GeekNews 의 xguru 님께 허락을 받고 GN에 올라온 글들 중에 AI 관련된 소식들을 공유하고 있습니다. ![]()
소개
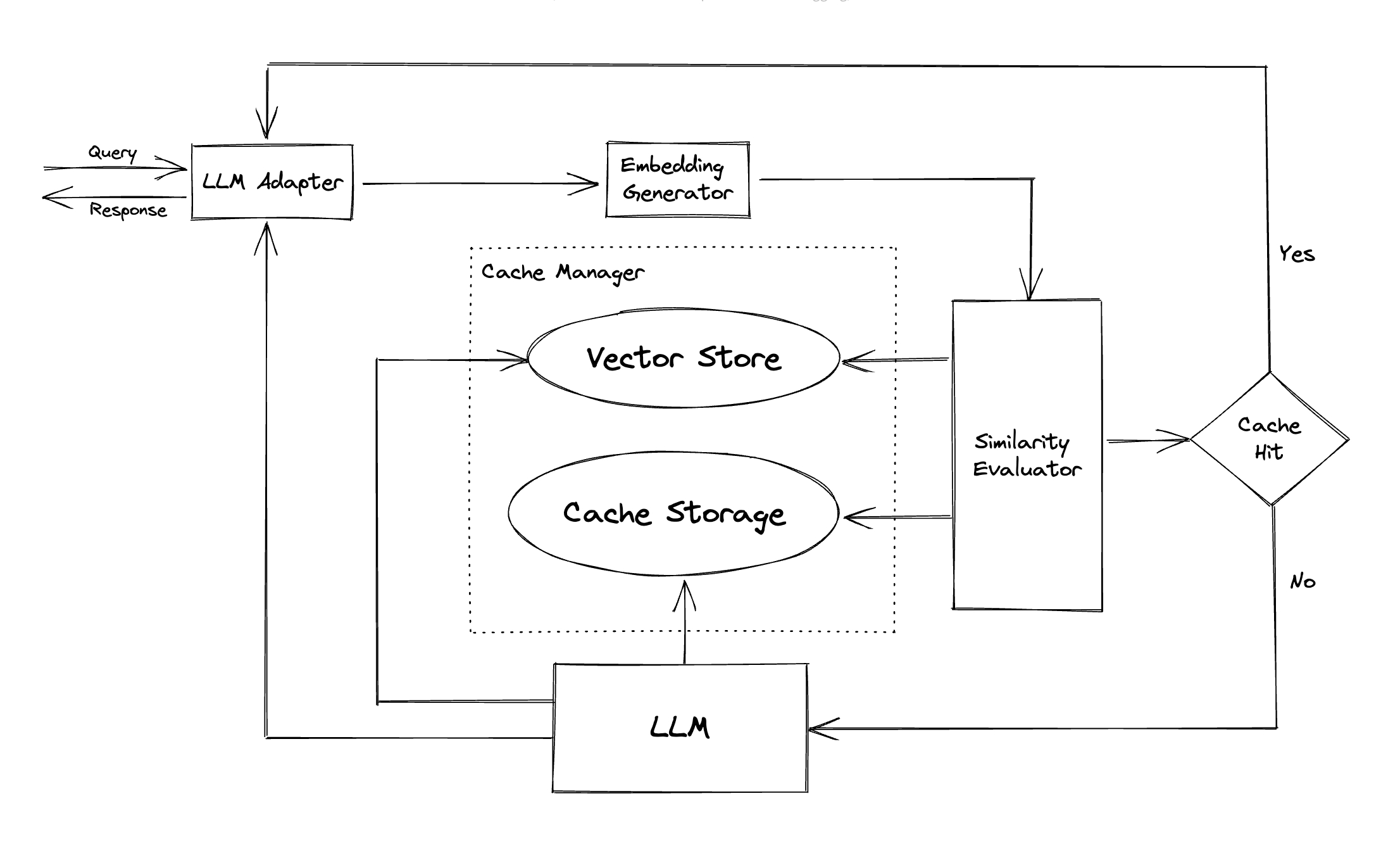
- LLM의 답변을 캐시하여 조직의 LLM 비용을 줄이고 답변 속도를 빠르게
- 시맨틱 캐싱 전략을 통해서 비슷하거나 관련된 질의를 찾아서 캐시 히트율을 높임
- 임베딩 알고리듬을 통해 질의를 임베딩으로 변환하고 벡터 스토어를 통하여 이 임베팅에 대한 연관 검색을 수행
- LLM Adapter : OpenAI ChatGPT 및 LangChain 지원 (Bard/Anthropic/LLaMA 등도 지원 예정)
- MultiModal Adapter : OpenAI Image Create, OpenAI Audio Transribe, HuggingFace Stable Diffusion
- Embedding Generator : OpenAI, ONNX, HuggingFace, Cohere, fastText, SentenceTransformers
- Cache Storage : SQLite, PostgreSQL, MySQL, SQLServer,..
- Vector Store : Mulvus, Zilliz Cloud, FAISS, Hnswlib
- Cache Manager : LRU, FIFO
원문
https://github.com/zilliztech/GPTCache