GeekNews의 xguru님께 허락을 받고 GN에 올라온 글들 중에 AI 관련된 소식들을 공유하고 있습니다. ![]()
소개
![[GN] Stable Diffusion 3 연구 논문 공개](https://discuss.pytorch.kr/uploads/default/original/2X/4/43256a138ae4e04d3db5ae7e6eb0e53858a8f8eb.jpeg)
- Stable Diffusion 3를 구동하는 기술에 대해 깊이 탐구하는 연구 논문을 발표
- SD3는 인간의 선호도 평가에 기반하여 타이포그래피와 프롬프트 준수 면에서 DALL·E 3, Midjourney v6, Ideogram v1과 같은 최신의 텍스트-이미지 생성 시스템을 능가함
- 새로운 Multimodal Diffusion Transformer (MMDiT) 아키텍처는 이미지와 언어 표현을 위한 별도의 가중치 세트를 사용하여 이전 버전의 SD3에 비해 텍스트 이해와 철자 능력을 향상시킴
성능
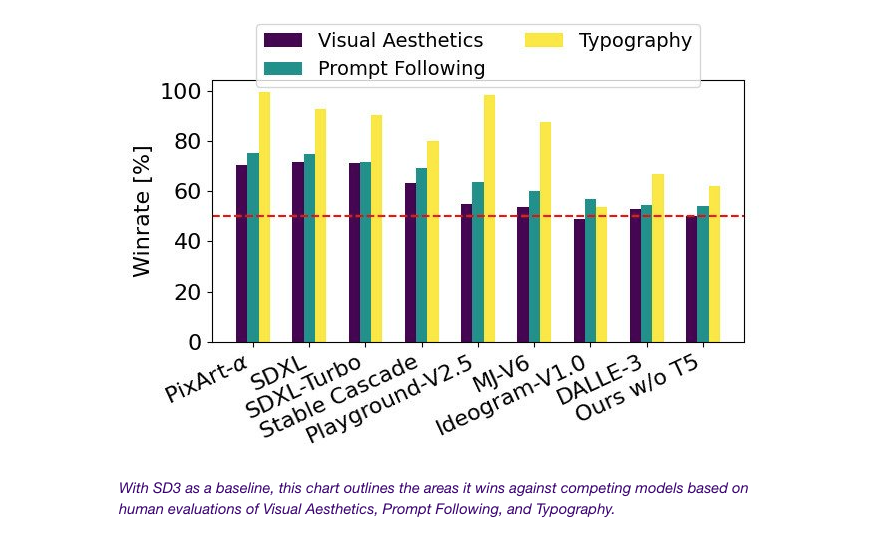
- Stable Diffusion 3의 출력 이미지를 SDXL, SDXL Turbo, Stable Cascade, Playground v2.5, Pixart-α 등 다양한 오픈 모델과 DALL·E 3, Midjourney v6, Ideogram v1과 같은 폐쇄 소스 시스템과 비교하여 인간 피드백을 기반으로 성능을 평가
- 테스트 결과, Stable Diffusion 3은 모든 위의 영역에서 현재 최신 텍스트-이미지 생성 시스템과 동등하거나 능가함
- 초기 비최적화 추론 테스트에서 가장 큰 SD3 모델은 8B 매개변수를 가지고 있으며, RTX 4090의 24GB VRAM에 맞고, 50개의 샘플링 단계를 사용할 때 1024x1024 해상도의 이미지를 생성하는 데 34초가 소요됨
- 초기 릴리스 시 800m에서 8B 매개변수 모델에 이르는 다양한 Stable Diffusion 3 변형이 있어 하드웨어 장벽을 추가로 제거함
아키텍처 세부 사항
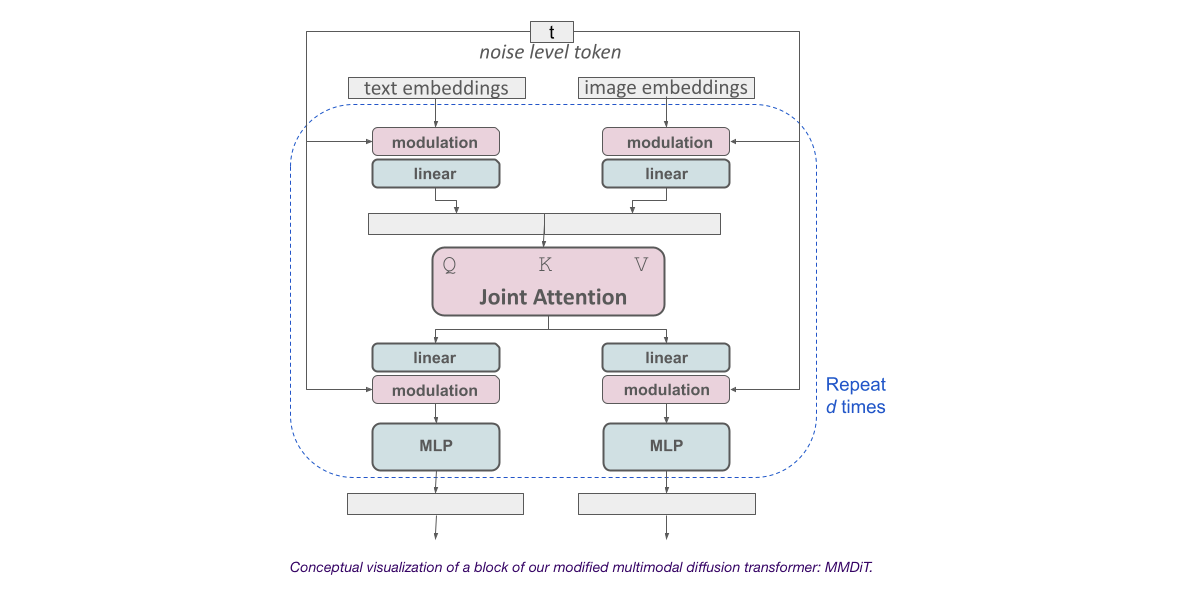
-
Stable Diffusion 3는 Diffusion Transformer 구조를 기반으로 구성됨
-
텍스트-이미지 생성을 위해 모델은 텍스트와 이미지 두 가지 모달리티를 모두 고려해야 함
-
이 새로운 아키텍처를 MMDiT라고 부르는데, 이는 다양한 모달리티를 처리할 수 있는 능력을 참조
-
이전 버전의 Stable Diffusion과 마찬가지로, 적절한 텍스트와 이미지 표현을 도출하기 위해 사전 훈련된 모델을 사용
-
텍스트와 이미지 임베딩은 개념적으로 매우 다르기 때문에, 두 모달리티에 대해 별도의 가중치 세트를 사용함
-
이 접근 방식을 사용함으로써, 이미지와 텍스트 토큰 사이에 정보가 흐를 수 있어 출력물의 전반적인 이해도와 타이포그래피를 향상시킴
-
이 아키텍처는 비디오와 같은 다중 모달리티로 쉽게 확장 가능함

Reweighting을 이용한 Rectified Flows 개선
- Stable Diffusion 3은 훈련 중 데이터와 노이즈를 선형 궤적으로 연결하는 Rectified Flow (RF) 공식을 사용
- 이는 더 직선적인 추론 경로를 만들어 더 적은 단계로 샘플링을 가능하게 함
- 또한, 훈련 과정에 새로운 궤적 샘플링 일정을 도입하여, 궤적의 중간 부분에 더 많은 가중치를 부여함
- 이 접근법을 다른 확산 궤적과 비교하여 테스트한 결과, 이전 RF 공식은 적은 단계 샘플링 체제에서 성능이 향상되었지만, 더 많은 단계에서는 상대적 성능이 감소함
- 반면, 재가중된 RF 변형은 일관되게 성능을 향상시킴
Rectified Flow Transformer 모델의 확장
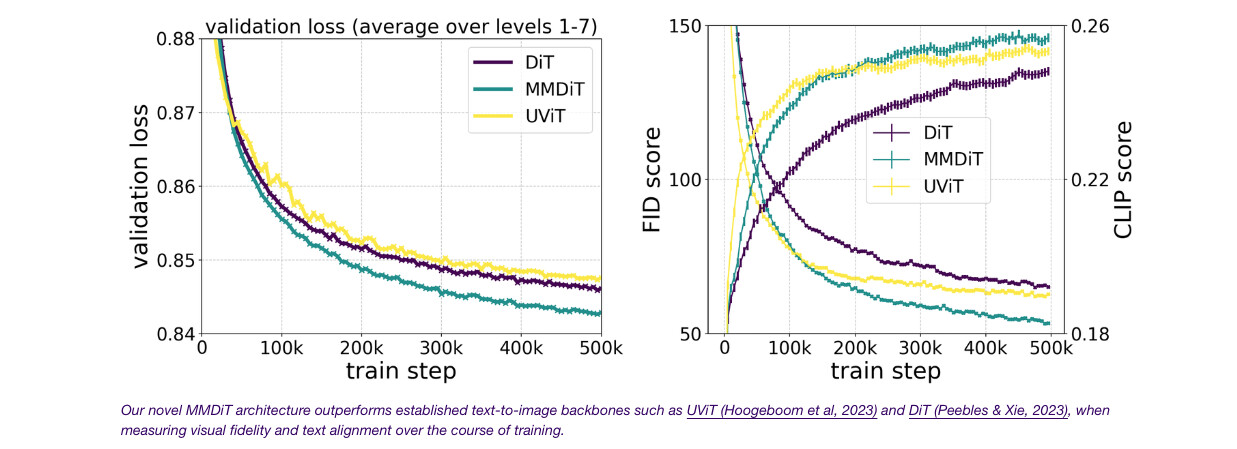
- 재가중된 Rectified Flow 공식과 MMDiT 백본을 사용하여 텍스트-이미지 합성을 위한 스케일링 연구를 수행함
- 모델 크기와 훈련 단계 모두에 대한 검증 손실의 부드러운 감소를 관찰함
- 이것이 모델 출력의 의미 있는 개선으로 번역되는지 테스트하기 위해 자동 이미지 정렬 메트릭(GenEval)과 인간 선호도 점수(ELO)를 평가함
- 결과는 이러한 메트릭과 검증 손실 사이에 강한 상관 관계를 보여줌
- 스케일링 추세는 포화 징후를 보이지 않아, 향후 모델의 성능을 계속 향상시킬 수 있을 것이라는 낙관적인 전망
유연한 텍스트 인코더

- 추론을 위해 메모리 집약적인 4.7B 매개변수 T5 텍스트 인코더를 제거함으로써, SD3의 메모리 요구 사항을 크게 줄일 수 있으며 성능 손실은 미미함
- 이 텍스트 인코더를 제거하면 시각적 미학에는 영향을 주지 않으며(제거 후 승률: 50%), 텍스트 준수에는 약간 감소함(승률 46%)
- 그러나 T5를 포함하는 것이 SD3의 전체 힘을 발휘하여 텍스트를 생성하는 데 권장됨
Hacker News 의견
- Stability AI의 오픈 소스에 대한 헌신이 매우 흥미롭고, 그들이 가능한 오랫동안 운영되기를 바람.
- Stable Diffusion 3이 여전히 OpenAI의 CLIP을 토큰화와 텍스트 임베딩에 사용하는지 궁금함.
- 모델 아키텍처의 해당 부분을 개선하여 텍스트와 이미지 프롬프트에 더 잘 부합하도록 할 것이라고 단순히 가정함.
- Stable Diffusion 3의 텍스트 렌더링이 인상적이지만, 텍스트에 항상 특유의 과도하게 처리된 느낌이 있음.
- 텍스트 색상이 항상 한 가지 값으로 높아져서 고품질 이미지에 텍스트를 아마추어처럼 단순히 추가한 것처럼 보임.
- SD3가 다운로드 가능한지 여부에 대한 질문.
- 초기 버전의 SD를 로컬에서 실행했는데 매우 좋았음.
- 많은 LLM들이 자체 호스팅이 유망했던 것처럼 SAAS로 전환되었는지 궁금함.
- 이미지 생성기가 마침내 철자를 올바르게 구현하기 시작한 것이 매우 흥미로움.
- DALL-E 3의 철자 능력이 부각되었지만 Bing을 사용해 본 결과 일관성이 떨어짐.
- 철자를 올바르게 구현하는 데 직면한 도전과 그 이유에 대해 덜 기술적인 설명을 읽고 싶음.
- SD3가 오래된 이미지의 텍스트 문제를 정리하거나 수정할 수 있는지 궁금함.
- SD3의 발표가 매우 흥미로움.
- 논문은 블로그보다 훨씬 더 자세한 내용을 담고 있음.
- 논문의 주요 내용은 더 표현력 있는 텍스트 인코더를 포함할 수 있는 아키텍처를 가지고 있으며, 이것이 복잡한 장면에 도움이 됨을 보여줌.
- 훈련 측면에서 이 스택의 한계에 도달하지 않았으므로, SD3.1이 더 개선될 것으로 기대하고, SD4는 비디오 처리를 위해 더 많은 프론트 엔드 인코딩을 추가할 수 있을 것으로 예상함.
- SD3의 텍스트 렌더링 개선은 좋지만, 손과 손가락을 생성하는 것은 여전히 어려움.
- 예시 이미지에는 픽셀화된 마법사를 제외하고 인간의 손이 포함되어 있지 않으며, 원숭이의 손은 다소 이상함.
- 이 아키텍처는 비디오로 쉽게 확장될 수 있을 만큼 충분히 유연함.
- LLaMA의 트랜스포머 블록처럼 또 다른 "기초" 블록이 될 것으로 기대됨.
- 텍스트 인코딩/타임스텝 조건을 블록에 다양한 방식으로 통합할 수 있을 만큼 충분히 일반적임.
- 위치 인코딩(2D RoPE?)과 관련하여 놀아볼 것 외에는 할 일이 거의 남아 있지 않음.
- 트랜스포머를 확장하고 양자화/최적화에 집중하여 이 스택을 모든 곳에서 제대로 실행할 수 있도록 함.
- 한때 '오픈'에 전념했거나 이전에 오픈이었던 많은 회사들이 점점 더 폐쇄적으로 변하고 있음.
- Stability AI가 이러한 연구 논문을 공개하는 것에 감사함.
- Stability AI와 대조적으로, OpenAI는 가장 폐쇄적인 AI 연구소임.
- Deep Mind조차 더 많은 논문을 발표함.
- OpenAI 내부에서 "돈을 위해 여기에 있다!"고 공개적으로 말하는 사람이 있는지 궁금함.
- SamA가 Elon의 재판에 대해 최근에 쓴 편지는 푸틴이 우크라이나를 '탈나치화'하기 위해 침략한다고 말하는 것만큼 진실함.