9bow
(박정환)
1
GeekNews의 xguru님께 허락을 받고 GN에 올라온 글들 중에 AI 관련된 소식들을 공유하고 있습니다. 
소개
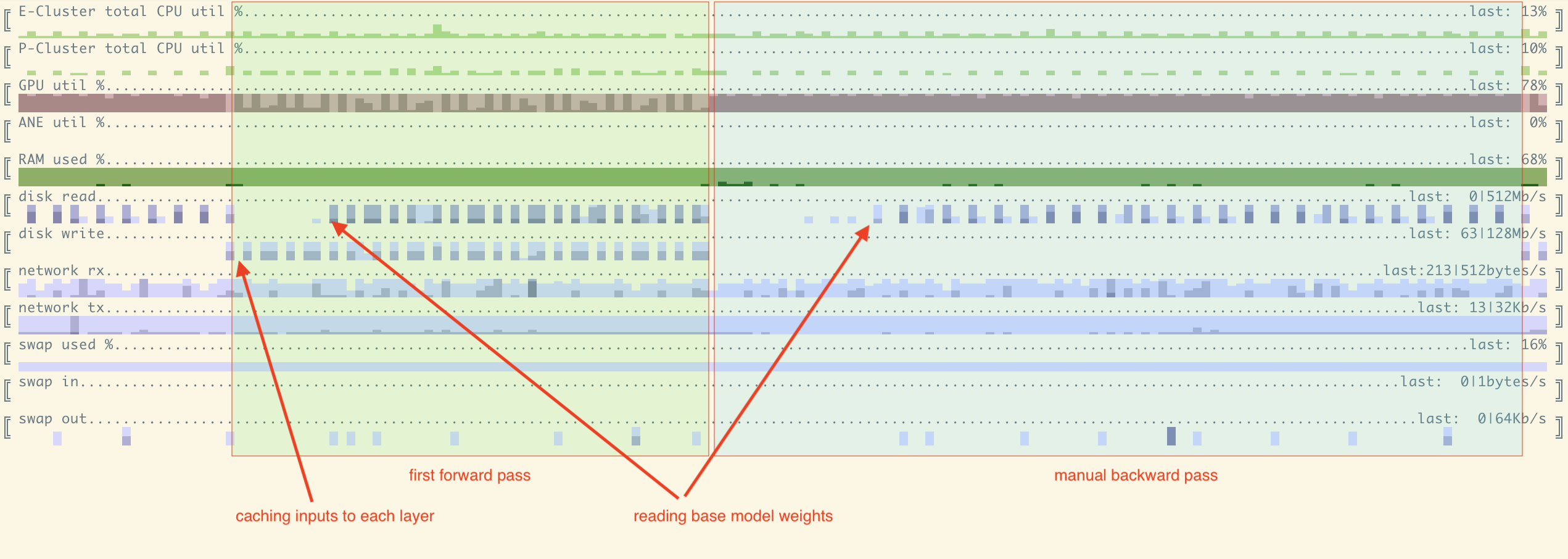
- 애플 M1/M2 및 소비자용 nVidia GPU에서 LLama2-70B 같은 모델을 파인튜닝
- 양자화(quantization)를 사용하는 대신, 포워드/백워드 패스 모두에서 모델의 일부를 SSD또는 메인 메모리로 오프로드 하는 방식
- 현재 버전을 LoRA를 사용하여 업데이트를 더 작은 매개변수 셋으로 제한
- 첫번째 버전은 전체 파인튜닝도 가능했지만 지금은 제거
원문
더 읽어보기
2개의 좋아요
감사합니다. 그렇지 않아도 Mac M2에서 finetuning 하는 방법을 찾고 있었습니다.
1개의 좋아요
9bow
(박정환)
3
옷, 잘 되시면 결과 공유 부탁드립니다! +_+
1개의 좋아요