GeekNews의 xguru님께 허락을 받고 GN에 올라온 글들 중에 AI 관련된 소식들을 공유하고 있습니다. ![]()
소개
- 세계에 대한 더 실제적인 이해를 바탕으로 고급 기계 지능(AMI, Advanced Machine Intelligence)을 발전시키는 중요한 단계인 Video Joint Embedding Predictive Architecture (V-JEPA) 모델을 공개
- 이 물리적 세계 모델의 초기 예는 객체 간의 상세한 상호작용을 감지하고 이해하는 데 뛰어남
- 책임감 있는 오픈 사이언스 정신으로, 연구자들이 더 탐구할 수 있도록 이 모델을 Creative Commons NonCommercial 라이선스로 공개
Video JEPA
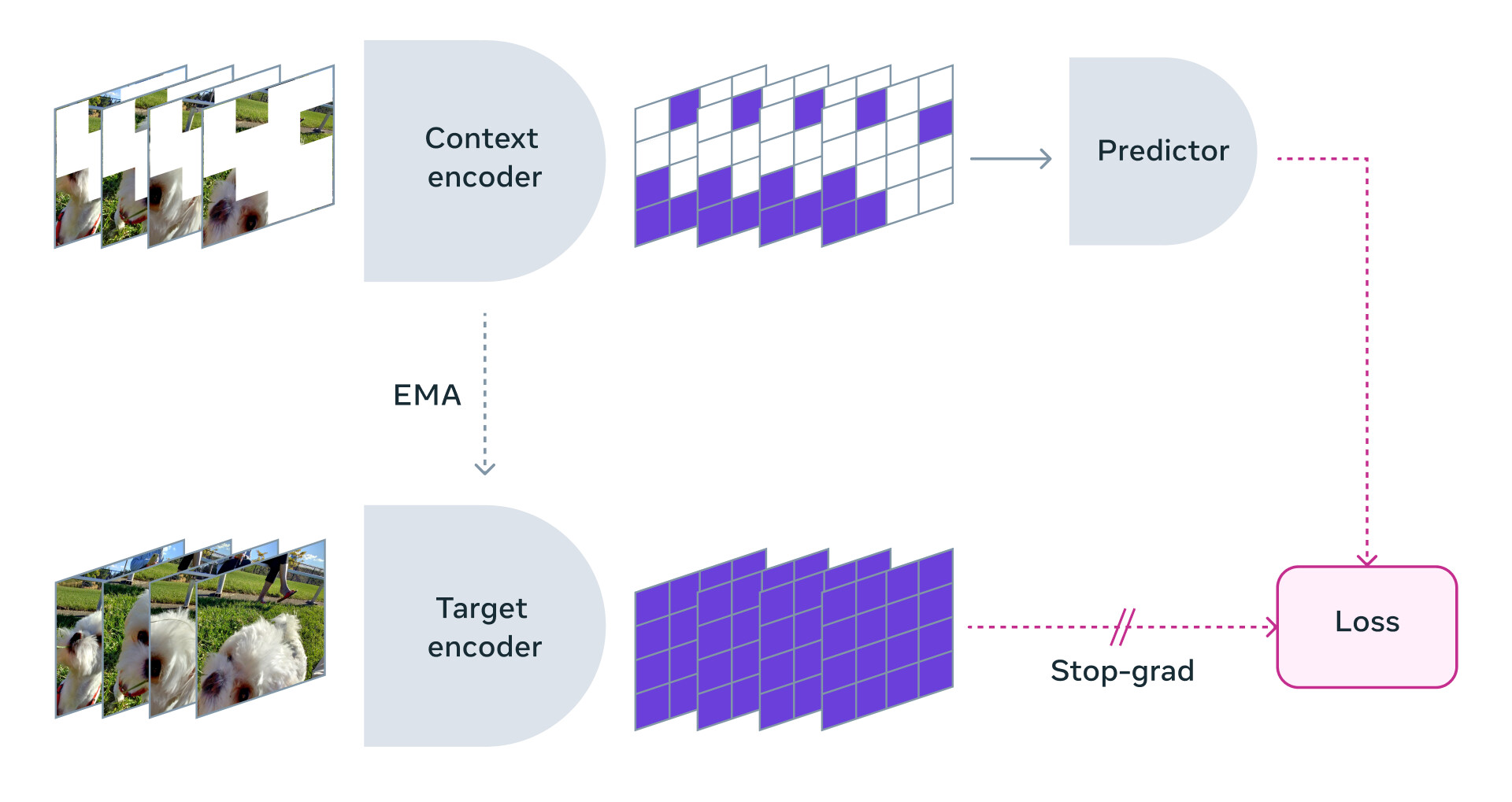
- V-JEPA는 비디오의 누락되거나 가려진 부분을 추상적 표현 공간에서 예측함으로써 학습하는 비생성적 모델
- 이 모델은 예측할 수 없는 정보를 버릴 수 있는 유연성을 가지고 있어, 훈련 및 샘플 효율성을 1.5배에서 6배까지 향상시킴
- V-JEPA는 레이블이 없는 데이터로만 사전 훈련되며, 레이블은 사전 훈련 후 특정 작업에 모델을 적용할 때만 사용
마스킹 방법론
- V-JEPA는 특정 유형의 동작을 이해하기 위해 훈련된 것이 아니라, 다양한 비디오에 대한 자기 감독 학습을 사용하여 세계가 작동하는 방식에 대해 여러 가지를 학습함
- 마스킹 전략은 비디오의 큰 영역을 차단하지 않고 여기저기에서 무작위로 패치를 샘플링하는 것이 아니라, 공간과 시간 모두에서 비디오의 부분을 마스킹하여 모델이 장면을 이해하고 학습하도록 함
효율적인 예측
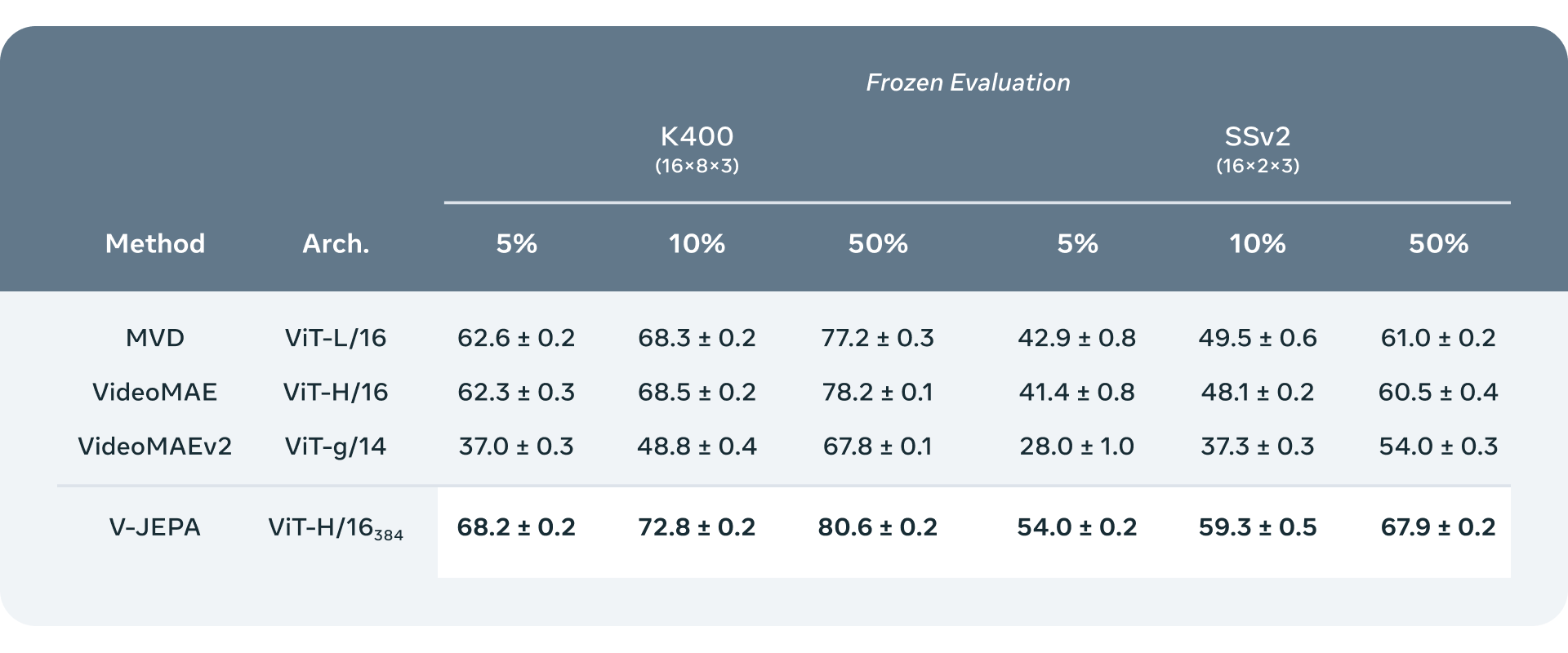
- 추상적 표현 공간에서 예측을 수행하는 것은 모델이 비디오에 포함된 고차원 개념 정보에 집중할 수 있게 하며, 다운스트림 작업에 대부분 중요하지 않은 세부 사항에 대해 걱정할 필요가 없음
- V-JEPA는 "동결 평가"에서 뛰어난 성능을 보이는 첫 번째 비디오 모델로, 자기 감독 사전 훈련을 거친 인코더와 예측기를 더 이상 건드리지 않고 새로운 기술을 학습할 때 효율적이고 빠르게 특수화된 층이나 작은 네트워크를 훈련함
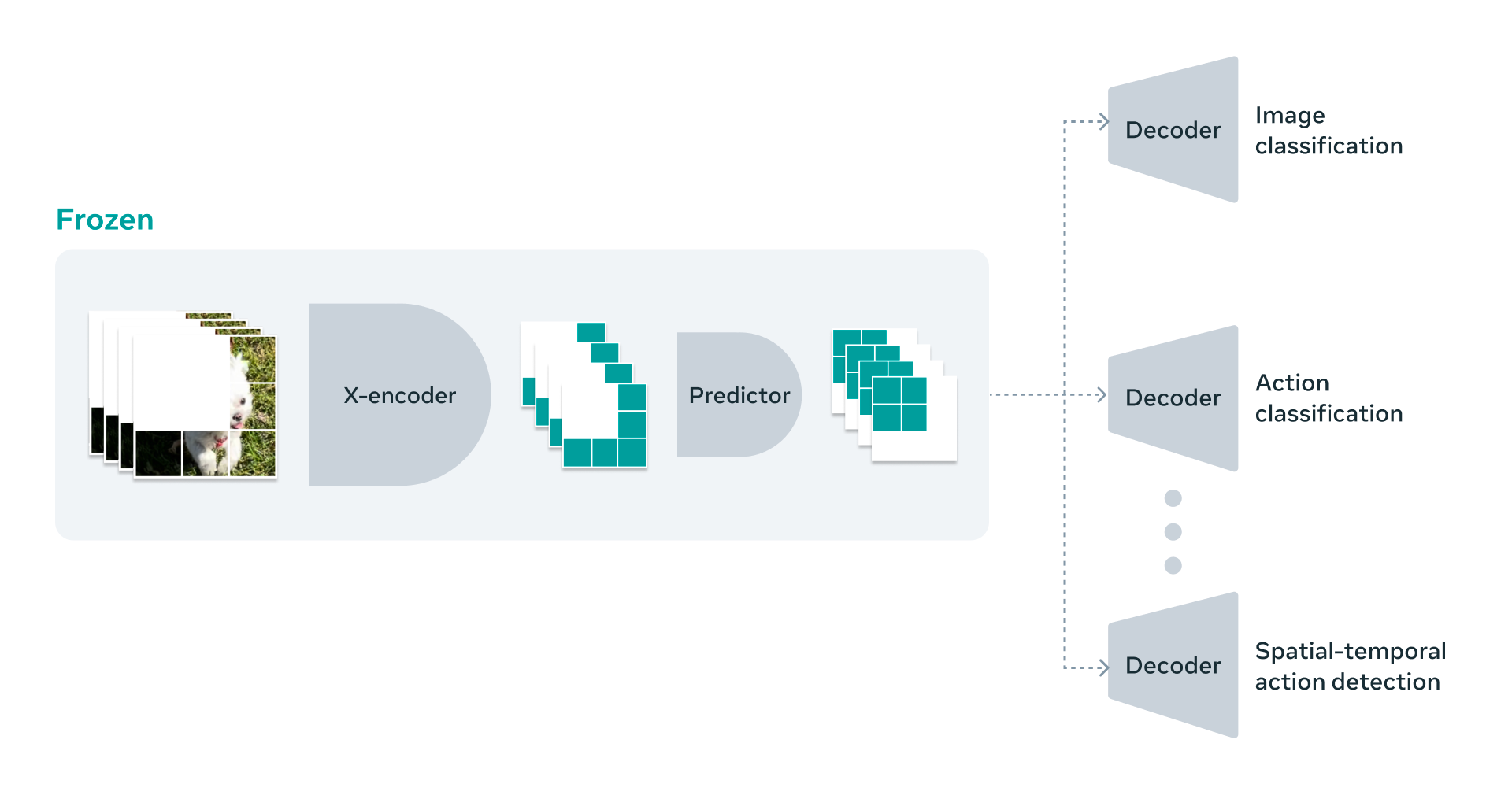
미래 연구를 위한 길
- "V"는 비디오를 의미하지만, 현재 V-JEPA 모델은 시각적 콘텐츠만을 고려함
- 다음 단계로, 시각적 콘텐츠와 함께 오디오를 통합하는 더 다중 모달 접근 방식을 고려 중
- V-JEPA는 미세한 객체 상호작용을 구별하고 시간이 지남에 따라 발생하는 상세한 객체 간 상호작용을 인식하는 데 뛰어남
AMI로 가는 길
- 지금까지 V-JEPA와 관련된 작업은 주로 인식에 관한 것으로, 다양한 비디오 스트림의 내용을 이해하여 주변 세계에 대한 일부 맥락을 얻는 것임
- 다음 단계로, 이러한 예측기 또는 세계 모델을 계획이나 순차적 의사결정을 위해 사용하는 방법을 보여주고자 함
- V-JEPA는 연구 모델이며, 향후 응용 분야를 탐구 중임. 예를 들어, V-JEPA가 제공하는 맥락은 실제 AI 작업과 미래 AR 안경을 위한 Contextual AI 보조기구 구축 작업에 유용할 수 있음
- 책임감 있는 오픈 사이언스의 가치를 확신하며, 다른 연구자들이 이 작업을 확장할 수 있도록 V-JEPA 모델을 CC BY-NC 라이선스로 공개
더 읽어보기
V-JEPA 소개 글
V-JEPA 논문
V-JEPA 코드
https://github.com/facebookresearch/jepa
I-JEPA 소개 글
V-JEPA와 유사한 Image-JEPA(Joint Embedding Predictive Architecture)의 소개 글