GeekNews의 xguru님께 허락을 받고 GN에 올라온 글들 중에 AI 관련된 소식들을 공유하고 있습니다. ![]()
소개
- a16z에서 정리한 "LLM 앱 스택을 위한 레퍼런스 아키텍쳐"
Emerging LLM App Stack
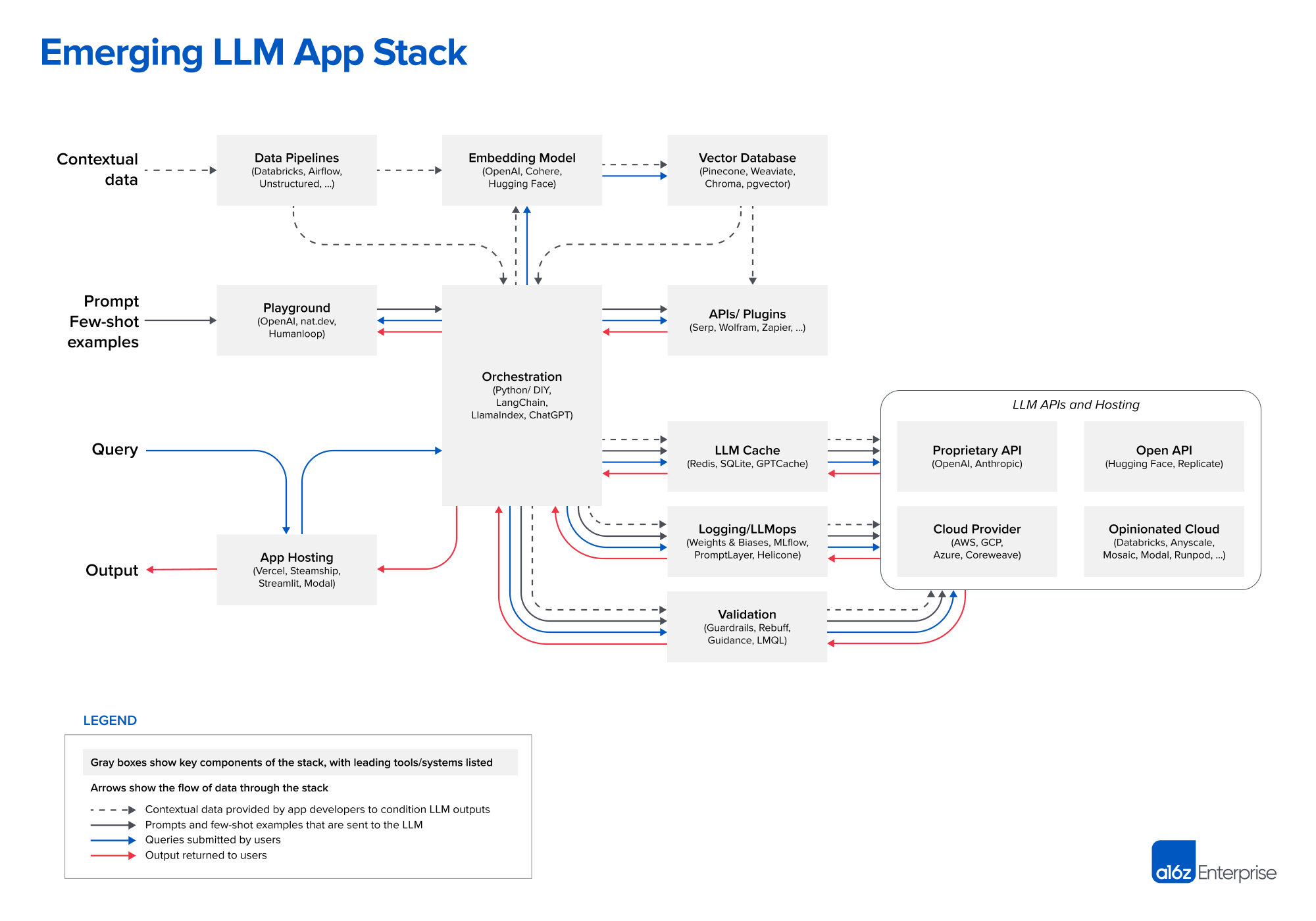
Contextual Data
- Data Pipelines: Databricks, Airflow, Unstructured,..
- Embedding Model: OpenAI, Cohere, Hugging Face
- Vector Database: Pinecone, Weaviate, Chroma, pgvector
Prompt Few-shot Examples
- Playground: OpenAI, nat.dev, Humanloop
- Orchestration: Pytion/DIY, LangChain, LlamaIndex, ChatGPT
- APIs/Plugins: Serp, Wolfram, Zapier,...
Query & Output
- App Hosting: Vercel, Steamship, Streamlit, Modal
- LLM Cache: Redis, SQLite, GPTCache
- Logging/LLMops: Weights & Biases, MLflow, PromptLayer, Helicone
- Validation: Guardrails, Rebuff, Guidance, LMQL
LLM APIs and Hosting
- Proprietary API: OpenAI, Anthropic
- Open API: Hugging Face, Replicate
- Cloud Provider: AWS, GCP, Azure, Coreweave
- Opinionated Cloud: Databricks, Anyscale, Mosaic, Modal, Runpod,...
Design Pattern: In-context Learning
- In-Context Learning: LLM을 파인튜닝 없이 그대로 사용하면서, 똑똑한 프롬프팅 및 일부 "Contextual" 데이터에 기반한 조건을 이용하는 것
- 예) 법률 문서들에 대해서 답변하는 챗봇을 만들때, 나이브하게 만들면 그냥 모든 문서를 ChatGPT에 넣고 질문하면 되겠지만, 작은 데이터셋에나 가능함. ChatGPT 가장 큰 모델도 약 50페이지 밖에 처리 못함
In-Context Learning에서는 관련 문서만 보내고, 그 중에서 답변을 받는 방식을 취함 - 그래서 다음과 같은 3단계 워크플로우로 구성
- Step 1. 데이터 전처리 / 임베딩
- Step 2. 프롬프트 생성 / 벡터 DB에서 관련 문서 Retrieval
- Step 3. 프롬프트 실행 / 추론
- 많은 작업이 필요해보이지만, LLM 자체를 훈련 및 파인 튜닝하는 것보다는 훨씬 쉬움
Step 1. [Data preprocessing / embedding]
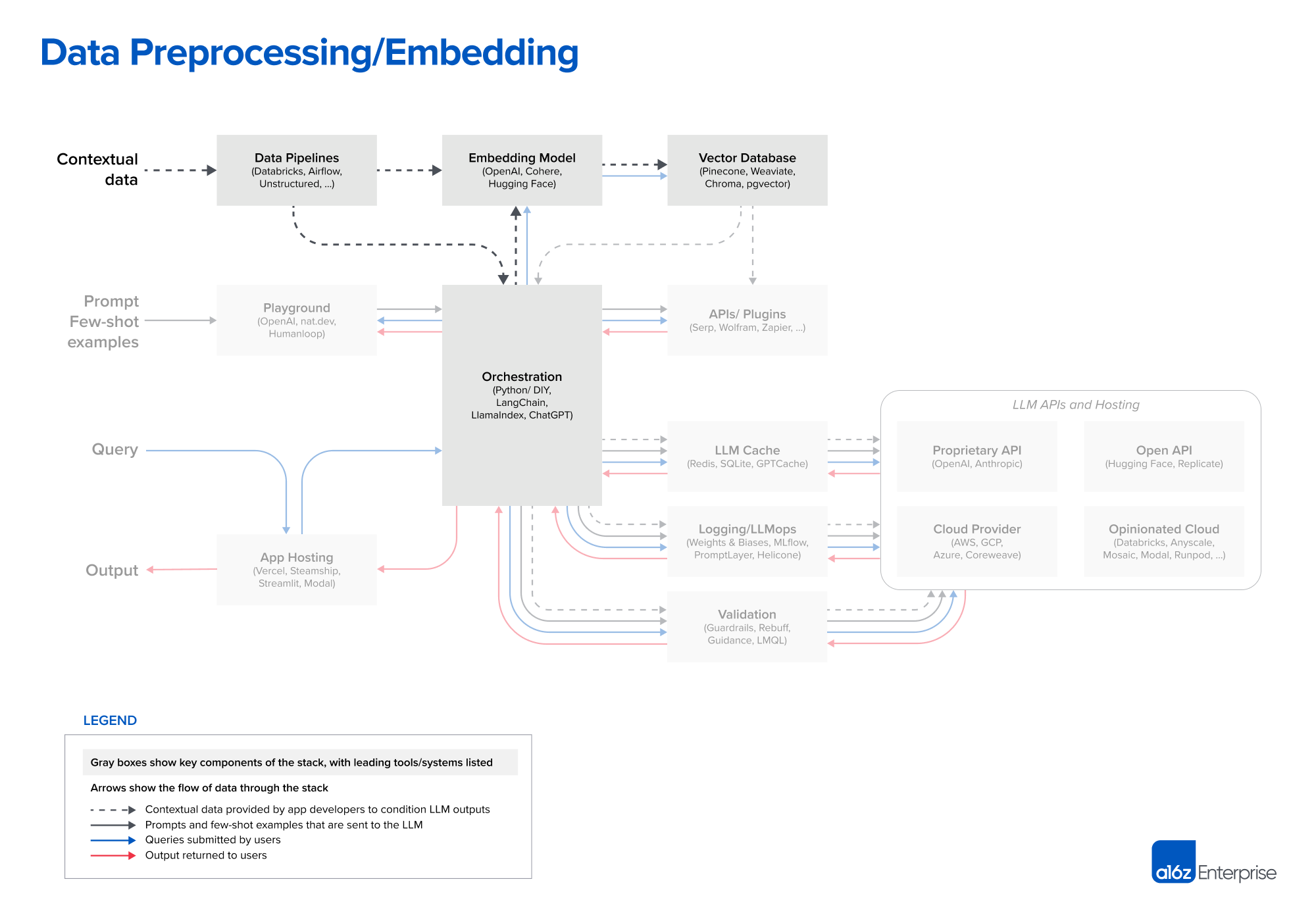
→ Contextual Data가 Data Pipline을 거쳐서 Embdeing Model을 거쳐 Vector Database에 저장
Contextual Data
- 텍스트 문서, PDF, CSV 및 SQL Table들
- 대부분은 데이터 로딩 및 변환은 기존 ETL 도구들(Databricks, Airflow)를 그대로 사용
- 일부는 LangChain, LlamaIndex와 같은 오케스트레이션 프레임워크에 내장된 문서 로더를 이용
- 스택의 이 부분은 아직 상대적으로 덜 개발되었다고 생각하며, LLM앱용으로 특별히 제작된 데이터 복제 솔루션에 기회가 있음
Embeddings
- 대부분의 개발자는 OpenAI API를 사용(text-embedding-ada-002 모델)
- 사용하기 쉽고, 합리적으로 좋은 결과를 내주며, 점점 더 저렴해지고 있음
- 일부 큰 회사들은 Cohere를 탐색중. 특정 시나리오에서 더 나은 성능을 제공
- 오픈소스를 선호하는 개발자들은 Hugging Face의 Sentence Transformers 라이브러리가 표준.
- 또한 유스케이스에 맞는 다양한 종류의 임베딩을 생성하는 것도 가능
- 이것은 니치한 케이스지만 유망한 연구 분야임
Vector Database
- 전처리 파이프라인 부분에서 가장 중요한 부분은 벡터 데이터베이스
- 최대 수십억개의 임베딩(벡터)를 효율적으로 저장, 비교 및 검색하는 역할
- 시장에서 가장 일반적인 선택은 Pinecone
- 완전히 클라우드에서 호스팅되어 시작하기 쉬움
- 대규모 기업이 프로덕션에 필요로 하는 많은 기능을 갖추고 있음(좋은 성능, SSO, 업타임 SLA등)
- 하지만, 사용가능한 벡터 데이터베이스는 엄청 많음. 특히:
- Weaviate, Vespa, Qdrant 같은 오픈소스
- 우수한 단일 노드 성능을 제공하며 특정 앱에 맞게 조정 가능
- 맞춤형 플랫폼 구축을 선호하는 숙련된 AI팀에게 인기 많음
- Chroma, Faiss 같은 로컬 벡터 관리 라이브러리
- 훌륭한 개발자 경험
- 소규모 앱과 개발 실험을 위해 쉽게 운용 가능
- 완전한 대규모 데이터베이스를 대체하는 용도는 아님
- pgvector 같은 OLTP 확장들
- 모든 데이터베이스 형태 요구사항에 Postgres를 끼워넣고 싶은 개발자나 단일 클라우드 공급자에게 대부분의 데이터 인프라를 구입하는 기업에게는 벡터 지원을 위한 좋은 솔루션
- 장기적으로 볼 때 벡터 및 스칼라 워크로드에 타이트하게 결합하는 것이 타당한지는 분명치 않음
- Weaviate, Vespa, Qdrant 같은 오픈소스
- 내다보면 대부분의 오픈 소스 벡터 데이터베이스 화사가 클라우드 제품을 개발중
- 우리의 연구에 따르면 클라우드 상에서 다양한 사용사례에 대해서 훌륭한 성능을 내는 것은 매우 어려움
- 따라서 이런 선택은 단기적으로는 변경되지 않을 수도 있지만, 장기적으로는 변경될 가능성이 높음
- 핵심 질문은 벡터 데이터베이스가 OLTP & OLAP 사례처럼, 하나 또는 두개의 유명한 시스템으로 통합될까 하는 것
- 또 다른 질문은, 대부분의 모델에서 사용가능한 컨텍스트 윈도우가 커짐에 따라서 임베딩 및 벡터 데이터베이스가 어떻게 발전할 것인가
- 컨텍스트 데이터를 프롬프트에 다 올릴 수 있기 때문에 임베딩이 필요 없어질 것이라고 말하고 싶은 유혹이 있겠지만,
- 이에 대한 전문가의 피드백은 임베딩 파이프라인이 점점 더 중요해 질 수 있다고 함
- 큰 컨텍스트 윈도우는 강력한 도구지만, 상당한 계산 비용이 수반 됨. 따라서 그걸 효율적으로 사용하는 것이 우선임
- 이제 다양한 종류의 임베딩 모델이 대중화 되고, 모델 연관성을 가지고 직접 훈련되며, 이를 효율적으로 활성화 및 활용하는 벡터 데이터베이스를 볼 수 있게 될 것
Step 2. [Prompt construction / retrieval]
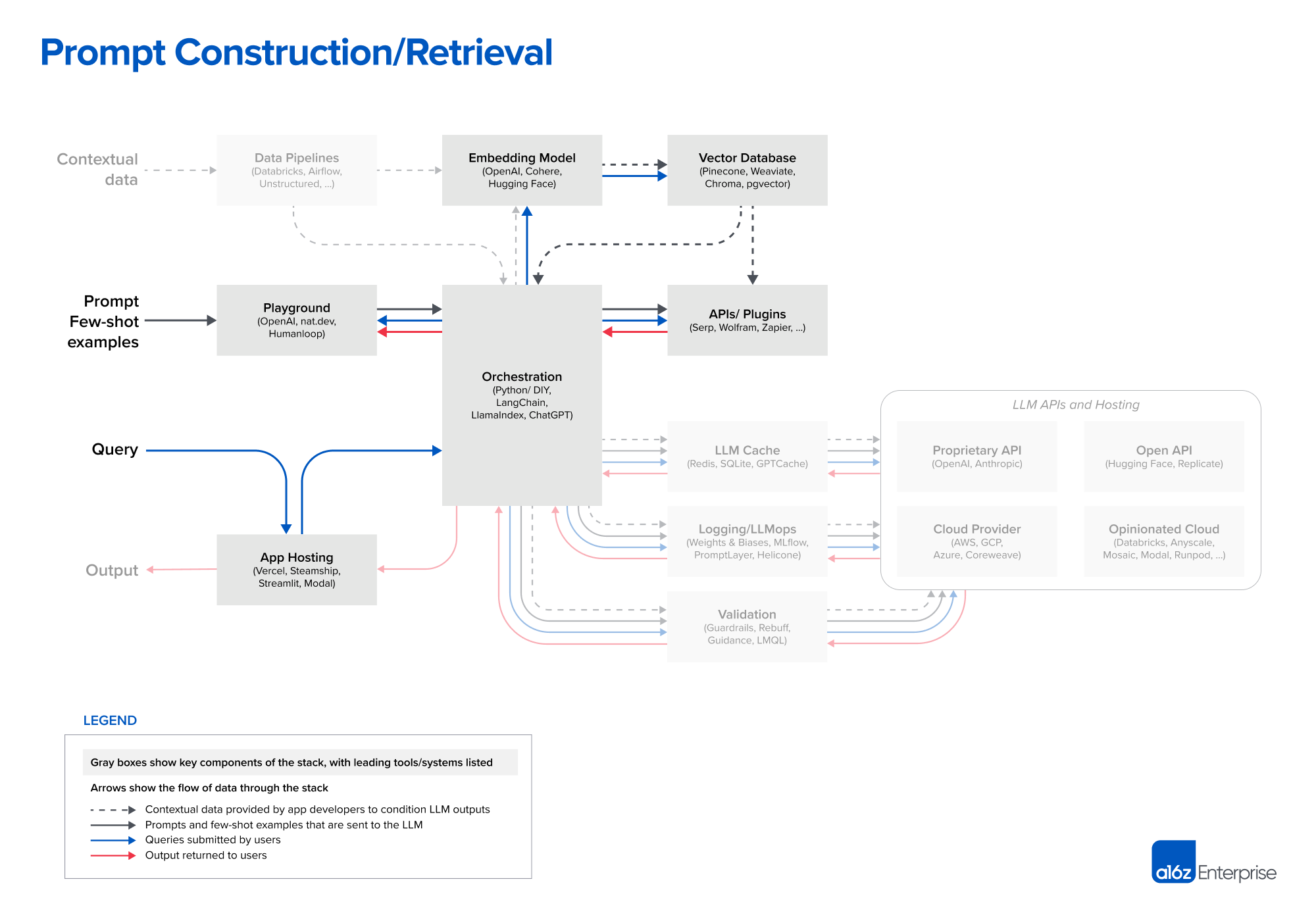
- LLM 프롬프팅과 상황에 맞는 데이터를 통합하는 전략은 점점 더 복잡해 지고 있으며, 제품 차별화의 원천으로서 점점 더 중요해지고 있음
- 대부분의 개발자는 직접 지침(제로 샷 프롬프팅) 또는 몇개의 예제를 포함한(퓨 샷 프롬프팅)으로 구성된 간단한 프롬프트로 새 프로젝트를 시작
- 이런 프롬프트는 좋은 결과를 내기도 하지만, 프로덕션 배포에 필요한 정확도 수준에는 미치지 못함
- 프롬프팅의 다음 단계는 모델 응답의 근거를 일부 진실 소스에 두고, 모델이 훈련되지 않은 외부 콘텍스트를 제공하도록 설계하는 것
- Prompt Engineering Guide는 12개의 고급 프롬프트 전략을 정리하고 있음
- 이때 LangChain/LlamaIndex 같은 오케스트레이션 프레임워크가 빛을 발함
- 이들은 프롬프트 체이닝의 많은 세부 사항을 추상화 함
- 외부 API 연동, 벡터 데이터베이스에서 문맥 데이터 검색, 여러번의 LLM 호출간 메모리 유지 등
- 또한 많은 일반 프로그램들에 대한 템플릿을 제공
- 이들의 출력은 언어모델에 보낼 프롬프트 또는 여러개의 프롬프트들
- 스타트업이나 취미 개발자들 사이에서는 LangChain이 가장 많이 사용 됨
- LangChain은 아직 새로운 프로젝트임(현재 버전 0.0.220)
- 하지만 이미 이를 이용한 앱이 프로덕션 된게 보이기 시작함
- 일부 개발자, 특히 LLM 얼리 어답터는 의존성을 제거하기 위해 프로덕션에서는 순수 Python 으로 전환하는 것을 선호
- 하지만 우린 이런 DIY방식은 웹앱스택에서와 마찬가지로 점차 줄어들 것이라고 생각(대부분 다 이용)
- 눈썰미가 좋은 독자는 오케스트레이션 박스에 ChatGPT 가 있는 것을 봤을 것
- 일반적으로 ChatGPT는 개발자 도구가 아니라 앱이지만, API로 접근이 가능
- 어찌 보면 이런 오케스트레이션 프레임워크와 비슷한 동작을 수행(프롬프트 추상화, 상태 유지, 플러그인을 통한 문맥 데이터 검색등)
- 여기서 얘기하는 도구들과 직접적인 경쟁자는 아니지만, ChatGPT는 대체 솔루션으로 간주 가능. 빠르게 구성하고 사용 가능한 간단한 대안이 될 수 있음
Step 3. [Prompt execution / inference]
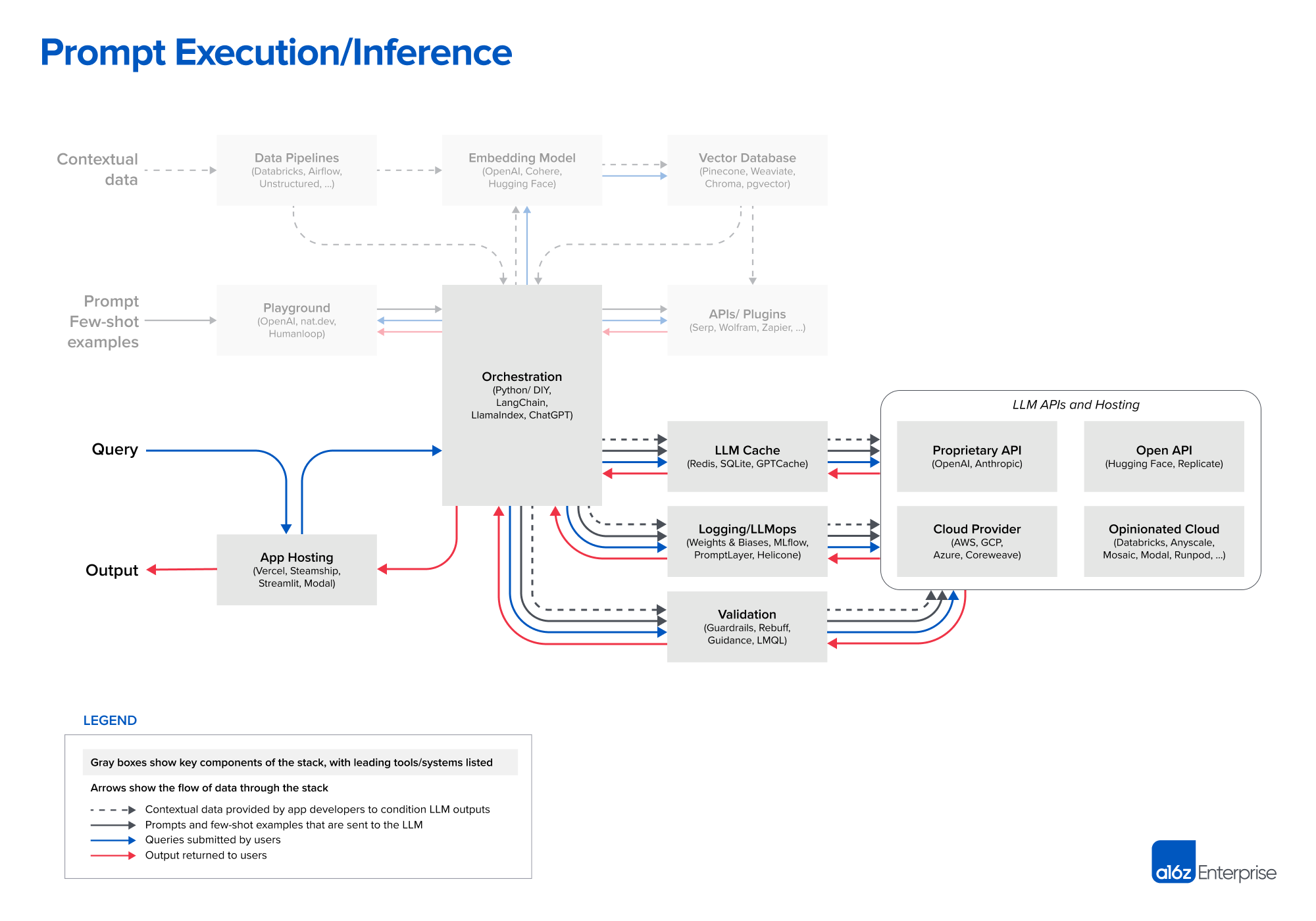
- 현재 OpenAI는 언어 모델 가운데 리더임
- 거의 모든 개발자가 GPT-4, GPT-4-32k 모델로 LLM앱 개발을 시작함
- 사용하기 쉽고 다양한 도메인에 대해 사용가능하며 파인튜닝이나 셀프 호스팅이 필요없음
- 프로덕션에 들어가고 규모가 커지면, 다양한 옵션들이 가능해짐
- gpt-3.5-turbo 로 전환:
- 50배 이상 저렴하고 GPT-4에 훨씬 빠름
- GPT-4 수준의 정확도가 필요하지 않고, 빠른 응답시간이 필요하거나 무료 사용자를 위한 효율적 지원이 필요할때 선택
- 다른 벤더 모델을 실험(특히 Anthropic의 Claude 모델)
- Claude는 빠른 추론과 GPT 3.5 수준의 정확도, 더 많은 커스텀 옵션을 제공하며 최대 100k 컨텍스트 윈도우를 제공(하지만 길어지면 정확도는 떨어짐)
- 일부 요청을 오픈소스 모델로 분기
- 다양한 쿼리 복잡도가 있거나 무료 사용자를 저렴하게 서빙해야 하는 검색/채팅 같은 대규모 B2C 유스케이스에서는 효율적이 될 수 있음
- gpt-3.5-turbo 로 전환:
- 오픈소스 모델은 현재 독점 제품들을 뒤쫓는 상황이지만, 격차가 좁혀지기 시작
- Meta의 LLaMA 모델은 오픈소스 정확도에 대한 새로운 기준을 설정했고, 다양한 변형들이 나오게 함
- LLaMA는 연구용으로만 허가를 했지만, 대체 기본 모델(Together, Mosaic, Falcon, Mistral)을 훈련하기 위해 많은 공급자들이 참여
- Meta는 진정한 오픈소스 LLaMa 2 모델을 출시하기 위해 논의중
- 오픈소스 LLM이 GPT-3.5와 비슷한 정확도 수준에 도달하면 Stable Diffusion Moment와 같은 것을 텍스트 에서 기대함
- 대규모 실험, 공유, 미세 조정된 모델의 프로덕션화 등
- Replicate 같은 호스팅 회사들은 이미 개발자가 이런 모델을 더 쉽게 사용할 수 있도록 도구를 추가중
- 더 작으면서도 파인튜닝된 모델이 최첨단 모델의 정확도에 도달 가능하다는 개발자들의 믿음이 커지고 있음
- 우리가 얘기나눈 대부분의 개발자들은 LLM을 위한 운영도구에 대해서는 깊이 들어가지 않았음
- Caching은 일반적인데, 보통 Redis로 함(응답시간과 비용을 개선하기 때문)
- Weights & Biases, MLFlow, PromptLayer, Helicone 같은 도구도 많이 사용됨
- 신속한 프롬프트 생성, 파이프라인 튜닝, 모델 선택을 위해 LLM 출력을 로그, 추적, 평가 할수 있음
- LLM 출력을 검증(Guardrails)하거나, 프롬프트 인젝션 감지(Rebuff) 같은 도구들도 많이 나오는중
- 이런 운영 도구의 대부분은 자체 Python 클라이언트를 사용하여 LLM 호출을 수행하도록 권장하므로 차후에 어떻게 공존하는지를 지켜보는 것도 흥미로움
- 마지막으로, LLM의 정적인 부분(모델 이외의 모든 것)도 어딘가에 호스팅 되어야 함
- 가장 일반적인 솔루션은 Vercel 이나 주요 클라우드 공급자들
- 그러나 두가지 새로운 카테고리가 출현중
- Steamship은 LLM 앱을 위한 엔드-투-엔드 호스팅을 제공하여, 오케스트레이션(LangChain), 멀티 테넌트 데이터 콘텍스트, 비동기 태스크, 벡터 저장소, 키 관리등의 기능을 제공
- Anyscale 과 Modal 은 개발자가 모델과 파이썬 코드를 동시에 호스팅할 수 있게 해줌
Agent는?
- 이 레퍼런스 아키텍처에서 누락된 가장 중요한 요소는 AI Agent Framerwork
- AutoGPT 는 "GPT-4를 완전히 자율적으로 만들기 위한 오픈소스 실험" 으로 올 봄에 역사상 가장 빠르게 성장한 GitHub Repo였음
- 요즘 모든 AI 프로젝트는 어떤 형태로든 에이전트가 포함되어 있음
- 우리가 대화해본 대부분의 개발자는 에이전트의 잠재력에 매우 흥분하고 있음
- 이 글에서 설명한 인-컨텍스트 러닝 패턴은 콘텐츠 생성 작업을 더 잘 지원하고, 할루시네이션 과 데이터 신선도 문제를 해결하는데 좋음
- 반면에 에이전트는 AI앱에 근본적으로 새로운 기능을 제공
- 복잡한 문제를 해결하고, 외부 세계에 대해 액션을 하거나, 배포후에도 경험에서 배우거나
- 고급 추론/계획, 도구의 사용, 메모리/재귀/셀프-리플렉션 등의 조합을 통해 이를 수행
- 에이전트는 LLM 앱 아키텍처의 중심 부분이 될 가능성이 있음(재귀에 따른 자기 발전을 믿는다면, 전체 스택을 차지할 수도)
- 이미 LangChain 같은 프레임워크들은 에이전트 컨셉트를 통합했음
- 단 한가지 문제는, 에이전트는 아직 제대로 동작하지 않는다는 것
- 현재 대부분의 에이전트 프레임워크는 PoC 단계에 있음 - 놀라운 데모는 가능하지만, 안정적이거나 재현 가능하지 않음
- 그들이 어떻게 발전할지 주시하고 있음
앞을 내다보며
- 사전 훈련된 AI 모델은 인터넷 이후 소프트웨어에서 가장 중요한 아키텍쳐 변화임
- 이를 통해 각 개발자는 대규모 팀이 구축하는데 몇 달 걸리는 Supervised 머신러닝 프로젝트를 능가하는 AI앱을 며칠 만에 구축 가능
- 여기서 소개한 도구와 패턴은 최종 상태가 아니라 LLM 통합을 위한 시작점일 가능성이 높음