
GLM-OCR 모델 소개
GLM-OCR은 중국의 선도적인 AI 연구 기업인 Zhipu AI(Z.ai)에서 공개한 0.9B(약 9억 개) 규모의 초경량 멀티모달 모델입니다. 이 모델은 단순히 이미지 내의 텍스트를 추출하는 전통적인 광학 문자 인식(OCR)의 범위를 넘어, 문서의 레이아웃, 도표, 수식, 그리고 서식 정보를 완벽하게 이해하고 이를 구조화된 데이터로 변환하는 데 특화되어 있습니다. 최근 대규모 언어 모델(LLM) 시장이 거대화 경쟁을 벌이는 가운데, GLM-OCR은 10억 개 미만의 파라미터만으로도 특정 도메인(문서 처리)에서 거대 모델에 버금가는 성능을 낼 수 있음을 증명하며 '효율적인 AI'의 새로운 기준을 제시하고 있습니다.
디지털 전환(Digital Transformation)이 가속화되면서 기업과 개인은 방대한 양의 종이 문서나 PDF 파일을 편집 가능한 데이터로 변환해야 하는 과제에 직면해 있습니다. 기존의 레거시 OCR 솔루션들은 텍스트의 위치를 찾는 데는 능숙했으나, 복잡한 표의 셀 병합 구조를 파악하거나 수학 공식과 같은 특수 기호를 코드로 변환하는 데에는 한계가 명확했습니다. 이를 해결하기 위해 GPT-4o나 Gemini 1.5 Pro와 같은 최신 멀티모달 모델들이 활용되었으나, 이러한 모델들은 API 비용이 높고 데이터 보안 문제로 인해 온프레미스(On-premise) 환경에 구축하기 어렵다는 단점이 있었습니다.
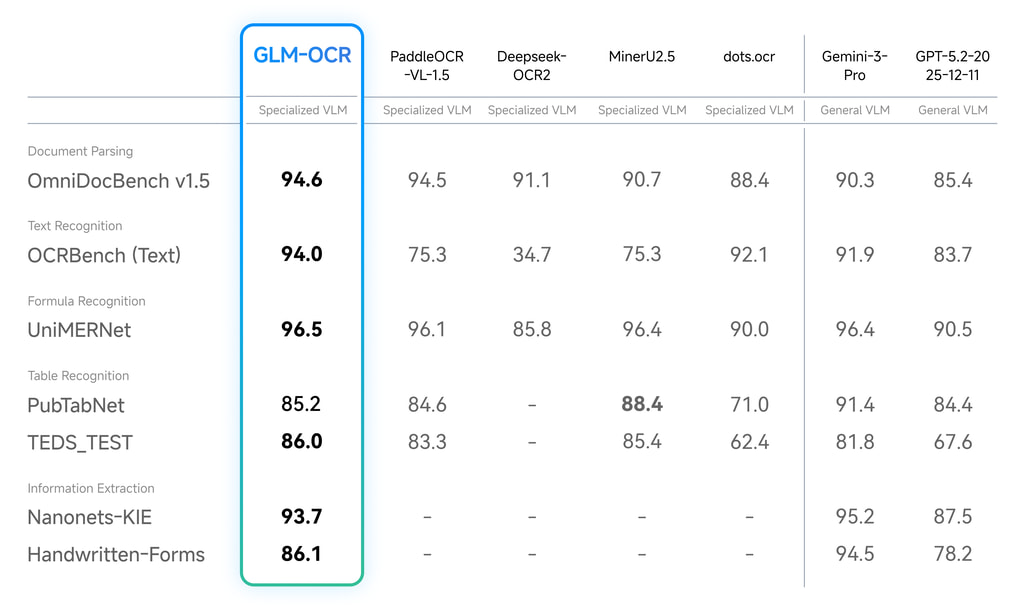
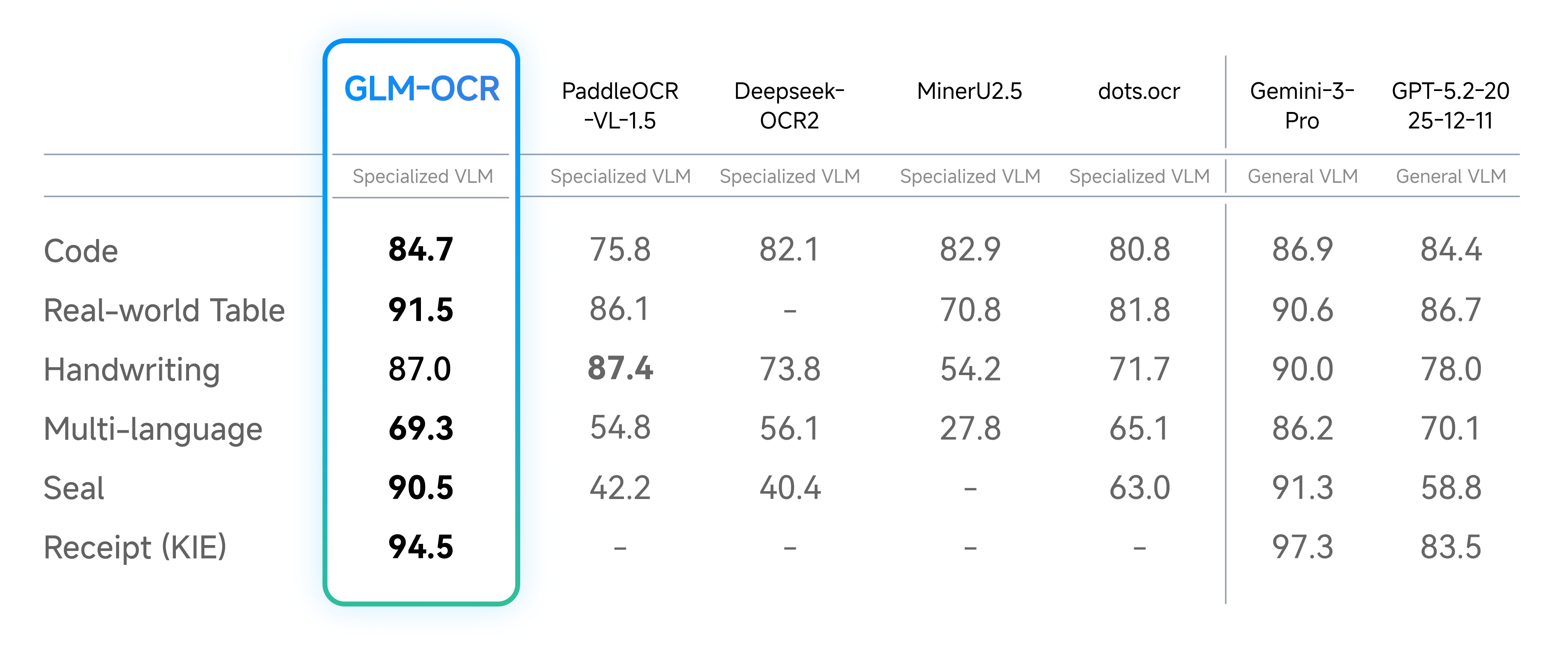
GLM-OCR은 이러한 시장의 간극을 정확히 타격합니다. 이 모델은 일반적인 소비자용 그래픽 카드에서도 구동될 만큼 가벼운 사이즈를 자랑하면서도, OmniDocBench V1.5 벤치마크에서 94.62점을 기록하며 현재 공개된 오픈소스 모델 중 가장 뛰어난 성능(SOTA)을 보여줍니다. 이는 개발자들이 값비싼 클라우드 자원 없이도 로컬 환경에서 고성능의 문서 파싱 파이프라인을 구축할 수 있게 되었음을 의미하며, 특히 기밀 문서를 다루는 금융, 법률, 연구 분야에서 큰 파급력을 가질 것으로 예상됩니다.
GLM-OCR vs. 기존 OCR 모델/기술 비교
GLM-OCR의 등장이 갖는 의미를 명확히 이해하기 위해서는 기존 기술들과의 비교가 필수적입니다. 과거의 OCR 기술과 최신 거대 언어 모델 사이에서 GLM-OCR은 독보적인 위치를 점하고 있습니다.
전통적인 OCR 엔진인 Tesseract나 초기 딥러닝 기반 모델들은 이미지를 텍스트로 변환하는 '인식(Recognition)' 단계에 머물러 있었습니다. 이들은 문단이 나뉘어 있거나 표가 포함된 복잡한 문서에서 텍스트의 순서를 뒤죽박죽으로 섞어 놓거나, 디자인 요소를 텍스트로 오인하는 경우가 많았습니다. 반면, GLM-OCR은 시각 정보를 언어 모델과 결합하여 문서의 '구조'를 이해합니다. 즉, 사람이 문서를 읽는 것처럼 제목과 본문을 구분하고, 표의 행과 열을 논리적으로 파악하여 재구성할 수 있습니다.

또한, 범용 멀티모달 모델(General VLM)들과 비교했을 때 GLM-OCR은 '가성비'와 '속도' 면에서 압도적인 우위를 점합니다. 수백억, 수천억 개의 파라미터를 가진 범용 모델들은 문서 처리 외에도 시를 쓰거나 코딩을 하는 등 다양한 작업이 가능하지만, 단순한 영수증 처리나 논문 변환을 위해 사용하기에는 연산 자원의 낭비가 심합니다. GLM-OCR은 오직 '문서 이해'라는 하나의 목적을 위해 최적화되었기 때문에, 동일한 하드웨어 자원에서 훨씬 더 많은 양의 문서를 더 빠르게 처리할 수 있습니다. 실제로 0.9B라는 크기는 최신 스마트폰이나 엣지 디바이스에서도 추론이 가능한 수준으로, 서버 비용을 획기적으로 절감할 수 있는 핵심 요인이 됩니다.
GLM-OCR 모델의 주요 특징
GLM-OCR은 GLM-V 아키텍처를 기반으로 시각적 정보와 언어적 이해를 결합하여 설계되었습니다. 특히, GLM-OCR은 단순한 모델 가중치의 공개를 넘어, 실제 프로덕션 환경에서 즉시 활용 가능한 수준의 완성도를 갖추고 있습니다. GLM-OCR 모델의 주요한 특징은 다음과 같습니다:
시각 언어 모델(VLM) 기반의 정교한 아키텍처
GLM-OCR의 기술적 근간은 GLM-V 아키텍처에 있습니다. 이 모델은 크게 이미지를 보는 '눈' 역할을 하는 CogViT Visual Encoder와, 본 내용을 해석하고 글로 써내는 '두뇌' 역할을 하는 GLM-0.5B Language Decoder로 구성되어 있습니다.
특히 주목할 점은 이 두 모듈을 연결하는 방식입니다. 시각 인코더가 추출한 고해상도 이미지의 특징(Feature)들은 MLP(Multi-Layer Perceptron) 어댑터를 통해 언어 모델이 이해할 수 있는 토큰 형태로 변환됩니다. 이 과정에서 모델은 텍스트의 내용뿐만 아니라 폰트의 크기, 굵기, 위치 정보와 같은 시각적 맥락까지 함께 학습하게 됩니다.
이러한 구조 덕분에 GLM-OCR은 단순한 글자 인식을 넘어, 해당 글자가 제목인지 주석인지를 구분하는 의미론적 파싱이 가능합니다.
고해상도 처리 및 다국어 지원 능력
문서 처리 AI의 가장 큰 난관 중 하나는 해상도 문제입니다. 작은 글씨가 빽빽하게 적힌 계약서나 논문을 저해상도로 처리할 경우 인식률이 급격히 떨어지기 때문입니다. GLM-OCR은 이를 극복하기 위해 최대 8K 해상도(7680×4320 픽셀) 의 이미지를 입력받을 수 있도록 설계되었습니다. 이는 A4 용지뿐만 아니라, 복잡한 설계도면이나 포스터와 같은 대형 문서도 선명하게 인식할 수 있음을 의미합니다.
또한, 글로벌 서비스 적용을 위해 다국어 지원 능력도 강화되었습니다. 영어와 중국어(간체/번체)는 물론, 한국어와 일본어까지 총 8개 언어를 유창하게 인식합니다.
특히 한국어와 같이 자음과 모음이 결합되는 복잡한 문자 체계나, 한자와 영어가 혼용된 기술 문서에서도 뛰어난 인식 정확도를 보여줍니다. 이는 다국적 기업의 문서 관리 시스템이나 번역 서비스를 위한 전처리 도구로서 높은 활용 가치를 가집니다.
구조화된 데이터 출력과 편집 가능성


개발자 관점에서 GLM-OCR의 가장 매력적인 기능은 바로 출력 데이터의 '활용성'입니다. 이 모델은 이미지 내의 정보를 단순 텍스트로 뱉어내는 것이 아니라, Markdown이나 JSON과 같은 구조화된 포맷으로 출력합니다. 예를 들어, 논문에 포함된 복잡한 수학 공식은 즉시 컴파일 가능한 LaTeX 코드로 변환되며, 재무제표의 표는 Markdown 테이블 문법으로 깔끔하게 정리되어 나옵니다.
이러한 기능은 RAG(검색 증강 생성) 시스템을 구축할 때 결정적인 역할을 합니다. RAG 시스템의 성능은 입력되는 데이터의 품질에 좌우되는데, PDF의 표나 차트 정보가 깨져서 입력되면 검색 정확도가 떨어질 수밖에 없습니다. GLM-OCR을 통해 문서를 구조화된 마크다운으로 변환하여 벡터 데이터베이스에 저장하면, LLM이 문맥을 훨씬 더 정확하게 파악할 수 있어 전체적인 AI 서비스의 품질을 높일 수 있습니다.
다양한 배포 환경과 최적화된 추론 엔진
Zhipu AI는 GLM-OCR을 공개하며 개발자들이 쉽게 모델을 도입할 수 있도록 다양한 추론 프레임워크를 공식적으로 지원하고 있습니다.
먼저, 프로덕션 환경을 위해서는 vLLM 지원이 가장 돋보입니다. vLLM은 메모리 효율성을 극대화한 PagedAttention 기술을 사용하여 높은 처리량(Throughput)을 보장하는 라이브러리입니다. 사용자는 vLLM을 통해 OpenAI 호환 API 서버를 구축할 수 있으며, 이를 통해 기존에 GPT-4 등을 사용하던 코드를 단 몇 줄의 수정만으로 GLM-OCR로 전환할 수 있습니다.
또한, 로컬 테스트나 개인 연구자를 위해 Ollama와 SGLang도 지원합니다. Ollama를 사용하면 복잡한 파이썬 환경 설정 없이 터미널 명령어 하나로 모델을 다운로드하고 실행해 볼 수 있어 접근성이 매우 높습니다. 더불어 하드웨어 요구 사항도 매우 낮아, FP16 정밀도 기준으로 약 4~6GB의 VRAM만 있으면 모델을 구동할 수 있습니다. 이는 고가의 데이터센터용 GPU가 아닌, 일반적인 게이밍 노트북에 탑재된 NVIDIA RTX 3060 수준의 그래픽 카드로도 충분히 고성능 OCR 서버를 운영할 수 있음을 의미합니다.
GLM-OCR 모델 사용 예시 (vLLM)
다음은 vLLM을 사용하여 OpenAI 호환 API 서버를 띄우고 요청을 보내는 예시입니다:
# uv를 사용한 vLLM 설치
uv pip install -U vllm --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightly
# vLLM 서버 실행 예.
vllm serve zai-org/GLM-OCR --port 8080 --trust-remote-code
GLM-OCR은 vLLM 외 SGLang/Ollma, 또는 Apple Silicon을 위한 MLX 등을 지원하며, 이에 대한 상세한 내용은 GitHub 저장소 또는 Hugging Face를 참고해주세요.
서버가 정상적으로 실행되었다면, 다음과 같이 OpenAI Client를 사용하여 서버에 접근할 수 있습니다(단, pip install openai 등으로 이미 OpenAI Client가 설치되어 있어야 합니다):
# Python 클라이언트 예시
import openai
client = openai.Client(
base_url="http://localhost:8080/v1",
api_key="EMPTY"
)
response = client.chat.completions.create(
model="zai-org/GLM-OCR",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "이미지의 표를 마크다운으로 변환해줘."},
{"type": "image_url", "image_url": {"url": "https://example.com/doc.jpg"}}
]
}]
)
print(response.choices[0].message.content)
또는, GLM-OCR SDK를 설치한 뒤, glmocr 명령어를 사용하여 CLI 등에서 직접 파싱할 수도 있습니다. 다음은 glmocr 명령어 사용 예시입니다:
# 한 장의 이미지 파싱 예시
glmocr parse examples/source/code.png
# 디렉토리 내의 모든 이미지 파싱 예시
glmocr parse examples/source/
# 출력 경로 지정 예시
glmocr parse examples/source/code.png --output ./results/
라이선스
GLM-OCR 프로젝트는 구성 요소별로 라이선스가 다르게 적용되므로 주의가 필요합니다.
- 먼저, GLM-OCR 모델 가중치는 상업적 이용이 가능한 MIT License를 따릅니다.
- 레이아웃 분석 코드 (PP-DocLayout-V3) 및 리포지토리 코드는 Apache License 2.0을 따릅니다.
사용자는 프로젝트 활용 시 위 두 가지 라이선스 정책을 모두 준수해야 합니다.
 GLM-OCR 공식 문서
GLM-OCR 공식 문서
 GLM-OCR Hugging Face 모델 카드
GLM-OCR Hugging Face 모델 카드
 GLM-OCR 프로젝트 GitHub 저장소
GLM-OCR 프로젝트 GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()