GLM-4, 26개 언어를 지원하는 9B 규모의 LLM 및 MLLM(Multimodal-LLM)
소개
Zhipu AI에서 최근 공개한 GLM-4 시리즈는 다국어 지원 및 고해상도 이미지를 입력으로 받는 멀티모달 대규모 언어 모델(MLLM, Multimodal LLM)입니다. 26개 언어를 지원하는 GLM-4 시리즈는 특히 긴 텍스트와 복잡한 문맥을 처리하는 데 강점을 보이며, 의미론, 수학, 추론, 코드, 지식 평가에서 뛰어난 성능을 보입니다.
GLM-4-9B는 기존의 여러 모델과 비교했을 때도 뛰어난 성능을 보여줍니다. 예를 들어, Llama-3-8B와 비교했을 때, GLM-4-9B는 수학, 추론, 코드 실행 등에서 더 높은 점수를 기록했습니다. 또한, GPT-4-turbo와 비교했을 때도 GLM-4V-9B는 고해상도 멀티모달 처리 능력에서 우수한 성능을 보였습니다.
주요 특징
-
다국어 지원: 26개 언어를 지원하여 다양한 언어 환경에서 사용 가능
-
고해상도 멀티모달 기능: GLM-4V-9B 모델은 1120*1120의 고해상도를 지원
-
긴 텍스트 처리: 최대 128K의 컨텍스트 길이를 지원하여 긴 문맥도 효과적으로 처리
-
고급 기능: 웹 브라우징, 코드 실행, 사용자 정의 도구 호출 기능 등 포함
GLM-4 시리즈의 4가지 모델들
GLM-4 시리즈는 다음과 같은 특징들을 갖는 총 4가지 모델들로 구성되어 있습니다:
| 모델 | 유형 | 시퀀스 길이 | 다운로드 | 온라인 데모 |
|---|---|---|---|---|
| GLM-4-9B | 기본 | 8K | / | |
| GLM-4-9B-Chat | 채팅 | 128K | ||
| GLM-4-9B-Chat-1M | 채팅 | 1M | / | |
| GLM-4V-9B | 채팅 | 8K | / |
GLM-4-9B-Chat 모델은 128K 컨텍스트를 지원하며 웹 브라우징, 코드 실행, 긴 텍스트 처리 등의 고급 기능을 제공합니다. 이 모델은 GPT-4와 비교하여 뛰어난 성능을 보이며, 다양한 테스트에서 우수한 결과를 보여주었습니다. 또한, GLM-4V-9B 모델은 고해상도 멀티모달 기능을 갖추고 있어 다양한 입력과 상황에 맞는 응답을 생성할 수 있습니다.
성능 비교
일반적인 작업
| 모델 | AlignBench | MT-Bench | IFEval | MMLU | C-Eval | GSM8K | MATH | HumanEval | NaturalCodeBench |
|---|---|---|---|---|---|---|---|---|---|
| Llama-3-8B-Instruct | 6.40 | 8.00 | 68.58 | 68.4 | 51.3 | 79.6 | 30.0 | 62.2 | 24.7 |
| ChatGLM3-6B | 5.18 | 5.50 | 28.1 | 66.4 | 69.0 | 72.3 | 25.7 | 58.5 | 11.3 |
| GLM-4-9B-Chat | 7.01 | 8.35 | 69.0 | 72.4 | 75.6 | 79.6 | 50.6 | 71.8 | 32.2 |
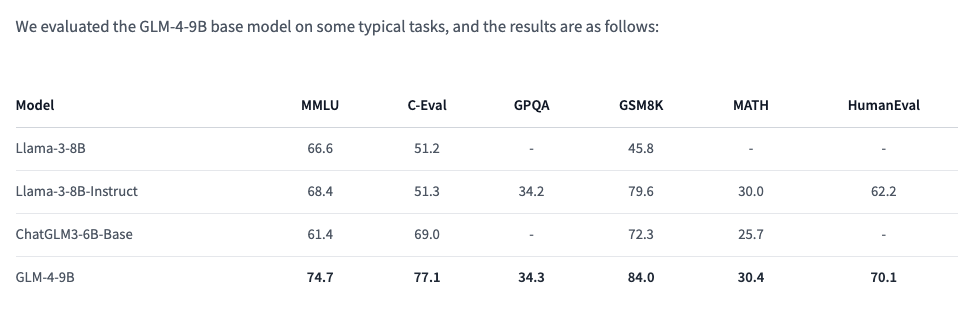
기본 모델
| 모델 | MMLU | C-Eval | GPQA | GSM8K | MATH | HumanEval |
|---|---|---|---|---|---|---|
| Llama-3-8B | 66.6 | 51.2 | - | 45.8 | - | 33.5 |
| Llama-3-8B-Instruct | 68.4 | 51.3 | 34.2 | 79.6 | 30.0 | 62.2 |
| ChatGLM3-6B-Base | 61.4 | 69.0 | 26.8 | 72.3 | 25.7 | 58.5 |
| GLM-4-9B | 74.7 | 77.1 | 34.3 | 84.0 | 30.4 | 70.1 |
GLM-4-9B는 사전 학습 동안 수학, 추론 및 코드 관련 지시 데이터를 추가했기 때문에 Llama-3-8B-Instruct도 비교 범위에 포함되었습니다.
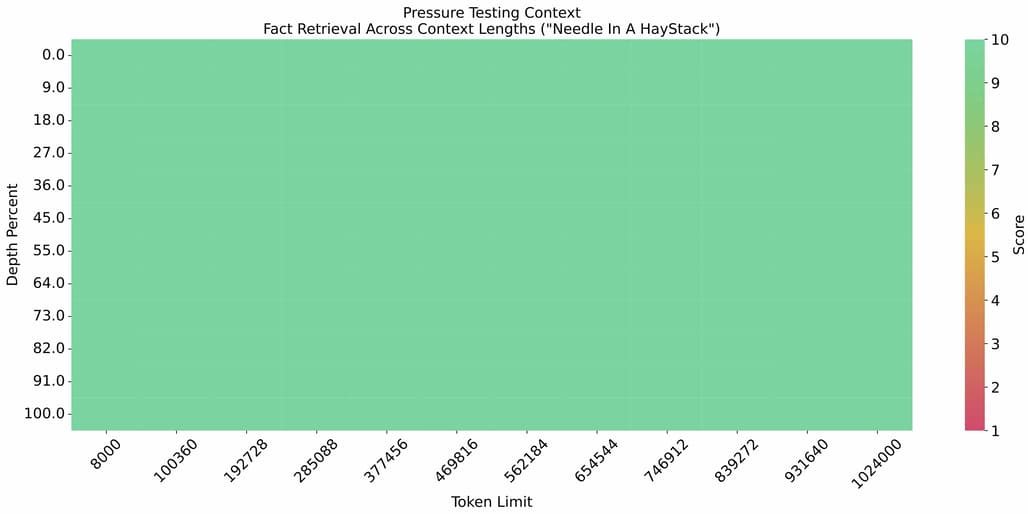
긴 컨텍스트 성능 비교
1M의 컨텍스트 길이로 needle-in-the-haystack 실험 수행 결과입니다:
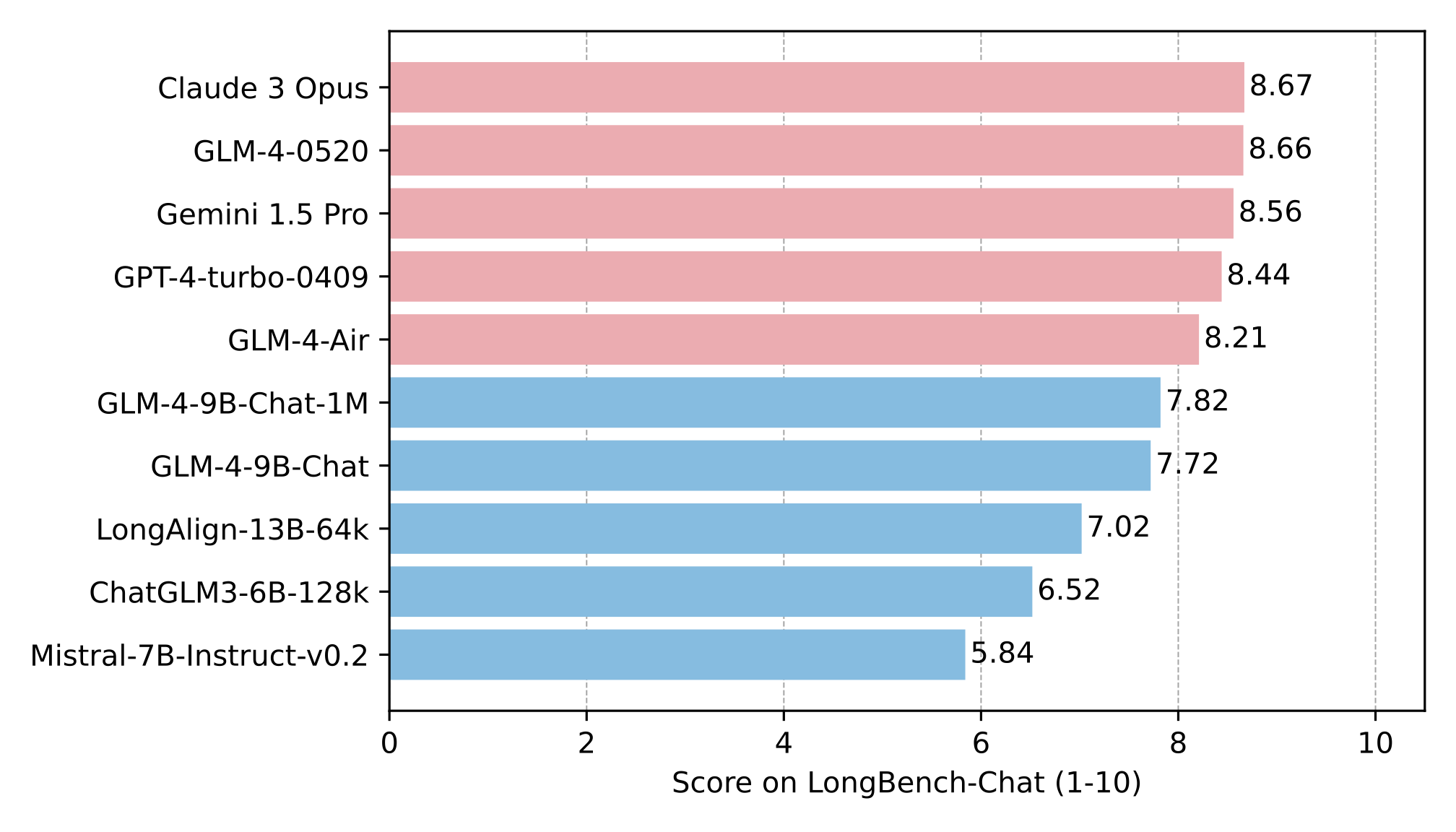
LongBench-Chat 벤치마크를 사용한 성능 평가 결과입니다:
다국어 성능 비교
GLM-4-9B-Chat과 Llama-3-8B-Instruct의 테스트는 여섯 가지 다국어 데이터 세트에서 수행되었습니다. 테스트 결과와 각 데이터 세트에 대해 선택된 언어는 다음 표에 나와 있습니다:
| 데이터 세트 | Llama-3-8B-Instruct | GLM-4-9B-Chat | 언어 |
|---|---|---|---|
| M-MMLU | 49.6 | 56.6 | 전체 |
| FLORES | 25.0 | 28.8 | ru, es, de, fr, it, pt, pl, ja, nl, ar, tr, cs, vi, fa, hu, el, ro, sv, uk, fi, ko, da, bg, no |
| MGSM | 54.0 | 65.3 | zh, en, bn, de, es, fr, ja, ru, sw, te, th |
| XWinograd | 61.7 | 73.1 | zh, en, fr, jp, ru, pt |
| XStoryCloze | 84.7 | 90.7 | zh, en, ar, es, eu, hi, id, my, ru, sw, te |
| XCOPA | 73.3 | 80.1 | zh, et, ht, id, it, qu, sw, ta, th, tr, vi |
함수 호출 성능 비교
Berkeley Function Calling Leaderboard에서의 테스트 결과입니다:
| 모델 | 전체 정확도 | AST 요약 | 실행 요약 | 관련성 |
|---|---|---|---|---|
| Llama-3-8B-Instruct | 58.88 | 59.25 | 70.01 | 45.83 |
| gpt-4-turbo-2024-04-09 | 81.24 | 82.14 | 78.61 | 88.75 |
| ChatGLM3-6B | 57.88 | 62.18 | 69.78 | 5.42 |
| GLM-4-9B-Chat | 81.00 | 80.26 | 84.40 | 87.92 |
멀티모달(Multimodal) 성능 비교
GLM-4V-9B는 시각적 이해 능력을 갖춘 다중 모드 언어 모델입니다. 주요한 벤치마크의 평가 결과는 다음과 같습니다:
| MMBench-EN-Test | MMBench-CN-Test | SEEDBench_IMG | MMStar | MMMU | MME | HallusionBench | AI2D | OCRBench | |
|---|---|---|---|---|---|---|---|---|---|
| gpt-4o-2024-05-13 | 83.4 | 82.1 | 77.1 | 63.9 | 69.2 | 2310.3 | 55 | 84.6 | 736 |
| gpt-4-turbo-2024-04-09 | 81.0 | 80.2 | 73.0 | 56.0 | 61.7 | 2070.2 | 43.9 | 78.6 | 656 |
| gpt-4-1106-preview | 77.0 | 74.4 | 72.3 | 49.7 | 53.8 | 1771.5 | 46.5 | 75.9 | 516 |
| InternVL-Chat-V1.5 | 82.3 | 80.7 | 75.2 | 57.1 | 46.8 | 2189.6 | 47.4 | 80.6 | 720 |
| LLaVA-Next-Yi-34B | 81.1 | 79 | 75.7 | 51.6 | 48.8 | 2050.2 | 34.8 | 78.9 | 574 |
| Step-1V | 80.7 | 79.9 | 70.3 | 50.0 | 49.9 | 2206.4 | 48.4 | 79.2 | 625 |
| MiniCPM-Llama3-V2.5 | 77.6 | 73.8 | 72.3 | 51.8 | 45.8 | 2024.6 | 42.4 | 78.4 | 725 |
| Qwen-VL-Max | 77.6 | 75.7 | 72.7 | 49.5 | 52 | 2281.7 | 41.2 | 75.7 | 684 |
| Gemini 1.0 Pro | 73.6 | 74.3 | 70.7 | 38.6 | 49 | 2148.9 | 45.7 | 72.9 | 680 |
| Claude 3 Opus | 63.3 | 59.2 | 64 | 45.7 | 54.9 | 1586.8 | 37.8 | 70.6 | 694 |
| GLM-4V-9B | 81.1 | 79.4 | 76.8 | 58.7 | 47.2 | 2163.8 | 46.6 | 81.1 | 786 |
사용 방법
GLM-4-9B-Chat 모델은 Hugging Face의 transformers 라이브러리 및 vLLM 등을 사용하여 추론할 수 있으며, 각각에 대한 사용하는 방법은 다음과 같습니다.
![]() 멀티모달 모델인 GLM-4V-9B는 아직 vLLM을 사용한 추론 방식을 지원하지 않습니다.
멀티모달 모델인 GLM-4V-9B는 아직 vLLM을 사용한 추론 방식을 지원하지 않습니다.
하드웨어 구성 및 시스템 요구 사항은 GLM-4 GitHub 저장소의 해당 문서에서 확인하하실 수 있습니다.
 Hugging Face의 transformers를 사용한 예시
Hugging Face의 transformers를 사용한 예시
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 장치를 GPU로 설정
device = "cuda"
# 사전 학습된 토크나이저를 로드
tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4-9b-chat", trust_remote_code=True)
# 사용자 입력 설정
query = "Please tell me about PyTorch Korea User Group"
# 입력 텍스트를 모델 입력 형식으로 변환
inputs = tokenizer.apply_chat_template([{"role": "user", "content": query}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
)
# 입력 데이터를 GPU로 이동
inputs = inputs.to(device)
# 사전 학습된 언어 모델을 로드
model = AutoModelForCausalLM.from_pretrained(
"THUDM/glm-4-9b-chat",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
# 텍스트 생성에 사용할 매개변수 설정
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
# 텍스트 생성
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
# 입력 텍스트를 제외한 생성된 텍스트만 추출
outputs = outputs[:, inputs['input_ids'].shape[1]:]
# 생성된 텍스트를 디코딩하여 출력
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
vLLM 백엔드를 사용한 예시
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# GLM-4-9B-Chat
# OOM 문제가 발생하면 max_model_len을 줄이거나 tp_size를 늘려보세요
max_model_len, tp_size = 131072, 1
model_name = "THUDM/glm-4-9b-chat"
prompt = [{"role": "user", "content": "Please tell me about PyTorch Korea User Group"}]
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,
tensor_parallel_size=tp_size,
max_model_len=max_model_len,
trust_remote_code=True,
enforce_eager=True,
# GLM-4-9B-Chat-1M에서 OOM 문제가 발생하면 다음 매개변수를 활성화해보세요
# enable_chunked_prefill=True,
# max_num_batched_tokens=8192
)
stop_token_ids = [151329, 151336, 151338]
sampling_params = SamplingParams(temperature=0.95, max_tokens=1024, stop_token_ids=stop_token_ids)
inputs = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
outputs = llm.generate(prompts=inputs, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)
라이선스
GLM-4 모델 코드는 Apache 2.0 라이선스에 따라 공개 및 배포되었습니다.
GLM-4 모델 가중치에 대한 사용은 GLM-4 모델 라이선스를 따라야 합니다. 이 라이선스는 학술적 연구 목적으로는 무료 사용이 가능하나, 상업적 사용 시에는 등록이 필요합니다. 모델 사용 중 생기는 분쟁에 대해서는 중국 법률에 따릅니다.
 GLM-4 GitHub 저장소
GLM-4 GitHub 저장소
https://github.com/THUDM/GLM-4/blob/main/README_en.md
GLM-4 모델 가중치 저장소
GLM-4-9B 모델
GLM-4-9B-Chat 모델
GLM-4-9B-Chat-1M 모델
GLM-4V-9B (Multimodal) 모델
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()