Llama 3-V - GPT4-V와 동등한 성능을 100배 작은 모델과 500달러로 구현하기
소개
![[GN⁺] Llama 3-V - GPT4-V와 동등한 성능을 100배 작은 모델과 500달러로 구현하기](https://discuss.pytorch.kr/uploads/default/original/2X/f/f689a1178c769f47198613901531c56c84fcdb97.png)
- Llama3-V는 Llama3를 기반으로 한 최초의 멀티모달 모델
- Llama3-V는 500달러 이하의 비용으로 훈련되었음
- 벤치마크에서 Llava보다 10-20% 성능 향상을 보였고, 100배 큰 폐쇄형 모델과 비교해도 대부분의 지표에서 유사한 성능을 보임
모델 아키텍처
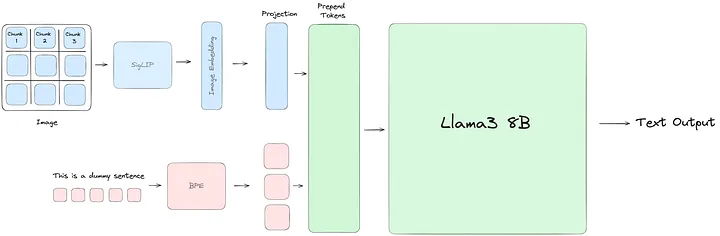
-
SigLIP: 이미지 임베딩 모델로, CLIP과 유사하지만 시그모이드 손실을 사용함.
-
텍스트 임베딩 정렬: SigLIP을 고정하고, 투영 모듈을 사용해 이미지 임베딩을 텍스트 임베딩과 정렬함.
-
이미지 토큰 추가: 이미지 임베딩을 텍스트 토큰 앞에 추가하여 Llama3에 입력함.
추론 최적화
- 캐싱: SigLIP 모델의 이미지 임베딩을 사전에 계산하여 GPU 활용도를 높이고, 훈련/추론 시간을 절약함.
- MPS/MLX 최적화: SigLIP 모델을 MPS 최적화하여 초당 32개의 이미지를 처리함.
훈련 과정
- 임베딩 사전 계산: SigLIP을 사용해 이미지 임베딩을 사전 계산함.
- 투영 레이어 학습: 투영 레이어를 통해 이미지와 텍스트 임베딩을 멀티모달 임베딩 공간으로 정렬함.
- 지도 학습: 사전 훈련 후, 지도 학습을 통해 모델 성능을 향상시킴.
요약
- Llama3 8B에 비전 인코더를 추가함.
- Llava보다 10-20% 성능 향상.
- GPT4v, Gemini Ultra, Claude Opus와 같은 100배 큰 모델과 유사한 성능.
- 500달러 이하의 비용으로 효율적인 훈련 및 지도 학습 파이프라인 제공.
GN⁺의 의견
- 흥미로운 점: Llama3-V는 저비용으로 고성능 멀티모달 모델을 구현한 점이 흥미로움.
- 비판적 시각: 모델 크기와 비용을 줄이면서 성능을 유지하는 것이 얼마나 지속 가능할지 의문임.
- 관련 기술: 비슷한 기능을 제공하는 모델로는 CLIP과 DALL-E가 있음.
- 도입 고려사항: 새로운 기술 도입 시, 모델의 정확도와 비용 효율성을 고려해야 함.
- 기술 선택의 득과 실: 저비용으로 고성능을 얻을 수 있지만, 모델의 확장성과 유지보수 비용도 고려해야 함.
원문 블로그
Llama 3-V 모델 저장소
GitHub 저장소
https://github.com/mustafaaljadery/llama3v
Hugging Face 모델
https://huggingface.co/mustafaaljadery/llama3v/
출처 / GeekNews
 알려드립니다
알려드립니다
이 글은 국내외 IT 소식들을 공유하는 GeekNews의 운영자이신 xguru님께 허락을 받아 GeekNews에 게제된 AI 관련된 소식을 공유한 것입니다.
출처의 GeekNews 링크를 방문하시면 이 글과 관련한 추가적인 의견들을 보시거나 공유하실 수 있습니다! ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식을 정리하고 공유하는데 힘이 됩니다~ ![]()
