GeekNews의 xguru님께 허락을 받고 GN에 올라온 글들 중에 AI 관련된 소식들을 공유하고 있습니다. ![]()
소개
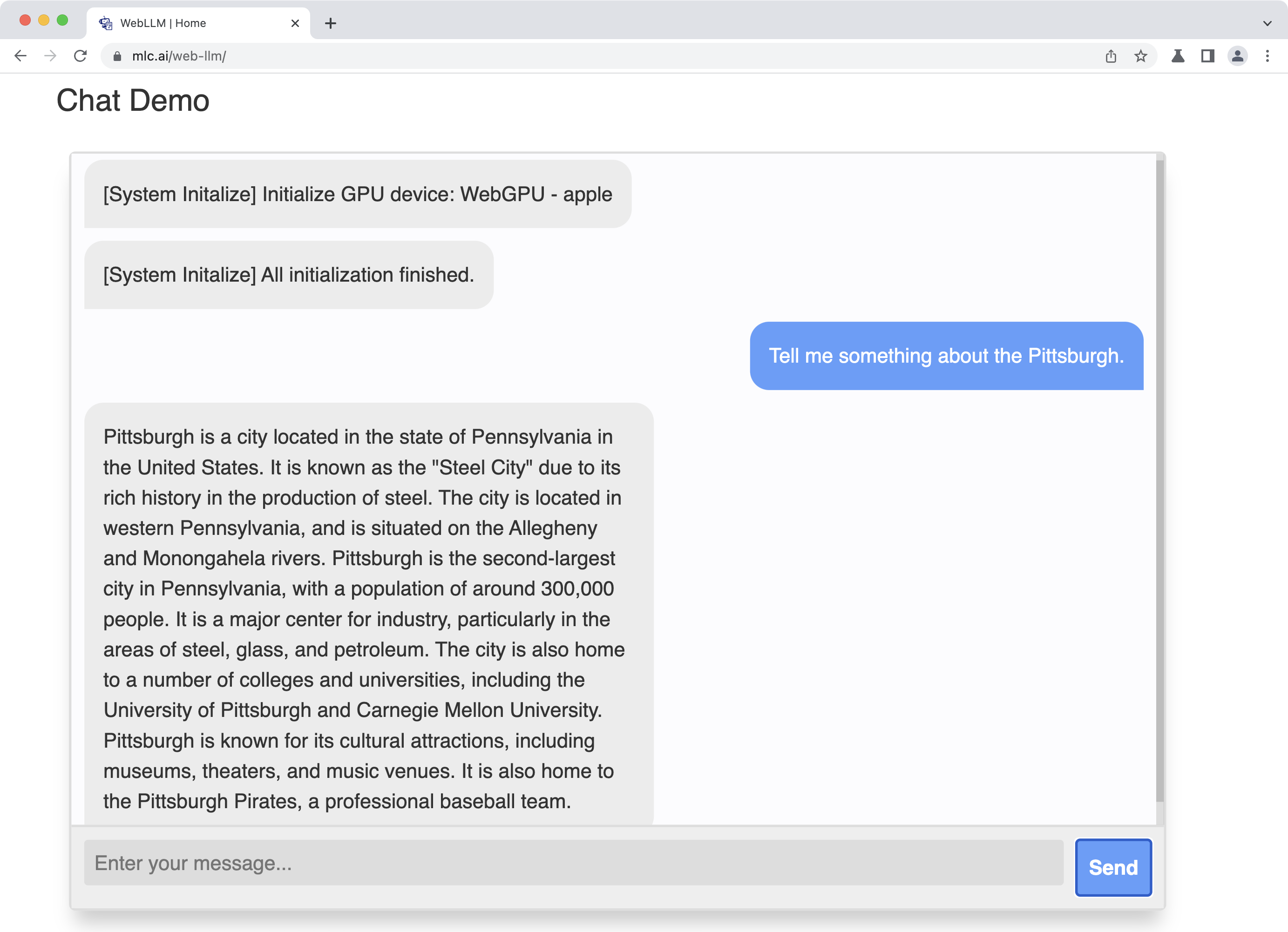
- Web LLM은 서버 없이 브라우저에서 직접 실행하는 MLC LLM의 컴패니언 프로젝트
- 웹 브라우저에서 Llama, RedPajama, Vicuna 같은 LLM을 WASM으로 구동하는 서비스
- Llama 2 7B/13B 지원 시작 llama2
- Llama 2 70B도 지원하지만, 애플 실리콘 맥 + 64GB 램 이상에서만 사용 가능
- WebGPU를 사용하여 가속 기능 사용 가능 (Chrome 113+에서만 지원) webgpu
원문
홈페이지
사용해 볼 수 있는 데모
사용해 볼 수 있는 모델:
- Llama-2-7b-chat-hf-q4f32_1
- Llama-2-13b-chat-hf-q4f32_1
- Llama-2-7b-chat-hf-q4f16_1
- Llama-2-13b-chat-hf-q4f16_1
- Llama-2-70b-chat-hf-q4f16_1
- RedPajama-INCITE-Chat-3B-v1-q4f32_0
- RedPajama-INCITE-Chat-3B-v1-q4f16_0
- Vicuna-v1-7b-q4f32_0
GitHub 저장소
MLC LLM 프로젝트 소개 mlc-llm
튜토리얼 예제
- get-started: 가볍게 시작해볼 수 있는 예제
- web-worker: Web-worker 지원 채팅 예제
- simple-chat: 작은 규모의 완전한 채팅 앱
 허깅페이스 데모 스페이스
허깅페이스 데모 스페이스
- web-llm-embed: transformers.js 임베딩과 함께 react-llm을 사용하는 문서 채팅 프로토타입 데모 스페이스