GeekNews의 xguru님께 허락을 받고 GN에 올라온 글들 중에 AI 관련된 소식들을 공유하고 있습니다. ![]()
소개
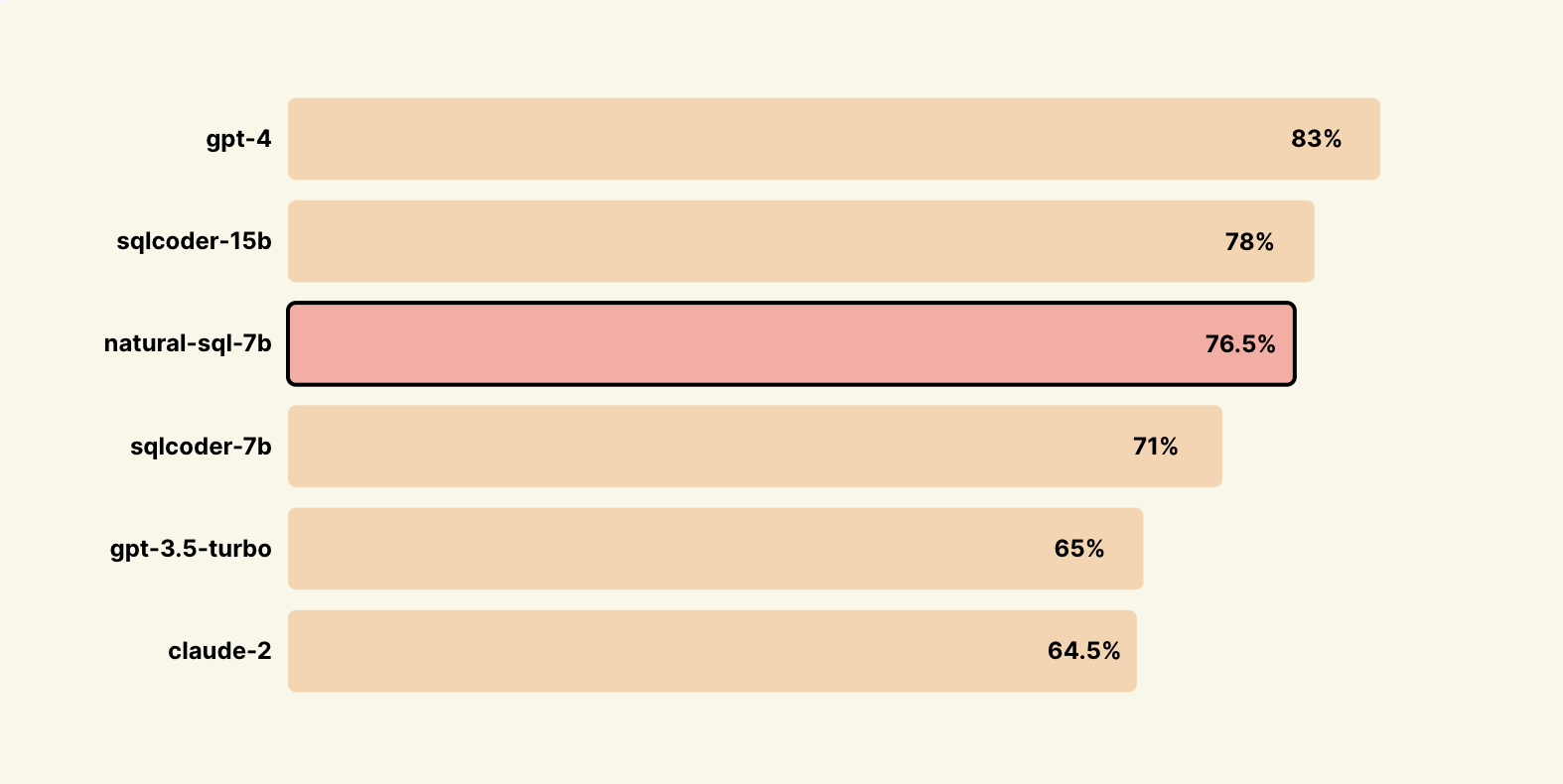
- SQL-Eval 에서 76.5% 달성하여, 모델 크기 기준에서 최고의 성능을 보임
- GPT-4(83%) 보다는 못하지만 GPT-3.5-Turbo(65%) / Claude-2(64.5%) 보다 뛰어남
- sqlcoder-7b(71%) 보다 높고 sqlcoder-15b(78%)와 비슷
- SQL 작성할 필요없이 대시보드를 노코드로 만들어주는 도구인 ChatDB가 개발
예시
- 질문:
지난달에 가장 많은 주문 금액을 가진 고객을 결정하고, 그들이 주문한 모든 제품과 수량을 나열하시오. - 출력:
WITH LastMonthOrders AS (
SELECT o.customerid, o.orderid, op.productid, op.quantity, p.productname, op.quantity * p.unitprice AS total_order_value
FROM orders o
JOIN order_details op ON o.orderid = op.orderid
JOIN products p ON op.productid = p.productid
WHERE o.orderdate >= date_trunc('month', CURRENT_DATE) - INTERVAL '1 month'
AND o.orderdate < date_trunc('month', CURRENT_DATE)
),
CustomerTotalOrderValue AS (
SELECT customerid, SUM(total_order_value) AS total_value
FROM LastMonthOrders
GROUP BY customerid
ORDER BY total_value DESC
LIMIT 1
)
SELECT c.customerid, c.companyname, lm.productid, lm.productname, lm.quantity
FROM CustomerTotalOrderValue ctov
JOIN LastMonthOrders lm ON ctov.customerid = lm.customerid
JOIN customers c ON c.customerid = lm.customerid;
- NaturalQuery는 위와 같은 복잡한 질문, 서브쿼리, 비율에 대해 매우 잘 수행함.
Hacker News 의견
- SQL-Eval에서의 성능 점수가 76.5%로, GPT-4의 83%와 sqlcoder-15b의 78%에 조금 뒤처짐.
- 이러한 AI 데이터 과학 인턴이 유용할 수 있는 응용 분야는 무엇일까? 75%의 정확도를 가진 AI를 활용해 무엇을 만들 수 있을까?
- SQL 작업 시 자주 참고자료를 찾아보는 프로그래머로서, 이런 AI를 첫 번째 쿼리 초안 작성에 활용할 수 있을 것 같음.
- 큰 모델들이 한 번의 케이스에서 더 나은 결과를 제공할 수 있지만, 64GB m1에서 15b 모델을 쉽게 실행할 수 있음.
- 기업 환경에서는 스키마 정보를 OpenAI의 훈련 데이터로 유출하고 싶지 않고, 오프라인에서 쿼리를 실행하고 싶을 때도 있음.
- 많은 쿼리를 수행하고 싶을 때 작고 로컬 모델이 유용함(비용 절감).
- 비기술적인 사람들도 질의할 수 있는 미니 데이터 과학자는 멋질 것이나, 쿼리가 25%의 '부정확한' 경우에 속하는지 판단하는 방법이 궁금함.
- 여러 AI가 서로의 답변을 검증하는 RAID와 같은 합의 알고리즘을 통해 전체 성공률을 높일 수 있을지도 모름.
- 이러한 생각은 대부분 생각을 정리하는 과정이지만, 다른 사람들이 더 많은 아이디어를 가질 수도 있음. OP의 출시를 축하함!
- 텍스트-투-SQL 모델들이 올바른 문제를 해결하고 있지 않다고 생각함.
- 어려운 부분은 문법이나 'group by' 쿼리 작성 방법을 모르는 것이 아니라, 데이터의 의미를 이해하는 것임.
- Snowflake의 50개 컬럼 테이블을 보고 컬럼 이름만으로 무엇인지 추측할 수 없음.
- 예를 들어, 모두 ...price로 명명된 10개의 컬럼이 있는 테이블이 있을 때, 실제 의미를 알기 위해 위키를 찾아보거나 DBT 정의를 읽어야 함.
- 모델이 생성하는 쿼리를 신뢰할 수 없음, 모델은 데이터를 이해하지 못하고 쿼리 문법만 이해함.
- 이것이 오픈 소스가 아니라는 점을 지적함, 사용 기반 제한이 있기 때문에 '소스 사용 가능'이라고 부를 것.
- 이것은 흥미롭고 관심 있는 분야에 해당하지만, 그것이 복잡한 질문이라고 생각하지 않음, 기본적인 분석 질문임.
- 대부분의 분석가들은 잠을 자면서도 이런 것을 작성할 수 있음.
- ChatGPT를 SQL 작성에 사용해보았지만 평범함, 하지만 분명히 나아질 것임.
- AI의 많은 사용처와 마찬가지로, 특히 범위에 따라 그룹화하는 것과 같은 아이디어를 제시할 때 '시드'로서 매우 좋음.
- 그러나 거의 모든 데이터베이스에서 문제는 세부 사항에 있음.
- 다양한 제품이 '수량'을 다르게 해석하고(예: 박스 대 단위), 쿠폰과 할인이 이상한 방식으로 모델링되며, 무게가 파운드/킬로그램으로 가정되고 단위 지정 없이 혼합됨 등등.
- 이것이 75%만 정확하다고 해서 쓸모없다고 말하는 사람들은 다음 두 가지를 고려해야 함:
- 이것은 첫 번째 버전이며, 이미 상상할 수 있는 어떤 에어테이블보다 제품 소유자와 분석가들에게 천 배 더 유용함.
- 모든 도전에 정확하고 싶은 마음은 있지만, 우리는 이미 "충분히 좋은" 경제에서 살고 있으며, 이것이 충분히 가까우면 비즈니스에 충분히 좋을 것임.
- 더 복잡하고 현실적인 벤치마크인 Bird에서 어떻게 수행하는지 궁금함.
- 데이터 분야에서 일한 경험을 바탕으로, 많은 사람들이 경영진으로부터 질문을 받고, 데이터 웨어하우스를 충분히 이해하여 그 질문에 답할 SQL을 작성하고, 때로는 예쁘게 포맷된 답변을 전달하는 책임이 있음.
- 때로는 경영진이 "왜 그 숫자가 너무 낮아? 분명히 그렇게 낮아서는 안 되는데"와 같은 후속 질문을 예측해야 하므로 데이터 엔지니어에게 버그를 확인하도록 요청해야 함.
- 모든 LLM과 마찬가지로, 이것이 그 책임을 훨씬 쉽게 만들 것인지, 아니면 완전히 없앨 것인지 확신할 수 없음.
- 정말 멋진데, 라이센스가 표준이 아님에도 불구하고 오픈 소스처럼 보임.
- 실제 모델은 여기에서 찾을 수 있음: NaturalSQL-6.7B-v0
- 이것은 훌륭한 기본 모델로 보이지만, 작은 모델에 대해 text-to-sql이 좋은 사용 사례인지 궁금함.
- 우리도 이 분야에서 도구를 개발하고 있으며, 답변을 더 잘 알고 있기를 바라며 gpt-4를 사용하고 싶음. 심지어 gpt 3.5도 생산에 충분하지 않음.
- 매우 멋진데, 이 라이센스가 Vanna와 함께 사용할 수 있을지 궁금함: Vanna
원문
NaturalSQL 개발사 ChatDB 홈페이지
NaturalSQL 예시 코드가 포함된 GitHub 저장소
https://github.com/cfahlgren1/natural-sql