GeekNews의 xguru 님께 허락을 받고 GN에 올라온 글들 중에 AI 관련된 소식들을 공유하고 있습니다. ![]()
소개
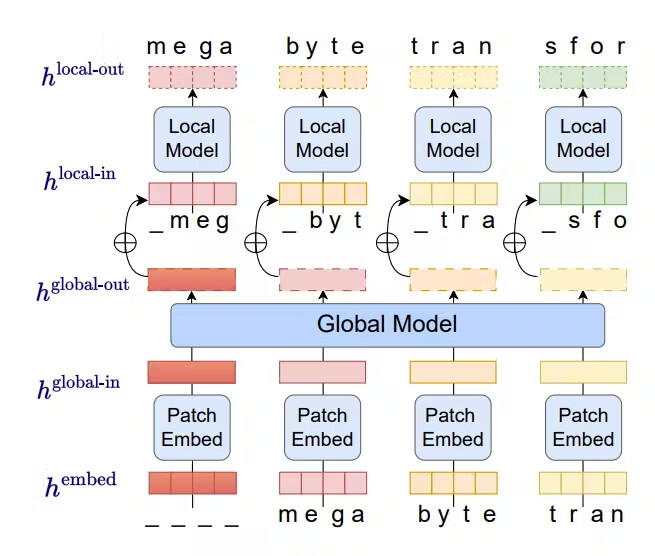
- GTP-4 같은 모델이 사용하는 트랜스포머 아키텍처를 뛰어넘어 더 효율적/병렬적으로 처리하게 스케일 가능
- 트랜스포머는 짧은 시퀀스에는 적합하지만, 고해상 이미지, 팟캐스트, 코드, 책과 같은 1백만개 이상의 긴 토큰으로의 확장은 어려움
- Megabyte 는 멀티-스케일 디코더 아키텍처로 1백만 이상의 시퀀스를 모델링 가능
- 입력과 출력의 시퀀스를 개별 토큰이 아닌 "Patch"로 분할
- 로컬 AI 모델이 각 패치에 대해서 결과를 생성하고, 글로벌 모델이 이 패치들을 관리 및 조율
- 테스트 결과 15억(1.5B)개의 파라미터 모델을 이용하는 Megabyte 모델이 3억 5천만개(350M)개의 파라미터로 동작하는 트랜스포머 모델보다 40% 더 빠르게 시퀀스를 구성
- 테스트 결과 GPT-4 의 32000개 토큰, Claude의 10만개 토큰을 훨씬 뛰어넘어 1.2M개의 토큰 까지 가능
원문
Artisana의 Megabyte 소개글
Encord의 Megabyte 소개글
Megabyte 논문
https://arxiv.org/pdf/2305.07185.pdf