GeekNews의 xguru님께 허락을 받고 GN에 올라온 글들 중에 AI 관련된 소식들을 공유하고 있습니다. ![]()
소개
- TensorRT 딥러닝 컴파일러와 최적화된 커널, 전처리/후처리 단계, 멀티GPU/멀티노드 통신 기본요소 등을 포함
- C++ 이나 CUDA에 대한 깊은 지식 없이도 LLM에 최고 성능과 사용자 정의 기능을 빠르게 제공 가능
- 오픈소스 모듈식 Python API를 제공하여 사용 편의성과 확장성 제공
- Ampere, Lovelace, Hopper GPU 지원
- H100 기반으로 TensorRT-LLM을 적용하여 테스트 했을 때
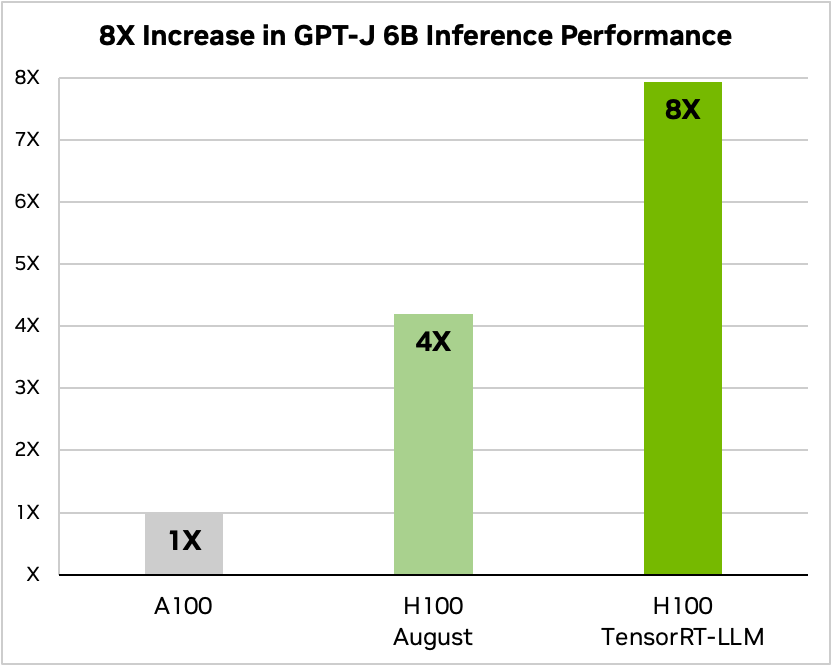
- GTP-J-6B 는 추론 성능 8배 향상, TCO 5.3배 감소, 에너지 소비량 5.6배 감소
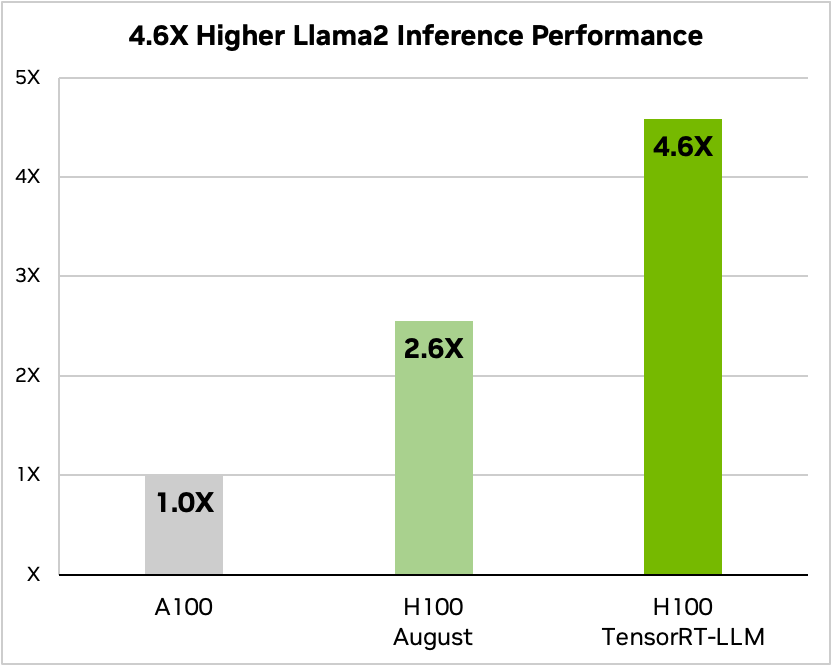
- Llama2 70B 는 추론 성능 4.6배 향상, TCO 3배 감소, 에너지 소비량 3.2배 감소
- GTP-J-6B 는 추론 성능 8배 향상, TCO 5.3배 감소, 에너지 소비량 5.6배 감소
- In-flight Batching 이라 불리는 최적화된 스케줄링 기술 포함
- TensorRT-LLM이 탑재된 NVIDIA H100 GPU는 사용자에게 모델 가중치를 새로운 FP8 형식으로 쉽게 변환하고 모델을 컴파일하여 최적화된 FP8 커널을 자동으로 활용할 수 있는 기능을 제공
- Hopper Transformer 엔진 기술을 통해 가능하며, 모델 코드를 변경할 필요 없음
- 현재 얼리억세스 가능하며, 몇주내로 출시할 예정