Glyph-ByT5: 정확한 시각적 텍스트 렌더링을 위해 ByT5를 개선한 Text Encoder
소개
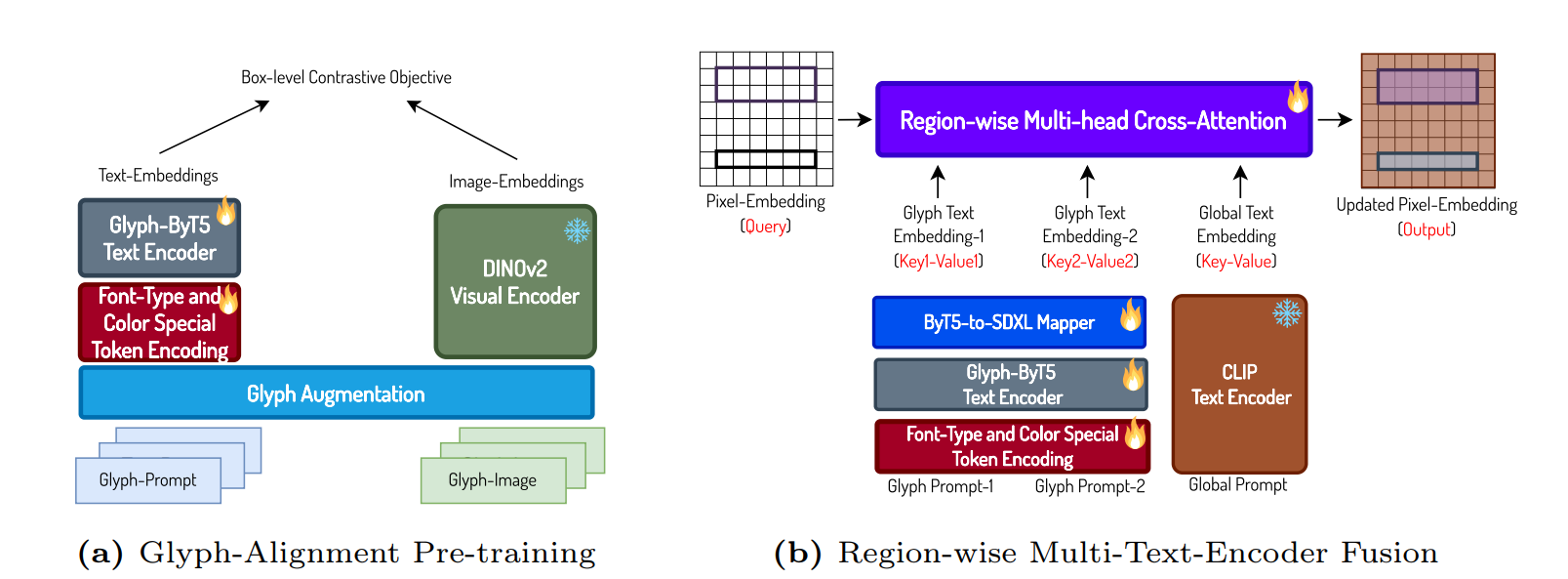
Glyph-ByT5는 텍스트 인코더의 문제점을 해결하기 위해 개발된 커스터마이즈된 텍스트 인코더(Text Encoder)입니다. 비주얼 텍스트 렌더링의 정확성을 높이기 위해 ByT5 인코더를 문자 인식 기능을 강화하고, 글리프(Glyph)와의 정렬을 최적화하여 튜닝하였습니다.
이를 통해 Glyph-ByT5는 텍스트 렌더링의 정확성을 크게 향상시켰으며, 새로운 Glyph-SDXL 모델과의 통합을 통해 텍스트 렌더링 정확도를 20% 미만에서 90%에 가깝게 개선했습니다. 또한, 텍스트 단락 렌더링에서도 뛰어난 성능을 보이며, 자동 다중 라인 레이아웃을 사용해 수십에서 수백 글자의 철자 정확도를 유지합니다. 이 모델은 또한 고품질의 사실적인 이미지를 통해 실제 장면 텍스트 렌더링에서도 현저한 성능 향상을 보여주었습니다.

기존의 텍스트 인코더는 비주얼 텍스트 렌더링에서 문자 인식과 글리프 정렬에 있어 부족함이 있었습니다. ByT5 인코더는 문자 인식에는 강점이 있으나, 글리프 정렬에는 한계가 있었습니다. Glyph-ByT5는 이러한 문제를 해결하기 위해 두 가지 요구사항을 모두 충족시키는 방향으로 개발되었습니다. Glyph-SDXL 모델과의 통합을 통해 기존 SDXL 모델 대비 텍스트 렌더링 정확도를 대폭 개선했습니다.
![]()
![]()
![]() : 이 프로젝트는 현재 영어와 중국어 글자들만 지원하고 있습니다. 곧 체크포인트 공개 예정이라고 하니, 한국어를 지원하는 모델이 추가될 수도 있을 것으로 보입니다.
: 이 프로젝트는 현재 영어와 중국어 글자들만 지원하고 있습니다. 곧 체크포인트 공개 예정이라고 하니, 한국어를 지원하는 모델이 추가될 수도 있을 것으로 보입니다. ![]()
We provide a English version and a multilingual extension (supporting 1000 common Chinese characters and English) of our method.
주요 기능
-
문자 인식 기능: ByT5 인코더의 문자 인식 기능을 강화하여 글리프와의 정렬을 최적화.
-
텍스트 렌더링 정확도 향상: 렌더링 정확도를 20% 미만에서 90%에 가깝게 개선.
-
텍스트 단락 렌더링: 자동 다중 라인 레이아웃을 사용해 수십에서 수백 글자의 철자 정확도를 유지.
-
사실적인 이미지 생성: 고품질의 사실적인 이미지로 실제 장면 텍스트 렌더링 성능 향상.
Glyph-ByT5 이해를 위한 추가 설명
Glyph 용어 소개
Glyph는 컴퓨터 그래픽 분야에서 문자나 기호의 형태를 본따 만든 그래픽 심볼을 뜻합니다. 조각(Carving)이라는 뜻의 그리스어에서 유래되었으며, Glyph로 알파벳 문자, 숫자 또는 다양한 심볼을 나타낼 수 있습니다. Glyph에 대해서는 Wikipedia의 설명을 더 참고하시거나, 아래 예시를 참고해주세요. 아래 예시는 Glyph-ByT5 모델로 생성한 이미지들로 Glyph에 대해서 직관적으로 이해하실 수 있습니다.

ByT5 모델 소개
ByT5는 Google에서 개발 및 공개한 모델로, 기존의 T5(Text-to-Text Transfer Transformer) 모델을 개선한 모델입니다. 기존의 자연어 처리 모델은 텍스트를 토큰으로 분할하여 처리하는 반면, ByT5는 텍스트를 바이트 단위로 직접 처리하는 것이 특징입니다.
ByT5는 이러한 방식의 도입으로 언어에 상관없이 일관된 성능을 유지할 수 있으며, 특히 다국어 및 희귀 언어 처리에 강점을 보입니다. 옐르 들어, 다이어크리틱(발음 구별 기호) 복원, 철자 교정, 다국어 그래프-음소 변환 등과 같은 언어 간의 다양한 텍스트 변환 작업을 수행할 수 있습니다.
ByT5는 토큰 기반 모델인 mT5와 자주 비교됩니다. mT5는 여러 언어에서 뛰어난 성능을 보이는 모델이지만, 텍스트를 토큰으로 분할하는 과정에서 정보 손실이 발생할 수 있습니다. 반면, ByT5는 텍스트를 바이트 단위로 처리하기 때문에 이러한 정보 손실을 최소화할 수 있습니다. 또한, ByT5는 파라미터 수가 적으면서도 mT5와 유사한 성능을 보이며, 다국어 처리에 있어서 더 효율적입니다.
ByT5 모델에 대해서는 다음 링크들을 참고해주세요.
-
ByT5에 대한 arXiv 공개 논문: [2204.03067] ByT5 model for massively multilingual grapheme-to-phoneme conversion
-
ByT5 모델 GitHub 저장소: GitHub - google-research/byt5
Glyph-ByT5 사용법
Glyph-ByT5 모델은 문자 인식과 글리프 정렬 기능이 강화된 인코더입니다. 이를 SDXL 모델과 통합하여 Glyph-SDXL 모델을 사용하면 텍스트 렌더링 정확도를 크게 향상시킬 수 있습니다.
Glyph-ByT5 GitHub 사용법 페이지에서 제공하는 코드를 설치한 뒤, 예시로 제공되는 설정들을 사용 및 참고하여 직접 실행해볼 수 있습니다:
python inference.py configs/glyph_sdxl_albedo.py [path-to-checkpoint-folder] [path-to-inference-ann-json] --out_folder [path-to-output-folder] --device cuda --sampler dpm/euler
![]()
![]()
![]() : 이 프로젝트는 현재 영어와 중국어 글자들만 지원하고 있습니다. 곧 체크포인트 공개 예정이라고 하니, 한국어를 지원하는 모델이 추가될 수도 있을 것으로 보입니다.
: 이 프로젝트는 현재 영어와 중국어 글자들만 지원하고 있습니다. 곧 체크포인트 공개 예정이라고 하니, 한국어를 지원하는 모델이 추가될 수도 있을 것으로 보입니다. ![]()
We provide a English version and a multilingual extension (supporting 1000 common Chinese characters and English) of our method.
Glyph-ByT5 관련 더 읽어보기
Glyph-ByT5 프로젝트 홈페이지
Glyph-ByT5 논문
Glyph-ByT5 GitHub 저장소
https://github.com/AIGText/Glyph-ByT5
ByT5 관련 더 읽어보기
ByT5 논문
ByT5 GitHub 저장소
https://github.com/google-research/byt5
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()