GPT-4o는 이미지를 어떻게 인코딩할까?
![[GN] GPT-4o는 이미지를 어떻게 인코딩할까?](https://discuss.pytorch.kr/uploads/default/original/2X/8/8f33c58db85e569603baf88ea9c9069eb5350a14.png)
- GPT-4o는 고해상도 모드에서 사용되는 각 512x512 타일을 처리하는 데 170 토큰을 부과함. 약 0.75 토큰/단어의 비율로 보면 이는 그림 한 장이 약 227 단어와 같다는 것
- "그림 한 장이 천 마디 말보다 낫다"는 말과 비교했을 때 약 4배 차이임
- 170이라는 숫자는 기괴할 정도로 특이한 숫자임. OpenAI는 가격 책정에서 "20달러" 또는 "0.50달러"와 같은 반올림된 숫자나 내부 차원에 2와 3의 거듭제곱을 사용함
- 170과 같은 숫자를 선택한 이유는 무엇일까? 프로그래밍에서 코드베이스에 설명 없이 그냥 던져진 숫자를 "매직 넘버"라고 하는데, 170은 상당히 눈에 띄는 매직 넘버임
- 이미지 비용을 토큰 수로 변환하는 이유는 무엇일까? 단순히 청구 목적이라면 타일당 비용을 나열하는 것이 덜 혼란스러울 것임
- OpenAI가 170을 선택한 것이 단순히 문자 그대로 사실이기 때문이라면 어떨까? 이미지 타일이 실제로 170개의 연속적인 임베딩 벡터로 표현된다면 어떨까?
임베딩
- 트랜스포머 모델에 대해 먼저 상기해야 할 점은 이산 토큰이 아닌 벡터에서 작동한다는 것임
- 입력은 벡터여야 하며, 그렇지 않으면 트랜스포머의 핵심인 내적 유사도가 의미가 없을 것임
- 토큰의 전체 개념은 전처리 단계임: 텍스트는 토큰으로 변환되고 토큰은 트랜스포머 모델의 첫 번째 레이어에 도달하기 전에 임베딩 모델에 의해 임베딩 벡터로 변환됨
- 예를 들어, Llama 3은 내부적으로 4,096개의 특징 차원을 사용함
- "My very educated mother just served us nine pizzas."라는 문장을 보면
- BPE에 의해 10개의 정수 토큰(마침표 포함)으로 변환된 다음, 각각 임베딩 모델에 의해 4,096차원 벡터로 변환되어 10x4096 행렬이 됨
- 이것이 트랜스포머 모델에 대한 "진짜" 입력임
- 그러나 이러한 벡터가 반드시 텍스트 임베딩 모델에서 나와야 한다는 법칙은 없음
- 텍스트 데이터에 잘 작동하는 전략이지만, 트랜스포머에 피드하려는 다른 형식의 데이터가 있다면 간단히 다른 임베딩 전략을 사용할 수 있음
- OpenAI가 2021년에 CLIP 임베딩 모델을 발표했기 때문에 이러한 방향으로 생각하고 있다는 것을 알고 있음
- CLIP은 텍스트와 이미지를 동일한 의미 벡터 공간에 임베드하여 코사인 유사도를 사용하여 텍스트 문자열과 관련된 이미지나 다른 이미지와 의미적으로 유사한 이미지를 찾을 수 있음
- 그러나 CLIP은 전체 이미지를 단일 벡터로 임베드하며, 170개는 아님. GPT-4o는 이미지(및 마찬가지로 비디오, 음성 및 기타 종류의 데이터)를 표현하기 위해 내부적으로 다른 고급 전략을 사용해야 함. 그래서 "omnimodal"인 것임
- 특히 이미지 데이터에 대해 해당 전략이 뭔지 추론해 보기로 함
특징 차원의 수
- GPT-4o가 임베딩 벡터를 표현하기 위해 내부적으로 사용하는 차원 수를 추정해 보면 독점적이기 때문에 실제 숫자는 알 수 없지만, 합리적인 가정을 할 수 있음
- OpenAI는 2의 거듭제곱을 좋아하는 것 같고, 때로는 3의 단일 인수를 혼합함
- 예를 들어 ada-002 임베딩에는 1,536을, text-embedding-3-large에는 3,072를 사용함
- GPT-3은 전체적으로 12,288 차원을 사용하는 것으로 알려져 있음
- GPT-4o는 해당 매개변수를 유지하거나 증가시켰을 가능성이 있음
- GPT-3에서 GPT-4o로 임베딩 수가 감소했을 것 같지는 않지만 가능함
- GPT-4 Turbo와 같은 릴리스는 실제로 이전 버전보다 더 빠르고 저렴했으며, 개발자들이 작은 크기가 품질 면에서 동등하게 좋다는 벤치마크 결과를 갖고 있었다면 임베딩 차원 축소가 그 일부였을 수 있음
- GPT-4o 내부에서 사용되는 특징 차원의 수는 다음 중 하나일 가능성이 높음: 1536, 2048, 3072, 4096, 12228, 16384, 24576
- GPT-4o가 임베딩 벡터의 차원에 12,228을 사용한다고 가정하겠음. 2 또는 4의 인수만큼 차이가 나더라도 별로 중요하지 않음. 동일한 논증이 적용될 것
이미지 임베딩
- 이미지 타일은 정사각형이므로 정사각형 토큰 그리드로 표현될 가능성이 높음
- 170은 13x13에 매우 가까움
- 추가 토큰은 CLIP와 유사하게 전체 이미지의 gestalt(게슈탈트) 임프레션을 인코딩하는 단일 임베딩 벡터일 수 있음
- 그렇다면 512x512x3에서 13x13x12228로 어떻게 갈 수 있을까?
전략 1: 원시 픽셀
- 이미지를 벡터 공간에 넣는 매우 간단한 방법:
- 512x512 이미지를 8x8 "미니 타일" 그리드로 나눔
- 각 미니 타일은 64x64x3이며, 12,228 차원의 벡터로 펼침
- 각 미니 타일은 단일 임베딩 벡터
- 전체 이미지 타일은 64개의 연속 임베딩 벡터로 표현됨
- 이 접근 방식에는 두 가지 문제가 있음:
- 64 ≠ 170
- 매우 멍청함 (raw RGB 값을 사용하여 임베딩하고 transformer가 해결하기를 바라는 것은 이치에 맞지 않음)
전략 2: CNN
- 다행히도 이러한 특성을 가진 모델이 이미 존재하며, 10년 이상 이미지 데이터를 성공적으로 처리해 온 실적이 있음: 합성곱 신경망(Convolutional Neural Network)
- CNN은 translation 및 scale invariance와 같은 특성을 가짐
- AlexNet과 YOLO는 대표적인 CNN 아키텍처의 예시임
- CNN은 raw pixel을 semantic vector로 압축하는 깔때기와 같음
- YOLO는 이미지를 단일 평면 벡터로 줄이지 않고 13x13에서 중지함
- YOLOv3의 출력은 13x13 그리드에 배치된 169개의 서로 다른 벡터이며, 각각 1,024 차원
- GPT-4o의 가상 이미지 임베딩 CNN은 이러한 CNN 아키텍처의 형태와 유사할 것으로 예상됨
- 512x512x3에서 13x13x12228로 가기 위해 표준 CNN 레이어를 사용하는 방법을 제시
- AlexNet과 유사한 디자인이 이를 우아하게 달성할 수 있음 (5개의 동일한 반복 블록 사용)
- YOLO와 더 유사한 대안도 있지만 12x12에 도달 (13x13 대신)
- 증명할 수는 없지만, 이러한 추측적 설계는 이미지를 kxk 임베딩 벡터 그리드로 표현할 수 있는 그럴듯한 CNN 아키텍처가 있음을 보여줌
실험적 검증
- GPT-4o는 정말 13x13 그리드의 임베딩 벡터를 볼 수 있을까?
- 테스트하기 위해 Zener 카드에서 영감을 받아 태스크를 고안 : 이미지의 격자에 있는 모든 기호의 색상과 모양을 식별하는 것
- 간단한 프로그램으로 테스트용 격자 이미지를 생성하고, JSON 배열 형식으로 각 셀의 모양과 색상을 설명하도록 GPT-4o에 프롬프트를 줌
- 만약 13x13 가설이 맞다면 GPT-4o는 13x13 크기까지는 잘 수행하다가 그 이후로는 성능이 저하될 것으로 예상됨
- 하지만 실제로는 5x5 격자 이하에서는 완벽한 성능을 보이다가 그 이후부터 급격히 저하됨
- 7x7 격자에서는 76%의 정확도를 보였고, 13x13 격자에서는 우연 수준의 성능을 보임
- 이는 169개 토큰이 13x13 격자를 나타낸다는 가설이 잘못되었음을 의미함
- 그러나 5x5 격자 결과는 GPT-4o가 이미지 내에서 25개의 구별되는 객체와 그 절대 위치를 추적할 수 있음을 시사함
- 기본 개념은 맞지만 차원을 잘못 파악한 것일 수 있으며, CNN에 계층을 더 추가하여 13x13 대신 5x5로 줄일 수 있을 것임
- 5x5 격자 이하만 사용한다고 가정할 때 170개 토큰에 도달하기 위해 출력을 어떻게 구조화할 수 있을지 고민해 봐야 함
피라미드 전략
- 85와 170에 가까운 수를 얻는 한 가지 방법은 이미지를 점점 더 세분화된 수준의 일련의 피라미드처럼 인코딩한다고 가정하는 것임
- 전체 이미지의 게슈탈트 임프레션을 캡처하기 위해 하나의 임베딩 벡터로 시작하고, 왼쪽/중간/오른쪽과 위/중간/아래를 캡처하기 위해
3x3을 추가한 다음,5x5,7x7등을 추가함
- 전체 이미지의 게슈탈트 임프레션을 캡처하기 위해 하나의 임베딩 벡터로 시작하고, 왼쪽/중간/오른쪽과 위/중간/아래를 캡처하기 위해
- 이 전략은
7x7에서 멈출 경우 '마스터 썸네일'에 대해 85 토큰에 매우 근접하게 됨- 12+32+52+72=1+9+25+49=84
- 최종
9x9그리드를 추가하면 170에 매우 근접함- 12+32+52+72+92=1+9+25+49+81=165
512x512타일에 대해 임시2x2그리드를 사용하고 각각에 대해 하나의 특수<|image start|>토큰을 가정하면 완벽하게 일치시킬 수 있음- 1+12+32+52+72=1+1+9+25+49=85
- 1+12+22+32+52+72+92=1+1+4+9+25+49+81=170
- 이 체계는 행의 시작과 끝에 대한 어떤 구분 기호도 없지만, 텍스트 토큰의 위치 정보를 인코딩하는 데 RoPE가 사용되는 것과 유사한 방식으로 2D에서 위치 인코딩으로 처리할 수 있을 것임
- 위의 내용은 홀수 그리드 크기만 취하고
5x5를 지나치므로 Zener 그리드 성능이5x5이후에 떨어지기 시작한다는 증거와 완전히 일치하지는 않음 - 대안으로
5x5까지 모든 그리드(짝수와 홀수)를 취해볼 수 있음- 이 접근법은 55개의 토큰을 제공함: 12+22+32+42+52=55
- 각 미니 타일당 3개의 토큰과 각 타일 사이에 구분 기호 토큰 1개를 가정하면 170에 도달할 수 있음
- 3×(12+22+32+42+52)+5=170
- 수치적 근거에서 완전히 만족스럽지는 않지만 경험적 결과와는 잘 맞음
- 피라미드 전략은 직관적으로 매우 매력적이며, 서로 다른 확대/축소 수준에서 공간 정보를 인코딩하는 거의 "명백한" 방법처럼 느껴짐
- 이는
5x5그리드 이하에서는 잘 수행하고6x6이상에서는 매우 저조한 이유를 설명할 수 있음
- 이는
- 모든 가설이 모든 것을 설명하는 데 매혹적으로 가까워 보이지만 숫자가 결코 깔끔하게 맞아떨어지지 않는 것 같아 괴롭긴 함
- 그럼에도 불구하고 이러한 피라미드 전략이 내가 생각해낼 수 있는 최선의 방법임
광학 문자 인식(OCR)
- 위의 가설 중 어느 것도 GPT-4o가 OCR을 수행하는 방법을 설명하지 않음
- CLIP는 기본적으로 OCR을 매우 잘 수행할 수 없으며, 적어도 큰 텍스트 블록에 대해서는 그렇지 않음
- (그럼에도 불구하고 GPT-4o가 OCR을 수행할 수 있다는 사실 자체가 상당히 놀라우며, 창발적 능력의 명확한 예시임)
- GPT-4o는 명백히 고품질 OCR을 수행할 수 있음
- 긴 텍스트 블록을 전사하고, 필기체 텍스트나 이동, 회전, 투영 또는 부분적으로 가려진 텍스트를 읽을 수 있음
- 최신 OCR 엔진은 이미지를 정리하고, 문자의 경계 상자와 띠를 찾은 다음, 해당 띠를 따라 한 번에 하나의 문자 또는 단어씩 특수 문자 인식 모델을 실행하기 위해 많은 작업을 수행함
- 단순히 큰 CNN만 사용하는 것이 아님
- 이론적으로 OpenAI가 정말 그만큼 뛰어난 모델을 구축했을 수도 있지만, Zener 그리드 작업에서의 상대적으로 약한 성능과는 일치하지 않음
- 이미지에서 깔끔한
6x6그리드의 36개 기호를 읽을 수 없다면, 수백 개의 텍스트 문자를 완벽하게 읽을 수는 없을 것임
- 이미지에서 깔끔한
- 이 불일치를 설명하기 위한 간단한 이론:
- OpenAI가 Tesseract와 같은 기성품 OCR 도구(또는 독점적이고 최첨단 도구)를 실행하고 식별된 텍스트를 이미지 데이터와 함께 트랜스포머에 공급한다고 생각함
- 이는 초기 버전이 이미지에 숨겨진 텍스트에 쉽게 혼동된 이유를 설명할 수 있음 (GPT-4o 관점에서 그 텍스트는 프롬프트의 일부였기 때문)
- 이는 현재 수정되었으며, GPT-4o는 이미지 내부에 숨겨진 악의적인 프롬프트를 무시하는 데 능숙함
- 그러나 이는 이미지에서 발견된 텍스트에 대한 토큰 당 요금이 없는 이유를 설명하지 않음
- 흥미롭게도 텍스트를 이미지로 보내는 것이 실제로 더 효율적임
- 작지만 읽을 수 있는 글꼴로 된
512x512이미지에는 400-500개의 텍스트 토큰이 쉽게 들어갈 수 있지만, '마스터 썸네일'에 대한 85개를 더한 170개의 입력 토큰에 대해서만 요금이 부과되어 총 255개 토큰임 (이미지의 단어 수보다 훨씬 적음)
- 작지만 읽을 수 있는 글꼴로 된
- 이 이론은 이미지 처리 시 추가 지연이 발생하는 이유를 설명함
- CNN은 본질적으로 즉각적이지만 제3자 OCR은 추가 시간이 소요될 것임
- 그런데 (이것이 무언가를 증명한다고 말하는 것은 아니지만) OpenAI 코드 인터프리터에서 사용하는 Python 환경에는 PyTesseract가 설치되어 있음
- 업로드한 이미지에 대해 PyTesseract를 실행하여 두 번째 의견을 얻도록 요청할 수 있음
결론
- 본질적으로 하나의 단단한 사실, 즉 OpenAI가 마법의 숫자 170을 사용했다는 것에서 많은 추측을 했음
- 그러나 YOLO와 같은 다른 CNN 아키텍처와 매우 일치하는 완전히 그럴듯한 접근 방식, 즉 이미지 타일에서 임베딩 벡터로 매핑하는 방법이 있는 것 같음
- 따라서 170 토큰이 단순히 이미지 처리에 필요한 대략적인 계산량에 대해 청구하기 위해 사용되는 근사치라고 생각하지 않음
- 또한 일부 다른 멀티모달 모델이 하는 것처럼 이미지와 텍스트 데이터를 결합하기 위해 레이어를 연결한다고 생각하지 않음
- GPT-4o는 CLIP와 YOLO의 혼합인 CNN 아키텍처를 사용하여 이미지를 직접 트랜스포머의 의미 벡터 공간에 임베딩함으로써
512x512이미지를 문자 그대로 170개의 임베딩 벡터로 표현한다고 생각함 - 이 기사를 시작할 때, 170 토큰이
13x13그리드와 하나의 추가 "게슈탈트 인상" 토큰을 위한 것이라는 사실을 완전히 해독했다고 확신했음- 그러나 Zener 작업의 성능이
5x5이후 저하되기 시작하면서 이는 물거품이 되었음. 내부적으로 무엇을 하든13x13보다 훨씬 작은 것 같음
- 그러나 Zener 작업의 성능이
- 그럼에도 불구하고 YOLO에 대한 유추는 설득력이 있으며,
5x5Zener 작업에 대한 성능은 일종의 그리드를 수행하고 있음을 거의 확인해줌 - 이 이론은 다른 영역에서도 많은 예측력을 가지고 있음
- GPT-4o가 여러 이미지를 처리하고 두 이미지를 비교하는 것과 같은 작업을 수행할 수 있는 방법을 설명함
- 동일한 이미지에서 여러 객체를 볼 수 있지만, 복잡한 장면에 너무 많은 객체가 있을 때 압도되는 이유를 설명함
- GPT-4o가 장면 내 개별 객체의 절대 및 상대 위치에 대해 매우 모호해 보이는 이유와 이미지의 객체를 정확하게 계산할 수 없는 이유를 설명함 (객체가 인접한 두 개의 그리드 셀에 걸쳐 있을 때 동일한 클래스가 둘 다에서 활성화되므로 하나의 객체인지 두 개의 객체인지 확신할 수 없음)
- 아이러니하게도, 이 이론이 깔끔하게 설명할 수 없는 유일한 것은 처음에 이 기사를 쓰게 된 동기가 된 질문임: 왜 하필 170 토큰인가?
- 피라미드 이론(
1x1 + 2x2 + 3x3 + 4x4 + 5x5)이 내가 생각해낼 수 있는 최선이었지만, 특별히 깔끔하지는 않음
- 피라미드 이론(
- 조금 더 잘 맞는 이론(또는 NDA에 저촉되지 않는다고 가정할 때 실제 지식)을 가진 사람의 의견을 듣고 싶음
후기: 알파 채널 속임수
-
이 프로젝트를 진행하면서 GPT-4o가 알파 채널을 무시하여 다소 직관에 어긋나는 행동을 한다는 것을 알게 됨
-
"무시한다"는 말은 이미지 편집기가 PNG를 JPG로 변환할 때 기본 배경에 합성하여 투명도를 제거하는 방식이 아님
- GPT-4o는 문자 그대로 RGB 채널만 가져오고 알파 채널은 무시함
-
이를 신중하게 준비된 4개의 이미지로 설명할 수 있음
- 편의상 HTML과 CSS를 사용하여 체크무늬 패턴 위에 이미지를 표시했으며, 이미지 자체는 평평하고 투명한 배경을 가짐
- 그러나 절반은 투명한 검은색 배경을 가지고, 나머지 절반은 투명한 흰색 배경을 가짐
-
"투명한 검은색" 또는 "투명한 흰색"이란?
- RGBA 색상을 4바이트로 표현할 때, 알파가 100%여도 RGB 바이트는 여전히 존재함
- 따라서
(0, 0, 0, 255)와(255, 255, 255, 255)는 어떤 의미에서 다른 색상이지만, 둘 다 100% 투명하기 때문에 올바른 렌더러가 다르게 표시할 상황은 없음
-
GPT-4o에게 이 4개 이미지에서 무엇을 "보는지" 물어보면:
- 투명한 검은색 배경에 검은색 텍스트: GPT-4o는 ""로 읽음
- 투명한 흰색 배경에 검은색 텍스트: GPT-4o는 "ENORMOUS"로 읽음
- 투명한 검은색 배경에 흰색 텍스트: GPT-4o는 "SCINTILLA"로 읽음
- 투명한 흰색 배경에 흰색 텍스트: GPT-4o는 ""로 읽음
-
여기서 무슨 일이 일어나고 있는 것일까?
- GPT-4o는 텍스트 색상이 투명 배경의 "색상"과 다를 때만 텍스트를 읽을 수 있다는 패턴이 나타남
- 이는 GPT-4o가 알파 채널을 무시하고 RGB 채널만 본다는 것을 알려줌. GPT-4o에게 투명한 검은색은 검은색이고, 투명한 흰색은 흰색임
-
RGB 채널 3개를 보존하면서 알파 채널을 100%로 설정하여 이미지를 조작하면 더 명확하게 볼 수 있음
-
Pillow 함수를 사용하여 이를 수행함
-
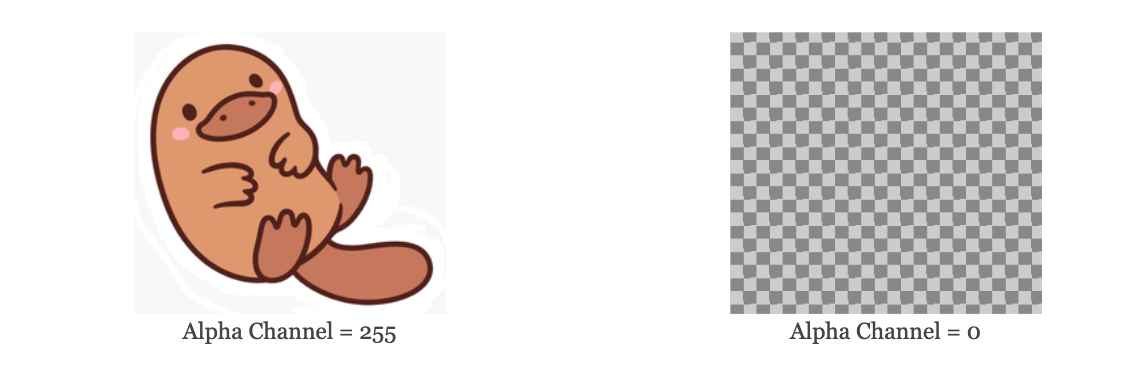
이를 사용하여 아래 두 이미지를 만들었으며, RGB 데이터는 동일하고 알파 채널만 다름
- 알파 채널 = 255: GPT-4o는 숨겨진 오리너구리를 쉽게 볼 수 있음
- 알파 채널 = 0: GPT-4o는 완전히 투명한 이미지로 보임
-
-
hidden_platypus.png이미지를 다운로드하여 ChatGPT에 직접 삽입해 볼 수 있으며, 정확하게 설명할 것임- 이미지 크기가 39.3KB로
platypus.png와 동일한 것을 알 수 있는데, 완벽하게 비어 있고 투명한 이미지라면 PNG 압축으로 인해 훨씬 작아졌어야 함 - 또는 위 함수를 사용하여 알파 채널을 다시 255로 설정하여 원래 이미지를 복구할 수 있음
- 이미지 크기가 39.3KB로
-
이것이 버그인지는 확실하지 않지만 확실히 놀라운 동작이며, 악의적인 사용자가 인간을 지나쳐 GPT-4o로 직접 정보를 밀반입하는 데 사용할 수 있는 것처럼 느껴짐
-
그러나 GPT-4o는 이미지에 숨겨진 악의적인 프롬프트를 탐지하고 무시하는 데 GPT-4v보다 훨씬 뛰어남
image_tagger유틸리티로 생성한 GPT-4o 테스트 이미지 갤러리에서 GPT-4o가 이미지에 숨겨진 악의적인 프롬프트를 성공적으로 탐지하고 무시하는 다른 예시를 찾을 수 있음
-
따라서 버그라 하더라도 악용될 수 있는지는 분명하지 않음
-
그럼에도 불구하고 GPT-4o가 브라우저에서 사람이 보는 것과 동일한 것을 "본다면" 덜 놀랄 것임

Hacker News 의견
- 현대적인 오픈 소스 대체품 필요성: 최신 기계 학습 기술을 기반으로 한 Tesseract의 현대적 오픈 소스 대체품이 절실히 필요함. 현재 사용 중인 LLM은 과도하게 강력하고 비용이 많이 듦.
- Llava1.6, IntenVL, CogVLM2의 OCR 능력: 이 모델들은 타일 이미지 임베딩과 LLM만으로 OCR을 수행할 수 있음. Tesseract의 OCR 결과를 입력하면 신뢰성이 향상되지만 필수는 아님.
- Clip 임베딩의 텍스트 인식: Clip 임베딩은 텍스트가 충분히 크면 텍스트를 "읽을" 수 있음. 타일링은 작은 텍스트를 읽을 수 있게 함.
- 호기심과 개방적인 탐구: 이 기술이 어떻게 작동하는지에 대한 호기심과 개방적인 탐구를 사랑함. 기계 학습 모델 해석을 위한 재규격화 그룹 이론과의 연관성도 흥미로움.
- 텍스트를 이미지로 전송하는 효율성: 텍스트를 이미지로 전송하는 것이 더 효율적일 수 있음. 작은 글꼴로 512x512 이미지에 400-500개의 토큰을 쉽게 담을 수 있음.
- OpenAI의 문서화 부족: OpenAI가 명확하고 포괄적인 문서를 제공하지 않는 이유를 이해하지 못함. API를 사용하는 사람들에게는 이 문서 부족이 큰 장애물임.
- GPT-4의 이미지 처리 오류: GPT-4 비전이 PDF의 여러 페이지를 나타내는 단일 이미지를 OCR할 때 내용이 왜곡되는 문제를 경험함. OpenAI의 명확한 문서가 있었다면 이러한 문제를 더 효과적으로 피할 수 있었을 것임.
- 글의 품질: 이 글이 매우 잘 쓰여졌다고 생각함. 주제를 쉽게 설명하면서도 깊이 있게 다룸. 주제를 잘 이해해야 간단하게 설명할 수 있음.
- VQVAE 사용 가능성: VQVAE를 사용하여 토큰 사전을 만들고 이미지를 인코더로 변환하는 가능성이 있음.
- 이미지-토큰 매핑의 비용: 이미지를 토큰 임베딩으로 매핑하는 것이 토큰 ID로 매핑하는 것보다 약 170배 더 많은 계산과 공간을 소비할 가능성이 있음.
- 13x13 타일링 가능성: 13x13 타일링이 겹치는 수용 영역 때문에 13x13 객체 그리드를 인식할 수 없다는 것을 배제할 수 없음. 겹치는 타일링 해상도의 피라미드도 가능함.
- GPT-4 성능 테스트 방법: 7x7 그리드의 색상 모양을 JSON으로 요청하여 GPT-4 성능을 테스트하는 방법이 매우 기발함.
원문
출처 / GeekNews
 알려드립니다
알려드립니다
이 글은 국내외 IT 소식들을 공유하는 GeekNews의 운영자이신 xguru님께 허락을 받아 GeekNews에 게제된 AI 관련된 소식을 공유한 것입니다.
출처의 GeekNews 링크를 방문하시면 이 글과 관련한 추가적인 의견들을 보시거나 공유하실 수 있습니다! ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식을 정리하고 공유하는데 힘이 됩니다~ ![]()