GeekNews의 xguru님께 허락을 받고 GN에 올라온 글들 중에 AI 관련된 소식들을 공유하고 있습니다. ![]()
소개
![[GN] PowerInfer - 소비자용 GPU를 사용해서 빠르게 LLM 서빙하기](https://discuss.pytorch.kr/uploads/default/original/2X/9/950c4bf9abe4167c31d7aca516fab5fba375d5e7.gif)
-
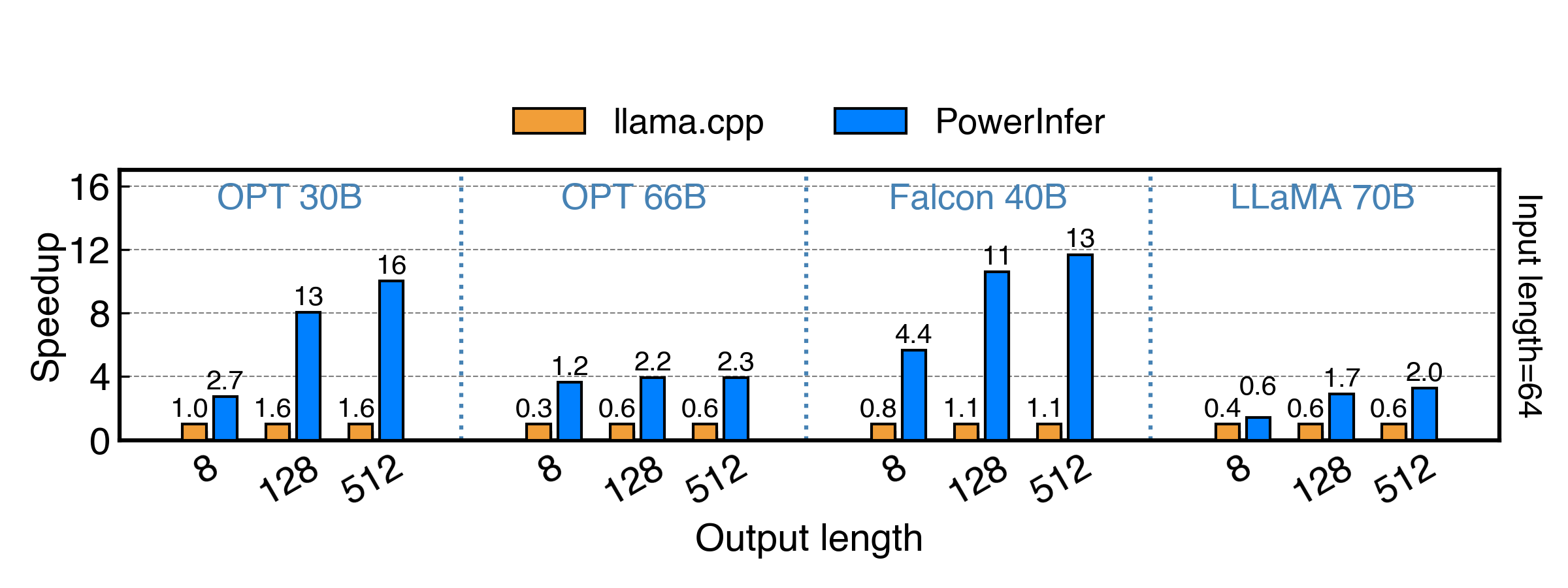
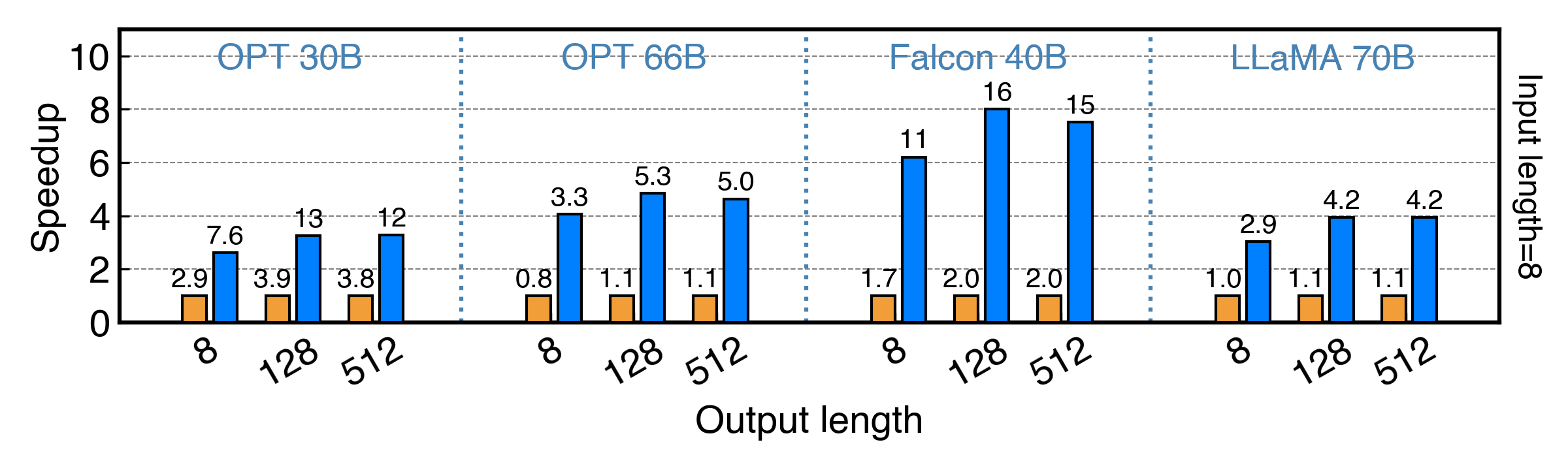
RTX 4090(24G)에서 Falcon(ReLU)-40B-FP16 실행시 llama.cpp 보다 11배 빠름
-
기기의 Activation Locality를 활용하는 CPU/GPU 하이브리드 LLM 추론엔진
- 일관되게 활성화되는 일부의 핫뉴런, 특정 입력에 따라 달라지는 대다수의 콜드뉴런으로 구분
- 핫 뉴런은 GPU에 미리 로드하여 빠르게 활성화, 콜드 뉴런은 CPU에서 계산해서 GPU 메모리 요구량과 CPU-GPU 데이터 전송을 크게 줄임
-
적응형 예측기와 뉴런 인식 희소 연산자를 통합하여 뉴런 활성화와 계산 희소성의 효율성을 최적화
-
단일 NVIDIA RTX 4090 GPU에서 다양한 LLM(OPT-175B 포함)에 걸쳐 평균 13.20 토큰/초, 최고 29.08 토큰/초의 토큰 생성 속도를 달성
- 이는 최상위 서버급 A100 GPU가 달성한 것보다 18% 낮은 수치에 불과
- 모델 정확도를 유지하면서 최대 11.69배까지 llama.cpp의 성능을 크게 뛰어넘는 것
모델 가중치 (Model Weights)
PowerInfer 모델은 LLM 가중치와 예측자 가중치로 구성된 GGUF 형식을 기반으로 하는 PowerInfer GGUF라는 특수 포맷으로 저장됩니다.
Download PowerInfer GGUF via Hugging Face
아래 *.powerinfer.gguf에서 PowerInfer GGUF 가중치와 '핫' 뉴런 오프로딩에 대한 프로파일링된 모델 활성화 통계를 각 허깅 페이스 리포지토리에서 얻을 수 있습니다.
| Base Model | PowerInfer GGUF |
|---|---|
| LLaMA(ReLU)-2-7B | PowerInfer/ReluLLaMA-7B-PowerInfer-GGUF |
| LLaMA(ReLU)-2-13B | PowerInfer/ReluLLaMA-13B-PowerInfer-GGUF |
| Falcon(ReLU)-40B | PowerInfer/ReluFalcon-40B-PowerInfer-GGUF |
| LLaMA(ReLU)-2-70B | PowerInfer/ReluLLaMA-70B-PowerInfer-GGUF |
전체 리포지토리를 다운로드/복제하여 PowerInfer가 자동으로 이러한 디렉터리 구조를 사용하여 기능을 갖춘 모델을 오프로드할 수 있도록 하는 것이 좋습니다:
.
├── *.powerinfer.gguf (Unquantized PowerInfer model)
├── *.q4.powerinfer.gguf (INT4 quantized PowerInfer model, if available)
├── activation (Profiled activation statistics for fine-grained FFN offloading)
│ ├── activation_x.pt (Profiled activation statistics for layer x)
│ └── ...
├── *.[q4].powerinfer.gguf.generated.gpuidx (Generated GPU index at runtime for corresponding model)
원래 모델 가중치 + 예측자 가중치에서 변환하기
Hugging Face는 단일 모델 가중치를 50GiB로 제한합니다. 정량화되지 않은 모델 >= 40B의 경우, 원래 모델 가중치와 허깅 페이스에서 얻은 예측자 가중치에서 PowerInfer GGUF를 변환할 수 있습니다.
| Base Model | Original Model | Predictor |
|---|---|---|
| LLaMA(ReLU)-2-7B | SparseLLM/ReluLLaMA-7B | PowerInfer/ReluLLaMA-7B-Predictor |
| LLaMA(ReLU)-2-13B | SparseLLM/ReluLLaMA-13B | PowerInfer/ReluLLaMA-13B-Predictor |
| Falcon(ReLU)-40B | SparseLLM/ReluFalcon-40B | PowerInfer/ReluFalcon-40B-Predictor |
| LLaMA(ReLU)-2-70B | SparseLLM/ReluLLaMA-70B | PowerInfer/ReluLLaMA-70B-Predictor |
원문
https://github.com/SJTU-IPADS/PowerInfer