최근 1년 동안 대형 언어 모델의 추론 능력을 연구하고 개선하는 데 집중해왔으며, 특히 산술 및 수학 문제 해결 능력에 주목했습니다. 이제 수학 특화 대형 언어 모델인 Qwen2 시리즈의 새로운 모델 Qwen2-Math와 Qwen2-Math-Instruct-1.5B/7B/72B를 소개합니다. 이 모델들은 Qwen2 LLM(대형 언어 모델)을 기반으로 하며, 수학적 성능 면에서 오픈 소스 모델은 물론 GPT-4o와 같은 상용 모델을 능가합니다. 우리는 Qwen2-Math가 복잡한 수학 문제 해결에 기여하기를 기대합니다.
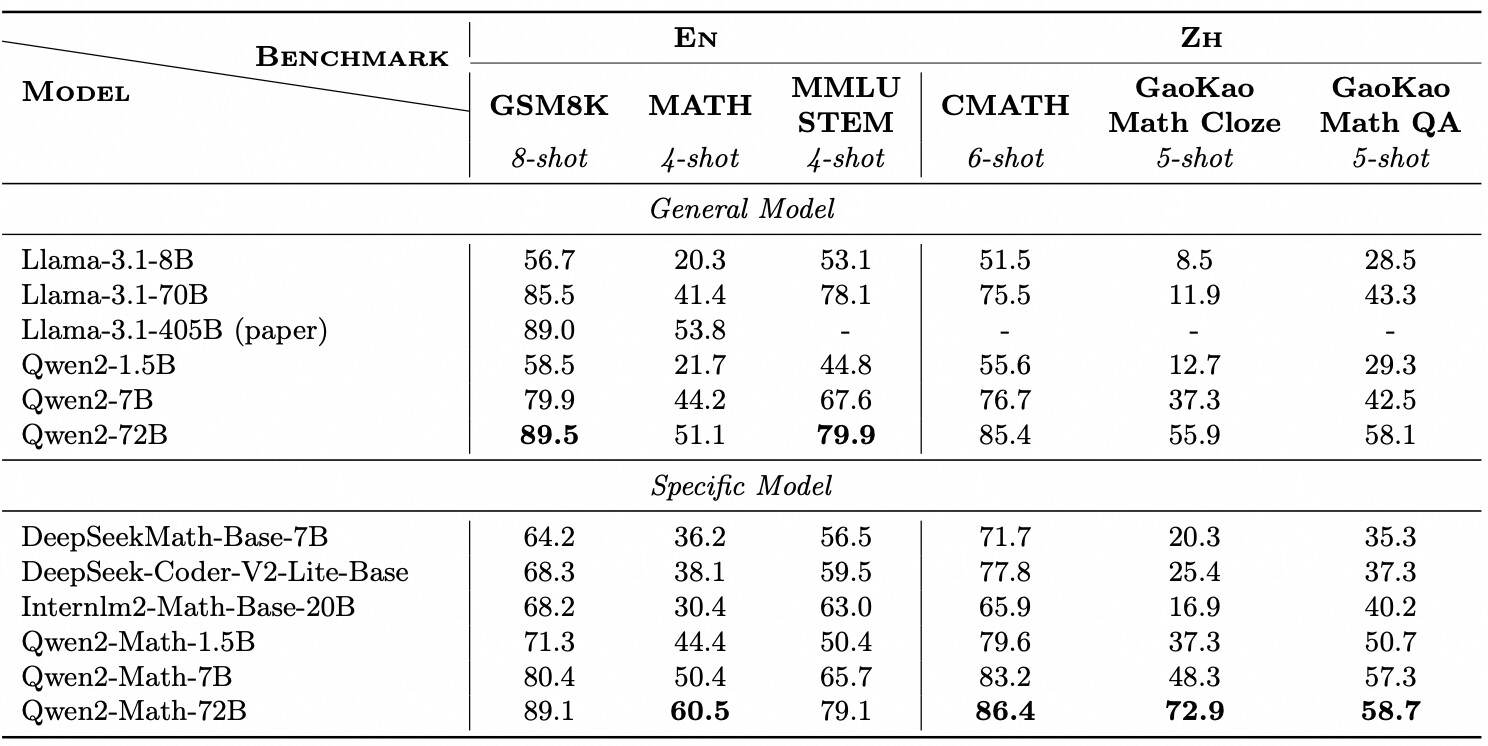
Qwen2-Math의 기본 모델들은 Qwen2-1.5B/7B/72B에서 초기화되었으며, 수학 전용 데이터셋으로 사전 학습되었습니다. 이 데이터셋에는 대규모 고품질의 수학 웹 텍스트, 책, 코드, 시험 문제 및 Qwen2가 생성한 수학 사전 학습 데이터가 포함되어 있습니다. 이 모델들은 GSM8K, Math, MMLU-STEM과 같은 영어 수학 벤치마크와 CMATH, GaoKao Math Cloze, GaoKao Math QA와 같은 중국어 수학 벤치마크에서 평가되었습니다.
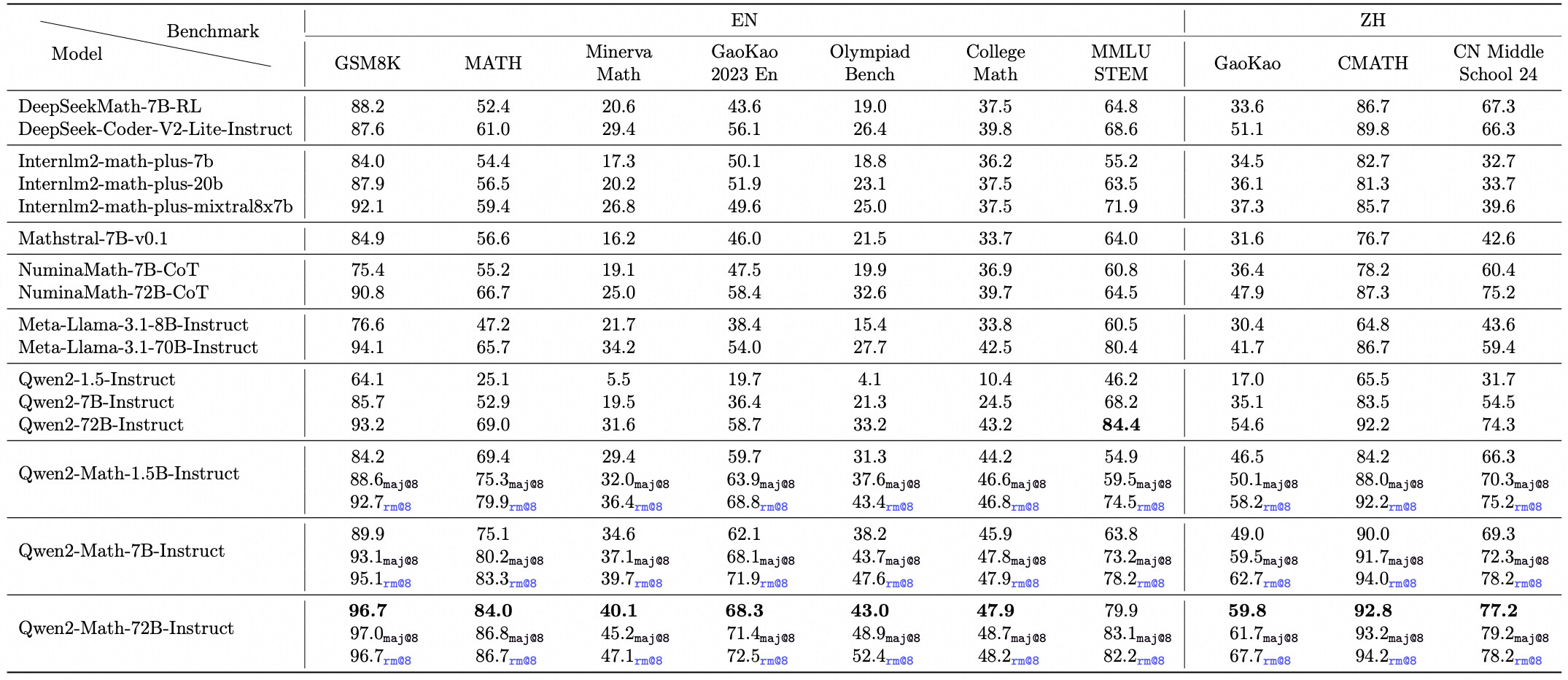
Qwen2-Math-72B를 기반으로 한 수학 전용 보상 모델을 먼저 학습한 후, 이 신호를 활용하여 거부 샘플링(Rejection Sampling)과 GRPO(그룹 상대 정책 최적화) 방법을 적용해 모델을 조정했습니다. 이 모델은 영어와 중국어 수학 벤치마크 모두에서 평가되었으며, 특히 복잡한 수학 경연 대회에서 뛰어난 성능을 보여주었습니다.
사례 연구
Qwen2-Math가 수학 경연 문제를 해결하는 능력을 테스트한 사례들을 소개합니다. 몇 가지 실험 결과와 사례 연구에서 Qwen2-Math가 간단한 수학 경연 문제를 해결할 수 있는 능력을 확인할 수 있었습니다. 다만 모든 결과가 올바른 것은 아니므로 주의가 필요합니다. 자세한 사례들은 프로잭트 홈페이지의 Case Study 섹션을 참고해주세요.
데이터 정제
모델의 사전 학습과 사후 학습 데이터셋에서 오염된 데이터를 제거하기 위한 정제 과정을 거쳤습니다. 특히, GSM8K, MATH와 같은 데이터셋과 중복된 샘플을 제거했으며, 사후 학습 데이터에서도 오염된 데이터를 추가로 제거했습니다.
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다.
![[GN] Alibaba, Qwen2-Math 모델 공개](https://discuss.pytorch.kr/uploads/default/original/2X/5/573a8753fdaef1cebea43ff910b44419429d5124.jpeg)
 알려드립니다
알려드립니다