GeekNews의 xguru님께 허락을 받고 GN에 올라온 글들 중에 AI 관련된 소식들을 공유하고 있습니다. ![]()
소개
![[GN] LlamaCloud 와 LlamaParse 공개](https://discuss.pytorch.kr/uploads/default/original/2X/b/bcdf4f1e0b91827a87c7337feaeafc93e7cff5cd.jpeg)
-
LlamaCloud: 새로운 세대의 관리형 파싱, 수집, 검색 서비스. LLM과 RAG 애플리케이션에 프로덕션급 Context-Augmentation을 제공하기 위해 설계됨
-
LlamaParse: 표/그림 같은 객체가 포함된 복잡한 문서를 파싱하기 위한 기술. LlamaIndex 와 통합하여 복잡하고 반구조화된 문서에 대한 검색을 구축할 수 있게 함
-
관리형 수집 및 검색 API: 데이터를 쉽게 로드, 처리, 저장하고 어떤 언어에서든 사용할 수 있는 API를 제공. LlamaHub와 LlamaParse 및 통합된 데이터 저장소를 기반으로 동작

RAG는 데이터의 질에 달려 있음
- LLM의 핵심은 구조화되지 않은 데이터 소스에 대한 지식 검색, 종합, 추출, 계획의 자동화임
- 이를 위해 데이터를 로드, 처리, 임베딩하고 벡터 데이터베이스로 로드하는 새로운 데이터 스택 Retrieval-Augmented Generation (RAG)이 등장
- RAG 스택은 기존 ETL 스택과 다르며, LLM 시스템의 정확성에 직접적인 영향을 미침
- 시작은 쉽지만 프로덕션급 RAG를 구축하는 것은 어려움
- 만족할 만한 결과를 생성하지 않음
- 조정할 매개변수의 수가 너무 많음
- PDF는 서식이 지저분해서 특히나 문제임
- 지속적으로 업데이트 되는 데이터의 동기화는 매우 어려움
- LlamaCloud와 LlamaParse는 RAG 애플리케이션을 더 빠르게 프로덕션에 투입하기 위해 데이터 파이프라인으로 구축됨
LlamaParse
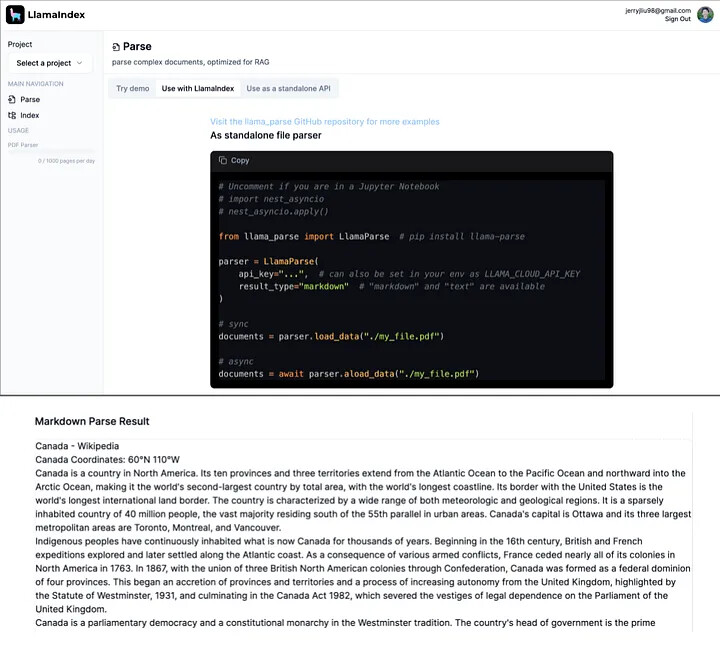
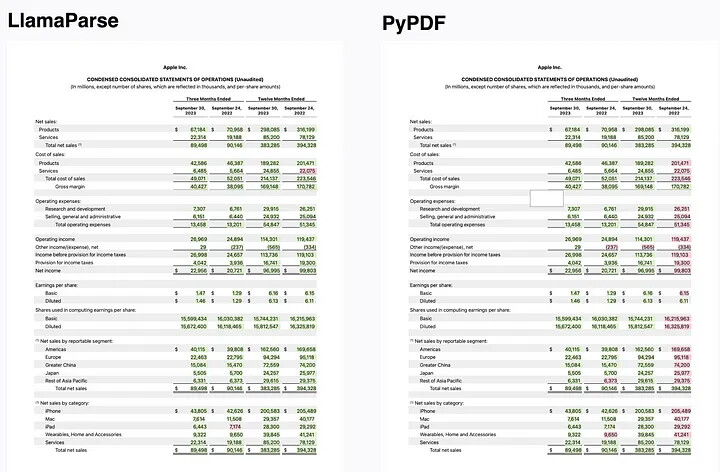
- LlamaParse는 복잡한 PDF 문서에 내장된 표와 차트를 RAG로 해석할 수 있게 하는 최첨단 파서임
- 기존의 접근 방식으로는 불가능했던 복잡한 문서에 대한 질문에 답할 수 있게 함


관리형 수집 및 검색 API
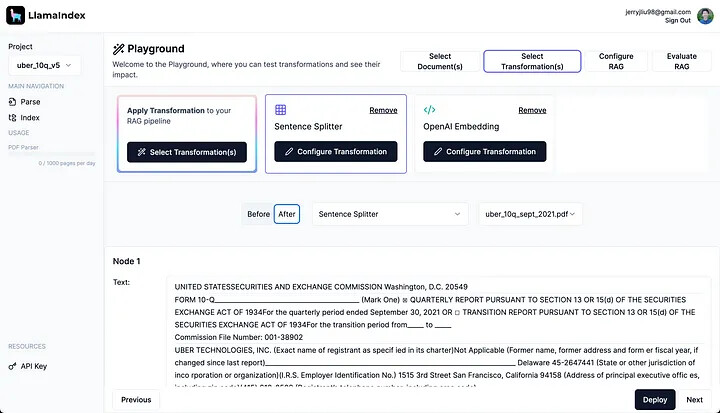
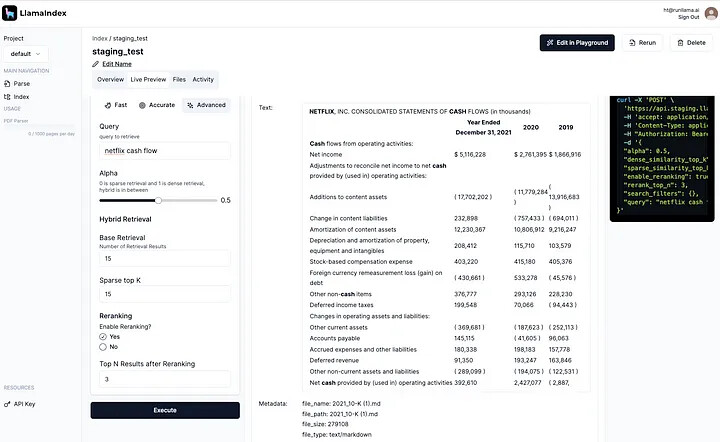
- LlamaCloud의 다른 주요 제품으로, 성능이 좋은 데이터 파이프라인을 쉽게 선언하고 LLM 애플리케이션에 깨끗한 데이터를 제공할 수 있음
- 엔지니어링 시간 절약, 성능 향상, 시스템 복잡성 감소의 이점을 제공
출시 파트너 및 협력자
- LlamaParse는 다양한 파트너와 협력하여 LLM 및 AI 생태계에서 데이터스택, MongoDB, Qdrant, NVIDIA와 같은 스토리지 및 컴퓨팅 파트너십을 구축함.
FAQ
- LlamaCloud는 벡터 데이터베이스와 경쟁하지 않으며, 데이터 파싱 및 수집에 초점을 맞추고 있음. 인기있는 40개 이상의 벡터DB와 통합되어 있음
- 검색 계층은 기존 저장 시스템 위의 오케스트레이션임
다음 단계
- LlamaParse는 오늘부터 공개 프리뷰로 사용 가능하며, LlamaCloud는 제한된 기업 설계 파트너에게 개인 프리뷰로 제공됨
Hacker News 의견
- LlamaParse 개발팀의 일원으로, 이전에 여러 PDF -> 구조화된 텍스트 추출기를 개발한 경험이 있는데, LlamaParse는 다른 추출기들에 비해 개선된 점이 있음. 문자 추출을 위해 OCR과 PDF에서의 문자 추출을 혼합 사용하며, 문서 재구성을 위해 휴리스틱과 머신러닝 모델을 혼합 사용함. 재귀적 검색 전략과 결합하여 복잡한 텍스트에 대한 질문 응답에서 최상의 결과를 얻을 수 있음.
- LlamaParse는 복잡한 표가 있는 PDF를 잘 구조화된 마크다운 형식으로 파싱하는 데 매우 뛰어난 독점 파싱 서비스를 개발함. 오픈소스 프로젝트가 커뮤니티 기여와 주목으로 유명해진 후 프로젝트 리더들이 VC 자금을 받고 독점적인 것을 만드는 것은 문제 아닌가?
- Medium에 게시하는 이유를 이해하지 못함. Medium은 더 이상 읽을 수 없게 되었고, 관객이 접근할 수 있는 블로그 포스트가 있어야 함
- LlamaParse가 unstructured.io와 직접 비교했을 때 어떤지 궁금함
- LlamaParse에 대한 초기 경험이 인상적이지 않음. 이메일로 가입 시 무한 리디렉션 문제, Google로 로그인 후 PDF 파서에 대한 실망감. 이미 많은 옵션이 있는데 왜 이 서비스가 필요한지 혼란스러움.
- LlamaParse는 어려운 문제를 해결하려고 시도하는 것 같음. 많은 기업 고객들이 PDF 파일을 파싱하고 데이터를 정확하게 추출할 필요가 있음. 인터페이스가 다소 혼란스러움. LlamaParse는 테이블의 숫자를 추출할 수 있지만, 출력이 표 형식으로 제공되지 않고 질문-응답을 통해서만 숫자에 접근할 수 있는 것으로 보임.
- AWS Textract가 하는 것과 비슷하지 않음? 테이블과 양식에서 정보를 파싱하고 질의하는 기능이 있음. LI에게는 워크플로우와 RAG를 위한 검색 기록이 사용자에게 더 쉽게 만들어주지만, 왜 바퀴를 다시 발명하는지 의문.
- LLMS를 사용하여 처음부터 가장 적절한 형식으로 데이터를 추출할 수 있는데, 왜 이를 구축하는지 의문. 비용 때문에 단기적으로는 의미가 있을 수 있지만, 장기적으로는 LLMS로 일반적으로 해결할 수 있는 문제.
- RAG와 관련하여 반복적으로 마주쳤던 문제를 LlamaParse가 정확히 해결함. 구조화되지 않은 데이터에서 구조화된 정보를 얻는 것은 어려움.
- 가격이 어떻게 될지에 대한 질문.
LlamaParse 더 알아보기
출시 공지
LlamaParse 시작하기
LlamaParse 저장소 (사용법 및 예시 등)
LlamaParse 사용 예시 코드 (노트북)
https://github.com/run-llama/llama_parse/blob/main/examples/demo_advanced.ipynb