GeekNews의 xguru님께 허락을 받고 GN에 올라온 글들 중에 AI 관련된 소식들을 공유하고 있습니다. ![]()
소개
Menlo Ventures에서 작성하여 공개한 글로, 작년 11월에 공개했던 기업용 AI 현황 보고서의 후속 글입니다. 또한, 이 글에 소개된 AI 회사들 중 일부는 Menlo Ventures가 투자한 회사입니다.
최신 AI 스택의 정의
![[GN] 최신 AI 스택 : 엔터프라이즈 AI 아키텍처의 미래를 위한 설계 원칙](https://discuss.pytorch.kr/uploads/default/original/2X/a/a5cd51bd41eceafc554d4d7a7f1dbc6b5c06fd54.jpeg)
-
계층 1 : 컴퓨트 및 기초 모델 - 기초 모델 자체와 모델을 훈련, 미세 조정, 최적화 및 배포하기 위한 인프라를 포함
-
계층 2 : 데이터 - LLM을 기업 데이터 시스템 내의 적절한 컨텍스트에 연결하는 인프라를 포함하며, 데이터 전처리, ETL 및 데이터 파이프라인, 벡터 데이터베이스, 메타데이터 저장소, 컨텍스트 캐시 등의 핵심 구성 요소를 포함
-
계층 3 : 배포 - 개발자가 AI 애플리케이션을 관리하고 조정하는 데 도움이 되는 도구를 포함. 에이전트 프레임워크, 프롬프트 관리, 모델 라우팅 및 조정
-
계층 4 : 관찰 가능성 - LLM의 실행 시간 동작을 모니터링하고 위협으로부터 보호하는 솔루션을 포함
새로운 AI 성숙도 곡선
- 현대 AI 스택을 정의하는 시장 구조와 기술은 빠르게 진화하고 있으며, 주요 구성 요소와 리더들이 이미 등장함
- LLM 이전에는 ML 개발이 선형적이고 '모델 중심'이었으나, LLM은 '제품 중심'으로 전환하여 ML 전문 지식이 없는 팀도 AI를 제품에 통합할 수 있게 함
- AI 스택이 성숙함에 따라 개발 팀은 기업 또는 고객 특정 데이터를 통해 AI 경험을 맞춤화하려고 함
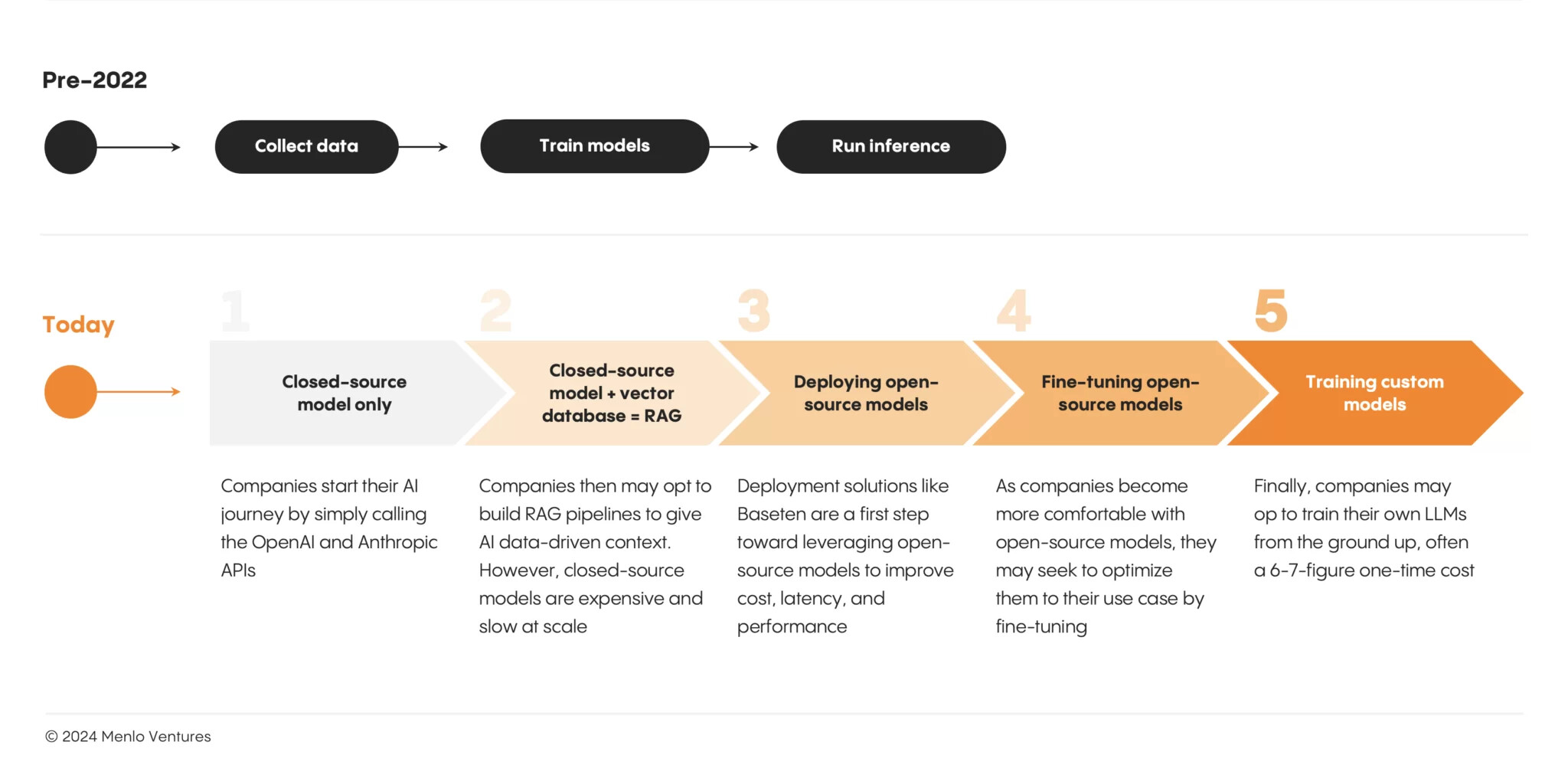
AI 성숙도 곡선 1단계: Closed-source models only 비공개 모델만
-
2023년 초에는 비용과 엔지니어링 노력이 주로 기초 모델 자체에 집중하고 그 위에 간단한 커스터마이제이션(프롬프트 엔지니어링 / few-shot learning 등의 학습)만 있었음
-
OpenAI 및 Anthropic 과 같은 주요 비공개 소스 모델 제공업체가 이 단계에서 초기 견인력을 얻어 현대 AI 스택의 최초 승자로 확고히 자리 잡음
AI 성숙도 곡선 2단계: RAG(Retrieval-Augmented Generation) 검색증강 생성
-
AI 애플리케이션 노력의 중심으로(모델 계층이 아닌) 데이터 계층에 초점을 둠
-
특히 RAG의 대중화에는 벡터 데이터베이스 Pinecone 및 데이터 전처리 엔진 Unstructured 와 같은 더욱 강력한 데이터 계층 인프라가 필요
-
대부분의 기업과 스타트업은 현재 이 단계에 있음
AI 성숙도 곡선 3단계: Hybrid model deployment 하이브리드 모델 배포
AI 성숙도 곡선 4단계 이상: Custom models 맞춤형 모델
-
아직까지 자체 모델을 구축할 정도로 고도화되었거나 자체 모델을 구축할 필요가 있는 기업은 거의 없지만, 향후에는 스택을 더 깊이 활용하고자 하는 대기업의 사용 사례가 늘어날 것
-
메모리 효율적 미세 조정(4비트 양자화, QLoRA, 메모리 페이징/오프로드 포함)을 위한 툴을 제공하는 Predibase, Lamini와 같은 기업이 이를 지원하게 될 것
새로운 AI 인프라 스택을 위한 네 가지 주요 설계 원칙
- AI 혁명은 새로운 인프라 스택에 대한 수요를 촉발할 뿐만 아니라 기업이 애플리케이션 개발, R&D 지출 및 팀 구성을 접근하는 방식을 재구성함
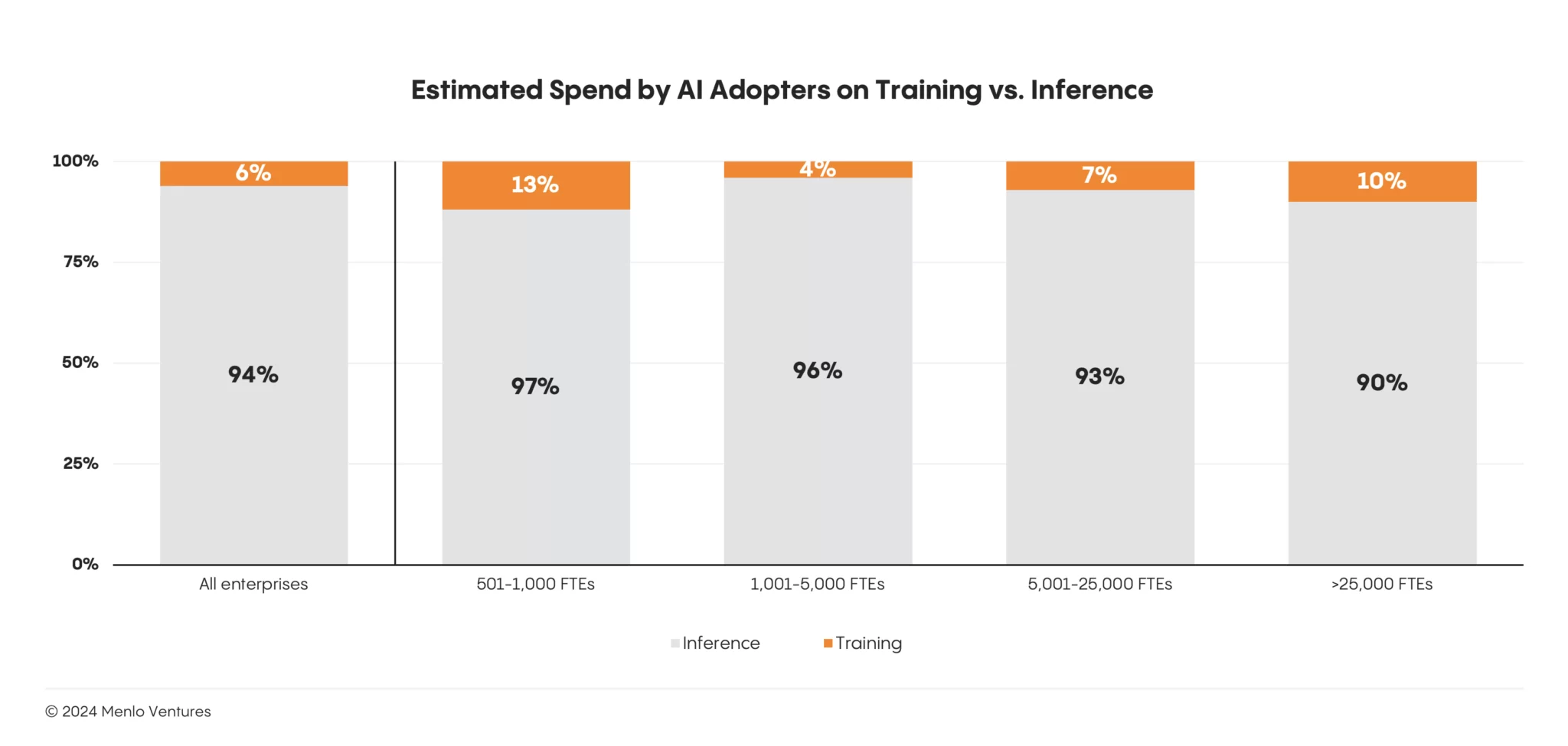
주요 설계 원칙: 1. 지출의 대부분은 추론과 학습 시에 사용됨
-
LLM 혁명 초기에는 모든 회사가 언젠가 자신만의 대규모 언어 모델을 훈련할 수 있을 것으로 보였음
-
2023년 3월에 발표된 BloombergGPT(재무 데이터에 대해 특별히 훈련된 50b LLM) 와 같은 모델은 앞으로 기업 및 도메인별 LLM이 범람하는 사례로 예고되었음
-
하지만 그런 대홍수는 나지 않았음
-
Menlo Ventures의 최근 엔터프라이즈 AI 설문조사에 따르면 전체 AI 지출의 거의 95%가 런타임과 사전 학습에 사용되고 있는 것으로 나타남
-
이 비율은 Anthropic과 같은 대형 기반 모델 제공업체에서만 뒤집혔음. 애플리케이션 레이어에서는 Writer와 같은 정교한 AI 빌더조차도 컴퓨팅의 80% 이상을 트레이닝이 아닌 추론에 사용
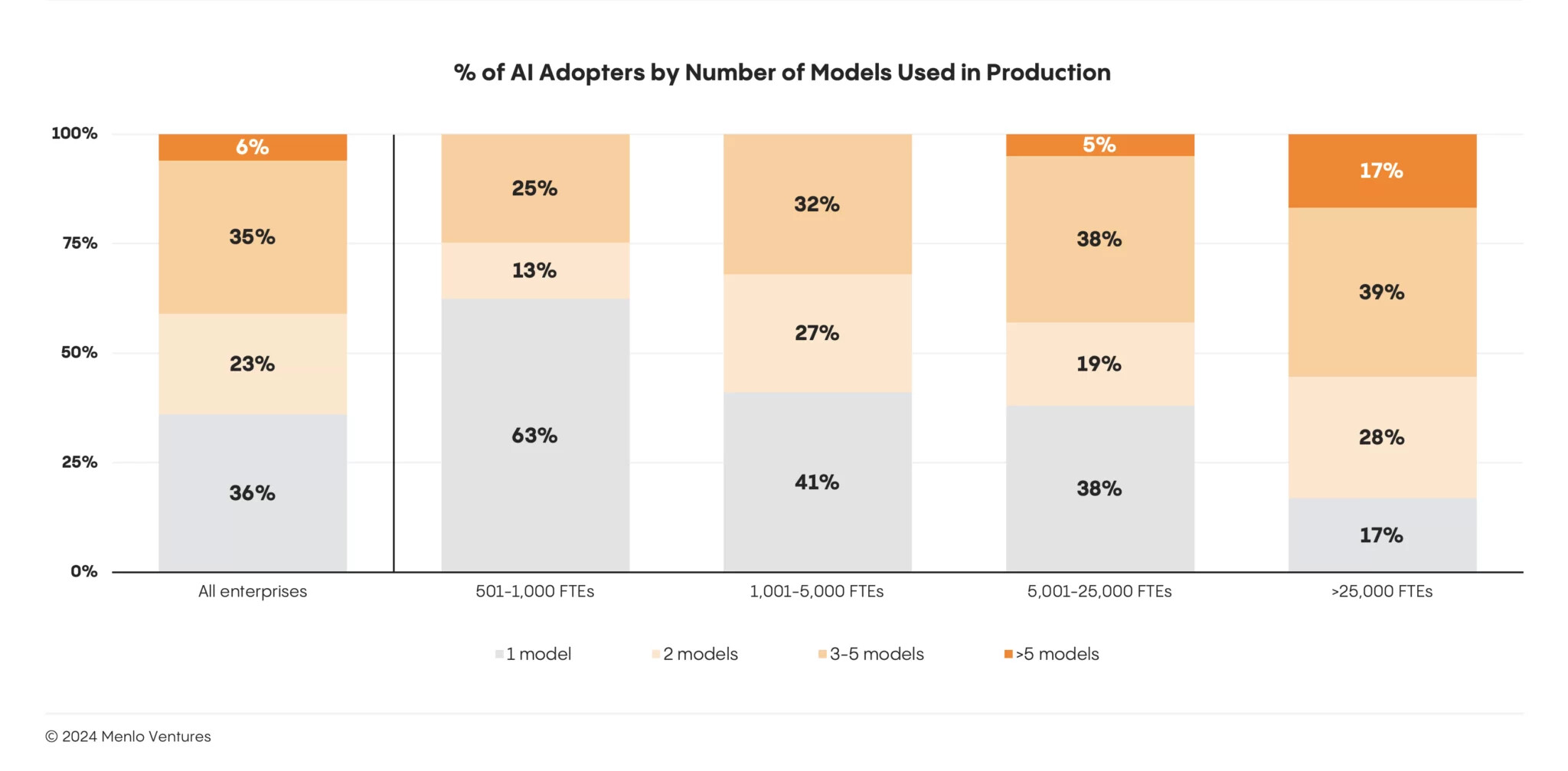
주요 설계 원칙: 2. 우리는 다중 모델(Multi-Model) 세계에서 살고 있음
-
단일 모델이 "모든 모델을 지배"할 수는 없음
-
기업의 60%가 여러 모델을 사용하고 프롬프트를 가장 성능이 좋은 모델로 라우팅함
-
다중 모델 접근 방식은 단일 모델 종속성을 제거하고 더 높은 제어 가능성을 제공하며 비용을 절감
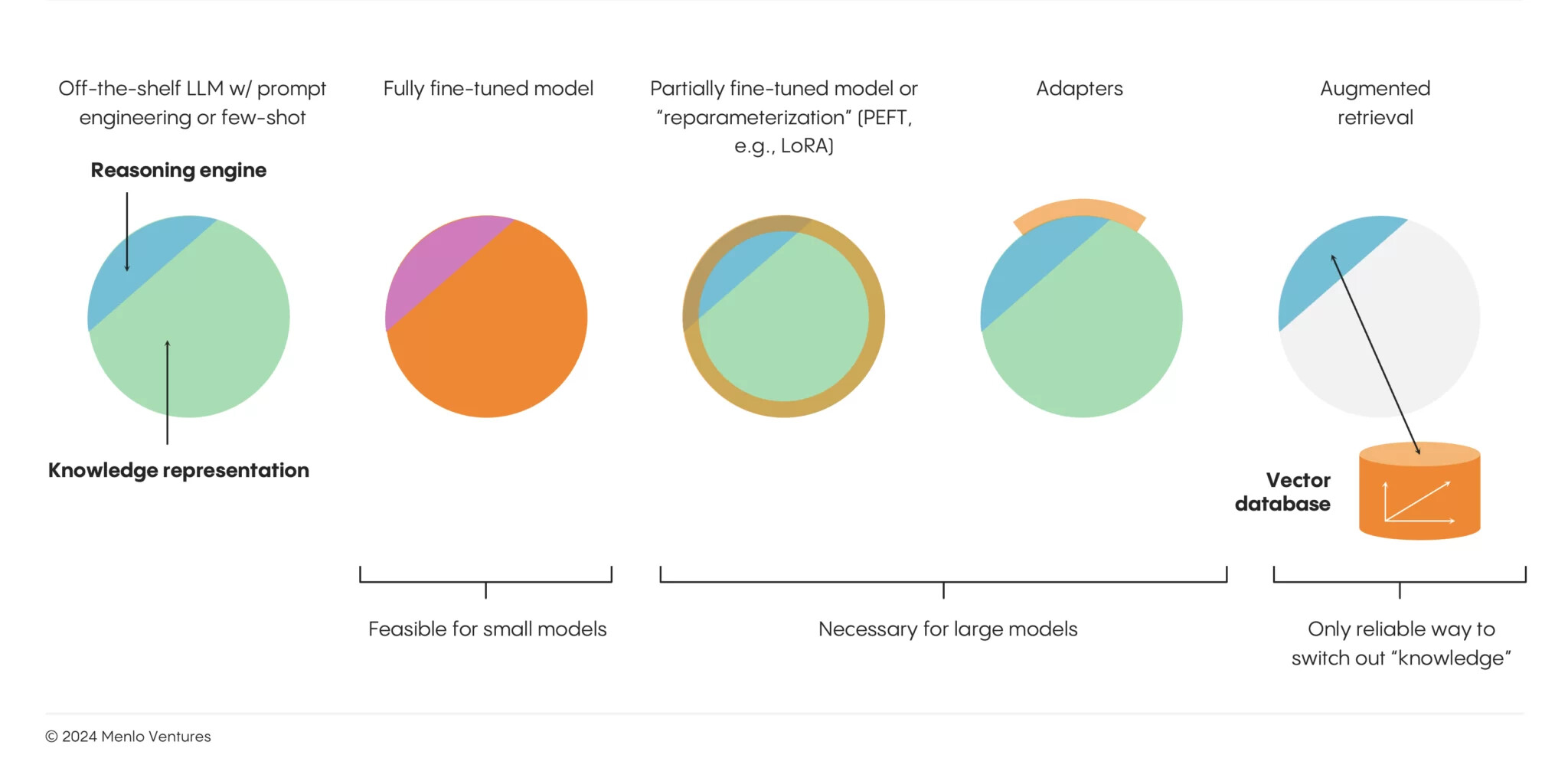
주요 설계 원칙: 3. RAG가 지배적인 아키텍처 접근 방식임
-
LLM은 뛰어난 추론 엔진이지만 도메인 및 기업별 지식이 제한되어 있음
-
유용한 AI 경험을 만들기 위해 팀은 검색 증강 생성(RAG)부터 시작하여 지식 증강 기술을 신속하게 배포중
-
RAG는 Pinecone과 같은 벡터 데이터베이스를 통해 기본 모델에 기업별 "메모리"를 부여
-
이 기술은 현재 생산 중인 미세 조정, 하위 순위 적응 또는 어댑터와 같은 다른 사용자 정의 기술보다 훨씬 앞서며 주로 데이터 계층이 아닌 모델 계층에서 작동
-
앞으로도 이러한 추세는 계속될 것이며 데이터 전처리 엔진(예: Cleanlab ) 및 ETL 파이프(예: Unstructured )를 포함한 데이터 평면의 새로운 부분이 런타임 아키텍처에서 통합될 것으로 예상
주요 설계 원칙: 4. 모든 개발자는 이제 AI 개발자임
-
전 세계적으로 개발자는 3천만 명, ML 엔지니어는 30만 명, ML 연구원은 3만 명에 불과
-
ML의 최전선에서 혁신을 이루고 있는 사람들의 경우, GPT-4 또는 Claude 2 수준 시스템을 구축하는 방법을 아는 연구원은 전 세계에 50명에 불과할 것으로 추정
-
이러한 현실에 직면하여 좋은 소식은 수년간의 기초 연구와 정교한 ML 전문 지식이 필요했던 작업을 이제 강력한 사전 훈련된 LLM을 기반으로 데이터 시스템을 엔지니어링하는 주류 개발자가 며칠 또는 몇 주 안에 완료할 수 있다는 것
-
Salesforce의 Einstein GPT(Sales용 AI CoPilot) 및 Intuit Assist(Generative AI 기반 금융 비서)와 같은 제품은 주로 AI 엔지니어로 구성된 린 팀(최신 AI 스택의 데이터 플레인에서 작업하는 전통적인 풀 스택 엔지니어)에 의해 구축됨
이후로는 어떻게 될까요?
- 현대 AI 스택은 빠르게 진화하고 있으며, 올해 계속해서 진행될 것으로 예상되는 몇 가지 발전이 있음
차세대 AI 어플리케이션들은 더욱 발전된 RAG을 시범 운영중
-
RAG는 오늘날 왕이지만, 이 접근 방식이 문제가 없는 것은 아님
-
많은 구현에서는 여전히 토큰 수 기반 문서 청크, 비효율적인 인덱싱 및 순위 알고리듬을 포함하여 나이브한 임베딩 및 검색 기술을 활용
-
컨텍스트 조각화, 환각, 엔티티 희귀성, 비효율적 검색 같은 문제를 가지고 있음
-
이런 문제를 해결하기 위해 차세대 아키텍처는 더 발전된 RAG을 테스트중 : Chain-Of-Thought 추론, Tree-Of-Thought 추론, Reflexion, 규칙 기반 검색 등
소형 모델이 최신 AI 스택에서 더 큰 비중을 차지
-
AI 애플리케이션 빌더가 최신 AI 스택에 더 깊이 집중함에 따라, 더 세밀하고 작업 특정 모델의 증가가 예상됨
-
더 큰 폐쇄 소스 모델이 다루기 힘들거나 비용이 많이 드는 특정 영역에 대해 미세 조정된 작업별 모델이 확산될 것
-
ML 파이프라인 구축 및 미세 조정을 위한 인프라는 기업이 자체 작업별 모델을 생성함에 따라 이 단계에서 매우 중요해질 것
-
Ollama 및 ggml에서 제공하는 양자화 기술은 팀이 소형 모델이 제공하는 최대 속도 향상을 누릴 수 있도록 도와줌
관찰 가능성(Observability)과 모델 평가(Model Evaluation)를 위한 새로운 도구가 등장하고 있음
-
2023년 대부분의 기간 동안 로깅과 평가는 전혀 이루어지지 않았거나, 수작업으로 이루어졌거나, 대부분의 엔터프라이즈 애플리케이션의 출발점이 되는 학술적 벤치마크를 통해 이루어졌음
-
Criteo의 조사에 따르면 AI를 도입한 기업 중 약 70%가 주요 평가 기법으로 사람을 통해 결과물을 검토하고 있는 것으로 나타남. 그 이유는 리스크가 높기 때문
-
고객은 고품질의 결과물을 기대하며 그럴 자격이 있고, 기업들은 환각으로 인해 고객의 신뢰를 잃을 수 있다는 점을 잘 알고 있음
-
따라서 관찰 가능성과 평가는 새로운 툴을 위한 중요한 기회를 제공
-
이미 Braintrust, Patronus, Log10, AgentOps와 같은 유망한 새로운 접근 방식이 등장하고 있음
아키텍처는 서버리스 방향으로 이동할 것
-
다른 엔터프라이즈 데이터 시스템과 마찬가지로, 최신 AI 스택은 시간이 지남에 따라 서버리스로 이동하고 있음
-
여기서는 "임시 머신" 유형의 서버리스(예: 람다 함수)와 진정한 스케일 투 제로 서버리스(예: Postgres용 Neon 아키텍처)를 구분함
-
스케일 투 제로 서버리스의 경우 인프라를 추상화하면 개발자는 애플리케이션 실행의 운영 복잡성을 덜고, 더 빠른 반복이 가능하며, 기업은 컴퓨팅 대비 가용성에 대해서만 비용을 지불하여 상당한 리소스 최적화를 누릴 수 있음
-
서버리스 패러다임은 최신 AI 스택의 모든 부분에 적용될 것
-
Pinecone은 벡터 컴퓨팅을 위한 최신 아키텍처로 이러한 접근 방식을 채택
-
Neon은 Postgres, Momento는 Caching, Baseten과 Modal은 추론을 위해 동일한 작업을 수행