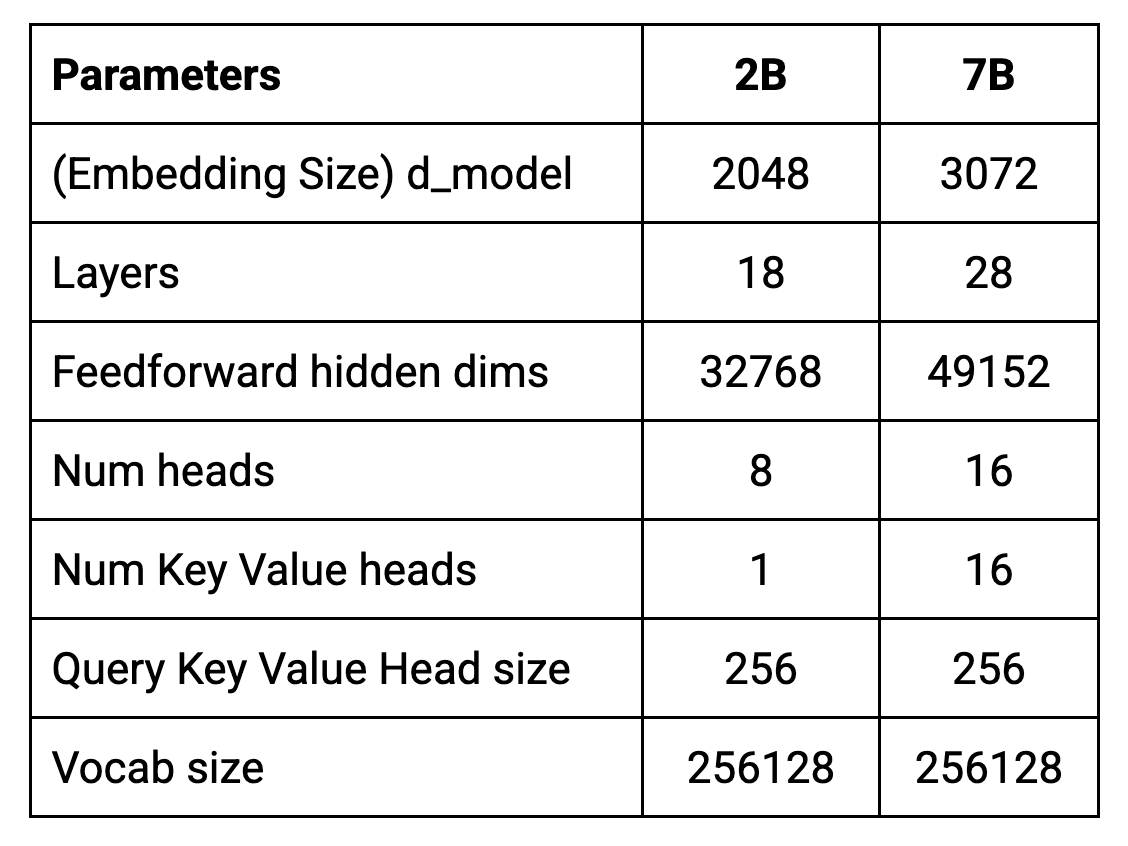
임베딩 크기, d_model ((2B: 2048, 7B: 3072)
d_model은 디코더에 입력으로 사용되는 임베딩 크기를 나타내며, 내부 표현의 크기를 결정합니다. 더 큰 d_model 값은 모델이 단어의 뉘앙스와 관계를 더 잘 표현할 수 있게 하지만, 모델이 더 커지고 계산 비용이 증가합니다.
레이어 수(Layers (2B: 18, 7B: 28))
트랜스포머는 여러 계층으로 구성됩니다. 더 깊은 모델은 더 많은 계층을 가지며, 더 복잡한 패턴을 학습할 수 있지만 과적합의 위험이 증가합니다.
FF 은닉 차원(Feedforward hidden dims (2B: 32768, 7B: 49152))
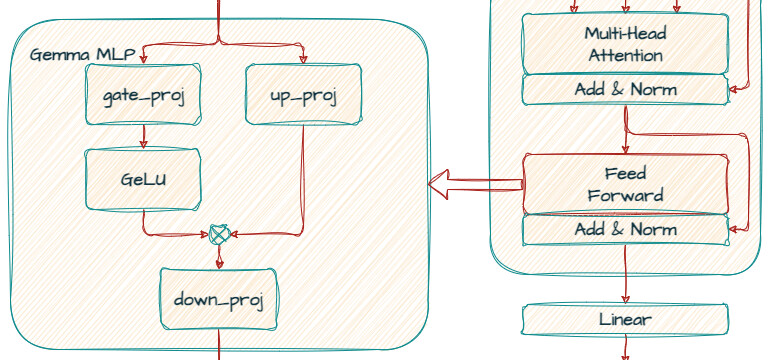
각 트랜스포머 계층은 어텐션 메커니즘 이후에 피드포워드 네트워크를 포함하며, 이 네트워크의 차원은 모델의 표현력을 증가시키기 위해 종종 더 큽니다. Gemma는 ReLU 대신 GeGLU 활성화 함수를 사용하여 더 복잡한 패턴을 추출합니다.
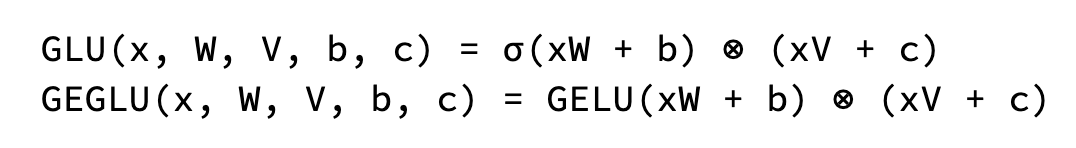
Num heads (2B: 8, 7B: 16)
각 트랜스포머 계층에는 여러 개의 병렬 어텐션 메커니즘이 포함됩니다. 더 많은 헤드는 모델이 입력 시퀀스의 다양한 측면을 동시에 캡처할 수 있게 해줍니다.
Num KV heads (2B: 1, 7B: 16)
Gemma 2B 모델은 다중 쿼리 어텐션(MQA, Multi-Query Attention)를 사용하며, 이는 더 적은 계산 비용으로 효율적인 대안이 될 수 있습니다.
Head size (2B: 256, 7B: 256)
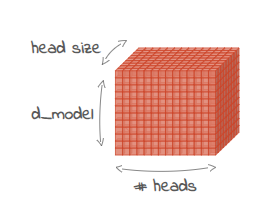
헤드 크기는 다중 헤드 어텐션(MHA, Multi-Head Attention) 메커니즘 내에서 각 헤드의 차원을 나타내며, 이는 임베딩 차원을 헤드 수로 나누어 계산됩니다.
Vocab size
Vocab size는 모델이 이해하고 처리할 수 있는 고유 토큰의 수를 정의하며, Gemma는 SentencePiece를 기반으로 하여 다양한 텍스트 입력을 처리할 수 있습니다.
Gemma 7B 모델 구조
GemmaForCausalLM(
(model): GemmaModel(
(embed_tokens): Embedding(256000, 3072, padding_idx=0)
(layers): ModuleList(
(0-27): 28 x GemmaDecoderLayer(
(self_attn): GemmaSdpaAttention(
(q_proj): Linear(in_features=3072, out_features=4096, bias=False)
(k_proj): Linear(in_features=3072, out_features=4096, bias=False)
(v_proj): Linear(in_features=3072, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=3072, bias=False)
(rotary_emb): GemmaRotaryEmbedding()
)
(mlp): GemmaMLP(
(gate_proj): Linear(in_features=3072, out_features=24576, bias=False)
(up_proj): Linear(in_features=3072, out_features=24576, bias=False)
(down_proj): Linear(in_features=24576, out_features=3072, bias=False)
(act_fn): PytorchGELUTanh()
)
(input_layernorm): GemmaRMSNorm()
(post_attention_layernorm): GemmaRMSNorm()
)
)
(norm): GemmaRMSNorm()
)
(lm_head): Linear(in_features=3072, out_features=256000, bias=False)
)
Gemma 7B 모델은 28개의 GemmaDecoderLayer 블록으로 구성되어 있으며, 각 레이어는 토큰 임베딩을 정교하게 다듬어 복잡한 단어와 문맥 간의 관계를 캡처합니다.
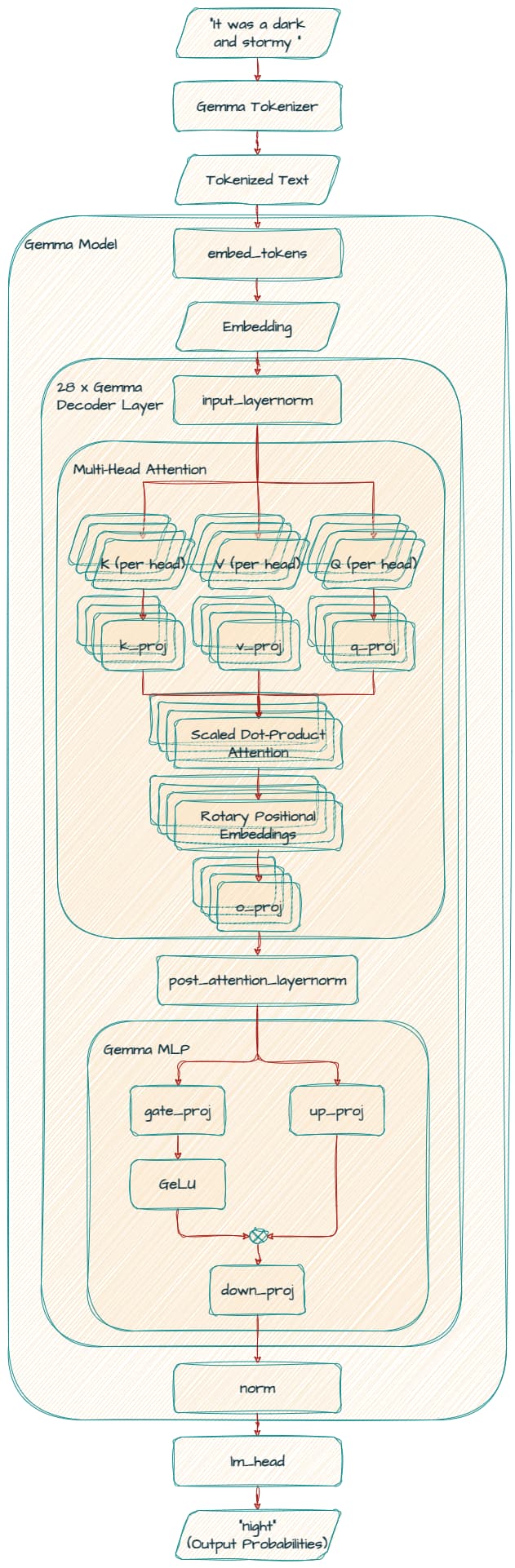
embed_tokens: 임베딩 레이어 (Embedding Layer)
임베딩 레이어는 모델의 첫 번째 레이어로, 입력된 토큰(단어 또는 서브워드)을 밀집된 수치 표현인 임베딩 벡터로 변환하는 역할을 합니다. Gemma 7B 모델에서 이 레이어는 256,000개의 고유 토큰을 처리할 수 있으며, 각 토큰은 3072차원의 임베딩 벡터로 변환됩니다.
- Vocabulary Size: 256,000 (고유 토큰 수)
- Embedding Dimension: 3072 (각 토큰의 임베딩 벡터 크기)
레이어 (Layers)
Gemma 7B 모델은 총 28개의 디코더 레이어로 구성되어 있으며, 이들은 모델의 중추 역할을 합니다. 각 레이어는 입력된 임베딩 벡터를 점진적으로 변환하며, 입력 문맥의 복잡한 관계를 이해할 수 있도록 돕습니다.
- Layer Stack: 28개의 디코더 레이어로 구성
- 디코더 레이어: 각 레이어는 독립적으로 입력을 처리하고, 이전 레이어의 출력을 바탕으로 추가적인 정보 처리를 수행합니다.
self_attn: Self-Attention 메커니즘 (Self-Attention Mechanism)
Self-Attention 메커니즘은 트랜스포머 모델의 핵심 요소 중 하나로, 입력된 문장에서 각 단어가 다른 단어와 맺는 관계를 동적으로 학습하는 방식입니다.
- Linear Projections (선형 투사):
q_proj: 쿼리 벡터를 생성하기 위한 선형 투사 (입력 피처: 3072, 출력 피처: 4096)k_proj: 키 벡터를 생성하기 위한 선형 투사 (입력 피처: 3072, 출력 피처: 4096)v_proj: 값 벡터를 생성하기 위한 선형 투사 (입력 피처: 3072, 출력 피처: 4096)o_proj: 출력 벡터를 생성하기 위한 선형 투사 (입력 피처: 4096, 출력 피처: 3072)
- Multi-Head Attention (MHA): Gemma 7B 모델은 16개의 헤드를 사용하여 병렬로 Self-Attention을 수행합니다. 각 헤드는 입력의 서로 다른 부분에 집중할 수 있도록 설계되어, 모델이 다양한 문맥 정보를 동시에 처리할 수 있게 합니다.
- Head Size: 256
- Num Heads: 16
- Rotary Positional Embedding (RoPE): Gemma 7B는 기존의 절대적 위치 인코딩 대신 Rotary Positional Embedding을 사용하여, 위치 정보의 보존을 더 효과적으로 처리합니다. 이는 모델이 순서와 관계없이 입력의 문맥을 더 잘 이해할 수 있게 돕습니다.
Feedforward 네트워크 (MLP)
각 디코더 레이어에는 Self-Attention 메커니즘 뒤에 위치한 피드포워드 네트워크가 포함되어 있습니다. 이 네트워크는 입력 임베딩을 추가로 변환하여 더 복잡한 패턴을 추출하는 역할을 합니다.
- GeGLU Activation: ReLU 대신 GeGLU 활성화 함수가 사용됩니다. 이 활성화 함수는 두 가지 부분으로 나뉘며, 비선형성과 게이트 메커니즘을 결합하여 더욱 복잡한 데이터 변환을 가능하게 합니다.
- Gate_proj: 게이트를 통한 비선형 변환 (입력 피처: 3072, 출력 피처: 24,576)
- Up_proj: 차원을 증가시키는 선형 투사 (입력 피처: 3072, 출력 피처: 24,576)
- Down_proj: 차원을 다시 감소시키는 선형 투사 (출력 피처: 3072)
정규화 레이어 (Normalization Layers)
Gemma 7B 모델에는 여러 정규화 레이어가 포함되어 있으며, 이는 모델의 학습을 안정화하고 과적합을 방지하는 데 중요한 역할을 합니다.
- Input Layernorm: 각 입력에 대한 정규화를 수행하여, 입력 분포를 일정하게 유지합니다.
- Post-Attention Layernorm: Self-Attention 후에 적용되는 정규화 레이어입니다.
- Final Norm Layer: 최종 출력을 위한 정규화 레이어로, 모든 레이어가 처리된 후에 마지막으로 적용됩니다.
LM Head
LM Head는 모델의 최종 출력 레이어로, 피드포워드 네트워크를 통해 생성된 최종 임베딩을 다시 어휘(vocabulary) 공간으로 매핑합니다. 이 레이어는 다음 토큰의 확률 분포를 계산하여, 주어진 입력 문맥에서 가장 적합한 다음 단어를 예측합니다.
- Output Features: 3072차원의 임베딩을 256,000개의 고유 토큰에 매핑하여 다음 단어를 예측합니다.
CodeGemma 모델
CodeGemma는 Gemma 모델 패밀리의 일부로, 주로 코드 생성과 코드 완성을 위한 작업에 특화된 언어 모델입니다. CodeGemma 모델은 기존의 Gemma 모델을 기반으로 하여 추가적인 미세 조정을 거친 것으로, 코드를 이해하고 생성하는 능력을 강화한 것이 특징입니다. 이 모델은 주로 코드 자동 완성, 코드 생성, 그리고 코드 리뷰 등의 개발자 작업을 지원하는 데 사용됩니다. CodeGemma는 두 가지 주요 버전으로 제공됩니다: 2B와 7B 모델. 이 모델들은 각기 다른 규모의 매개변수를 가지고 있으며, 다양한 코드 관련 작업에서 최적의 성능을 발휘합니다.
CodeGemma 모델은 5000억 개 이상의 코드 토큰으로 훈련되었으며, 중간 채우기 기능(FIM)을 추가하여 코드 보완 기능을 강화했습니다.
다음 글
이 글은 다음과 같이 구성되며, 다음 글에서는 Gemma 2 모델을 다룰 예정입니다. 이 모델은 성능과 효율성을 높이기 위해 중요한 개선 사항을 포함하고 있습니다.
- Gemma explained: An overview of Gemma model family architectures
 이번 글
이번 글 - Gemma explained: What’s new in Gemma 2
- Gemma explained: RecurrentGemma architecture
- Gemma explained: PaliGemma architecture
원문 읽어보기
더 읽어보기
- Attention is All You Need 논문: [1706.03762v7] Attention Is All You Need
- Gemma 모델의 기술 문서: Gemma: Open Models Based on Gemini Research and Technology
-
GLU Variants Improve Transformer 논문: [2002.05202] GLU Variants Improve Transformer
-
Fast Transformer Decoding: One Write-Head is All You Need 논문: [1911.02150] Fast Transformer Decoding: One Write-Head is All You Need
-
[DSBA] Transformer to LLaMA: 25가지 언어모델의 논문 소개 / 정리 (559p / PDF)
-
SpreadSheet is All You Need: 스프레드시트(또는 엑셀)로 이해하는 nanoGPT의 동작 원리
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()