
Gemma 3 소개
Google DeepMind가 싱글 GPU 또는 TPU에서도 최상의 성능을 발휘할 수 있는 경량화된 최신 오픈 LLM, Gemma 3를 발표했습니다. Gemma 3는 1B에서 27B까지 다양한 파라미터 크기를 제공하며, Hugging Face, JAX, PyTorch 등 다양한 개발 환경과 호환됩니다. 또한, 최신 NVIDIA GPU 및 Google Cloud TPU에서도 최적화된 성능을 제공합니다.

Gemma 3는 이미지와 텍스트를 동시에 처리하는 멀티모달 기능과 함께 140개 이상의 언어를 지원하며, 최대 128K 토큰 컨텍스트, 고급 텍스트 및 비주얼 추론 기능, 함수 호출 지원 등을 갖추고 있습니다. 특히, 경량화(Quantization)된 버전이 제공되어 저사양 장치에서도 높은 성능을 발휘합니다.
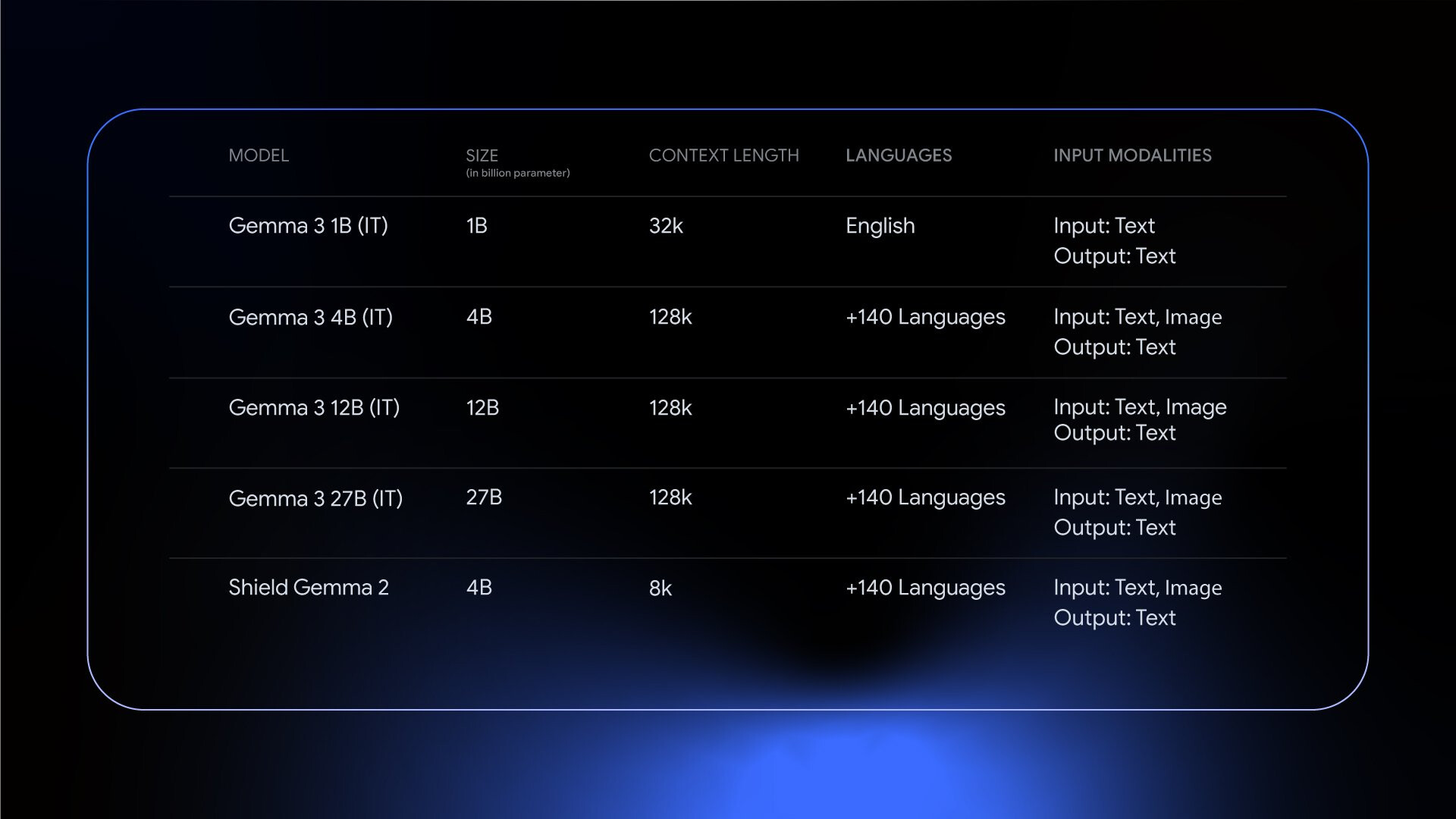
Gemma 3의 주요 특징은 다음과 같습니다:
- 모델 크기: 1B, 4B, 12B, 27B 파라미터 모델 제공
- 컨텍스트 길이: 1B 모델은 32K, 나머지는 128K 토큰 지원
- 멀티모달 지원: 4B 이상 모델에서 이미지+텍스트 입력 가능
- 다국어 지원: 4B 이상 모델에서 140개 이상의 언어 지원
특히, Gemma-3-4B-IT 모델이 이전 Gemma-2-27B IT보다 뛰어난 성능을 보이며, Gemma-3-27B-IT는 Gemini 1.5-Pro까지 뛰어넘는 성능을 기록했습니다.
Gemma 3의 주요 기술적 향상점
-
멀티모달 기능: Gemma 3는 맞춤형 SigLIP 비전 인코더를 사용하여 이미지를 소프트 토큰의 시퀀스로 변환합니다. 이미지를 256 벡터로 압축하여 시각 데이터를 처리하는 비용을 줄였습니다. P&S(Pan and Scan) 기법을 적용하여 다양한 이미지 비율과 해상도를 지원하며, 필요에 따라 비인칭적으로 조정됩니다.
-
긴 문맥 지원: 모델은 최대 128K 토큰의 문맥 길이를 지원하며, 이는 KV 캐시 메모리 문제를 해결하기 위한 로컬 및 글로벌 주의 레이어의 비율을 조정함으로써 이루어졌습니다. 로컬 레이어를 간격으로 배치하고, 각 로컬 레이어의 길이를 1024 토큰으로 제한하여 글로벌 레이어만 긴 문맥에 주의를 기울입니다. 글로벌 레이어의 RoPE(base frequency)를 10k에서 1M으로 증가시켰으며, 로컬 레이어는 10k를 유지합니다.
-
사전 학습 최적화: Gemma 3는 동일한 토크나이저를 사용하며, 다국어 데이터의 양을 증가시켰습니다. 학습 데이터는 이미지와 텍스트의 조합을 포함하며, 비율 조정을 통해 언어 representation의 불균형을 해결했습니다. 학습은 지식 증류 기법을 사용하여 진행됩니다. 이는 모델이 교사 모델의 분포를 학습하는 방식으로, 비모수적으로, 즉, 모집단으로부터 표본을 추출하여 교차 엔트로피 손실을 통해 학습합니다.
-
사후 학습: 사후 학습 단계에서는 수학적 연산, 추론 및 대화 능력 개선에 초점을 맞추며, 새로운 기능인 긴 문맥 및 이미지 입력을 통합합니다. 신뢰할 수 있는 방식으로 성능을 개선하기 위해, 다양한 보상 함수를 사용하여 사용자 도움, 수학, 코딩, 추론, 다국어 능력을 높이고, 모델의 유해성을 줄입니다. 이 과정에서 RLHF(강화 학습을 통한 인간 피드백)를 활용합니다.
Gemma 3 성능 비교
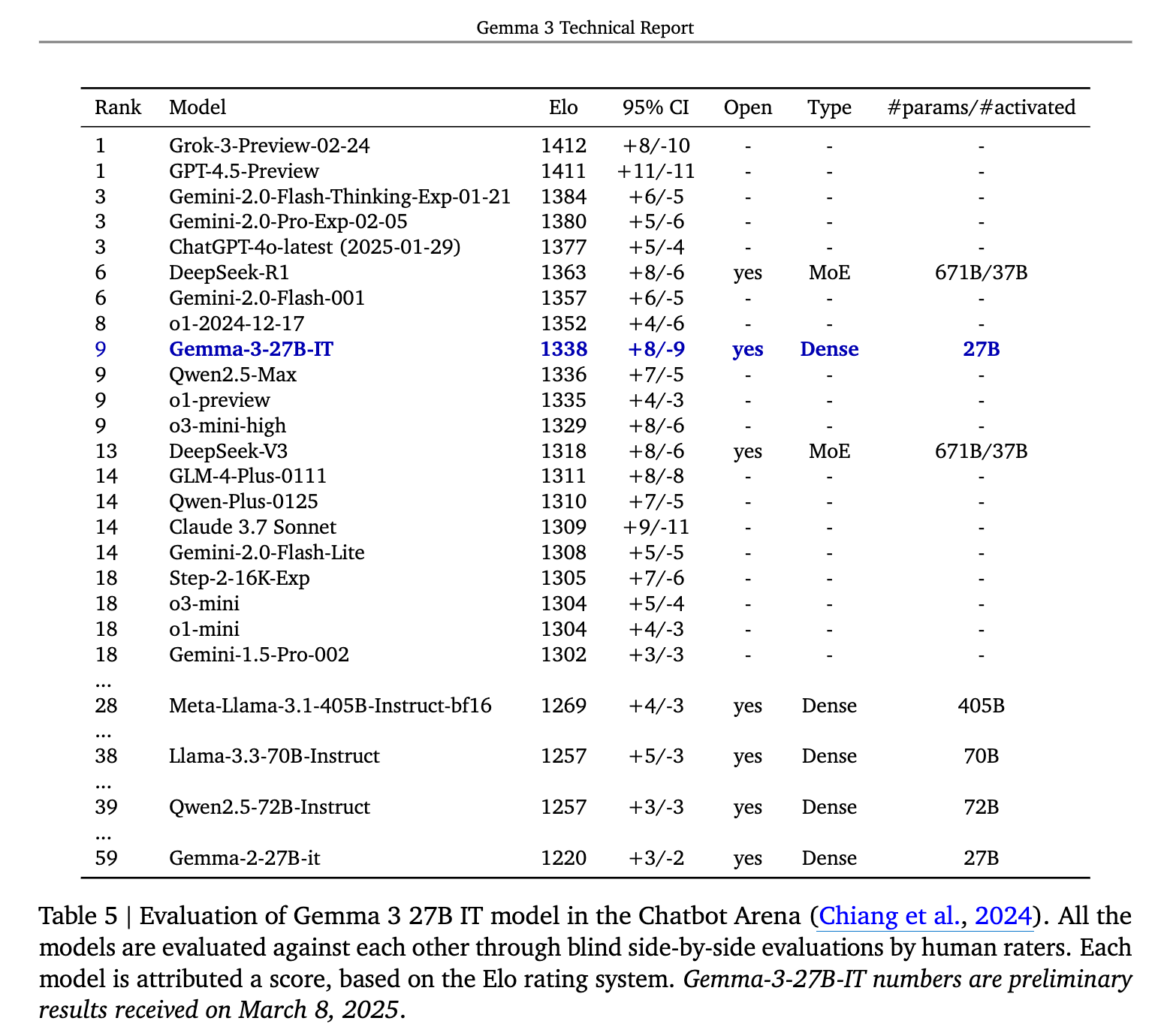
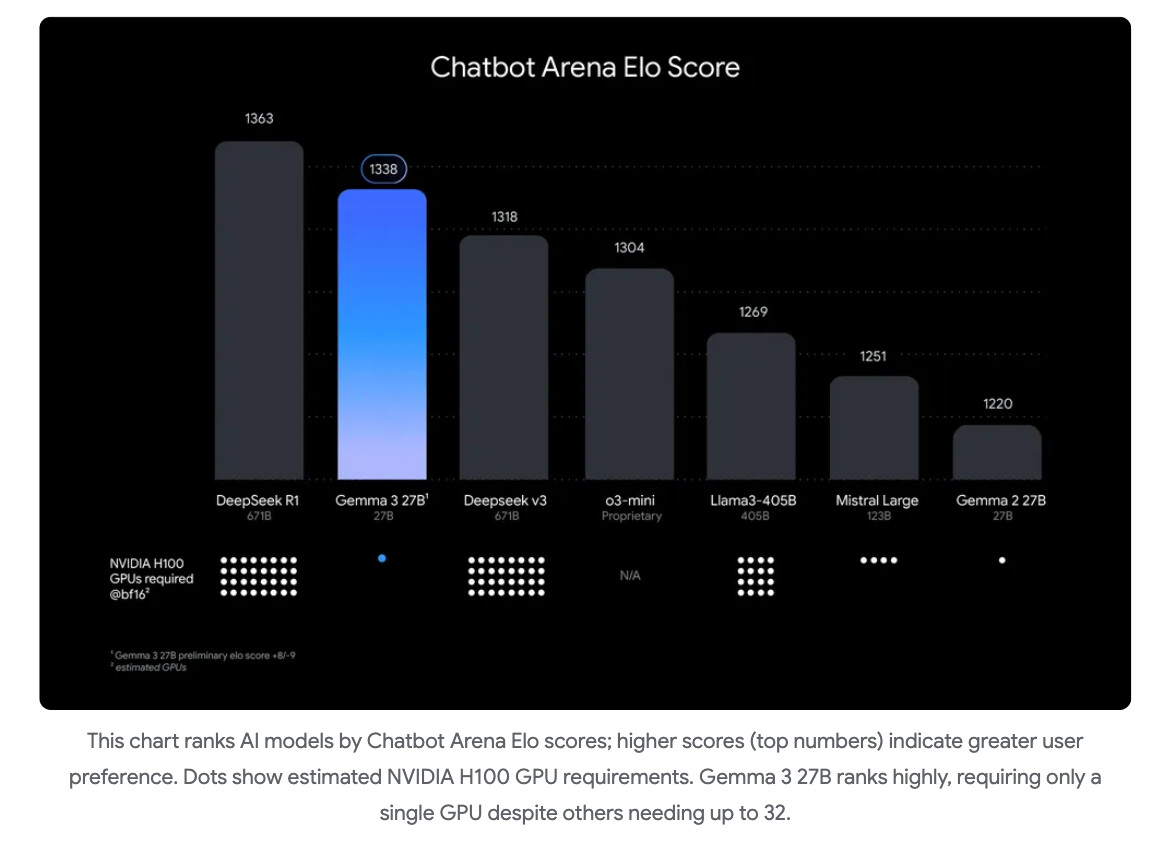
Gemma-3-27B-IT는 LMSYS 챗봇 아레나에서 1338 Elo 점수를 받아 9위를 기록했습니다. (2025년 3월 8일 기준)
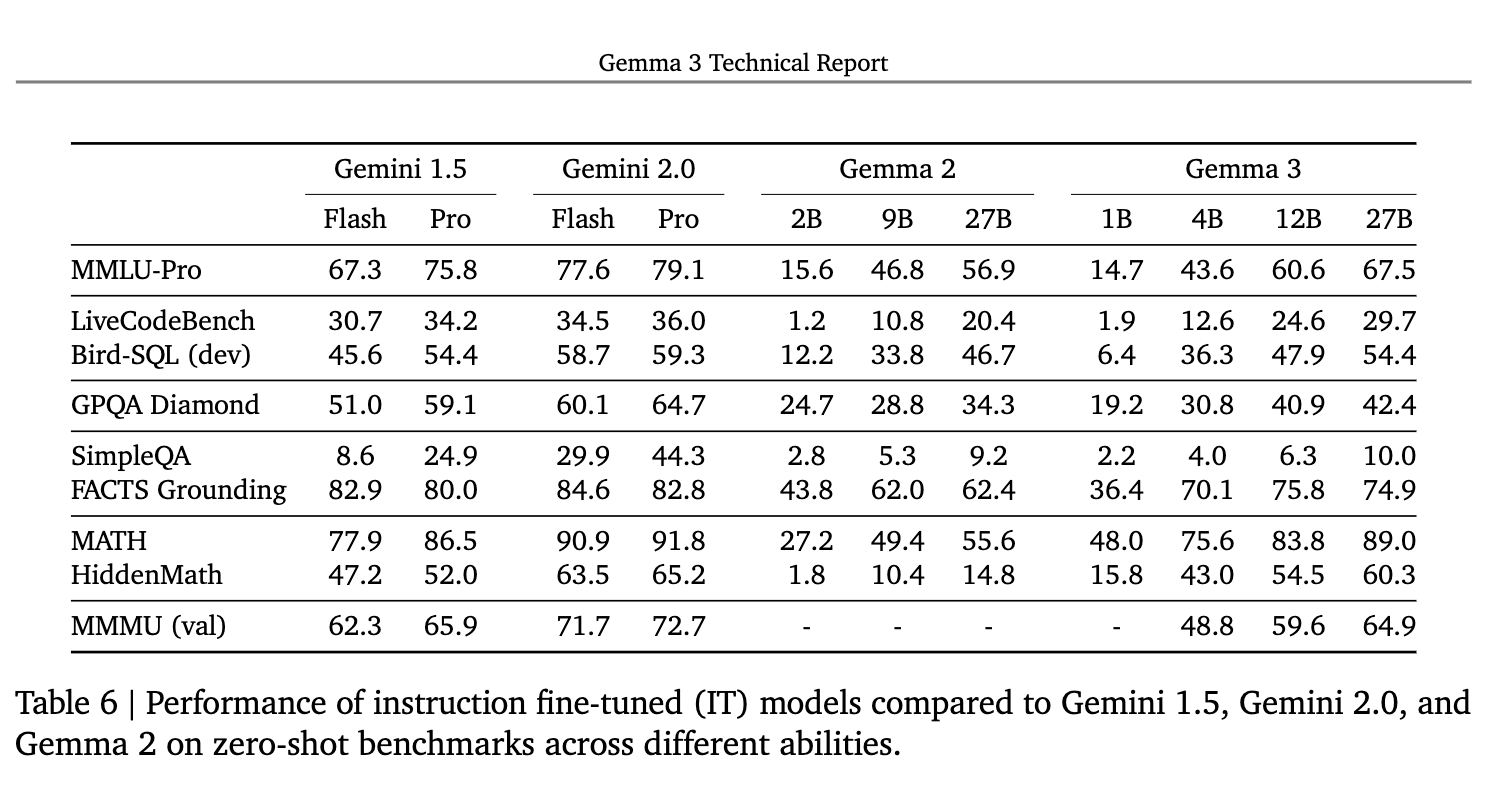
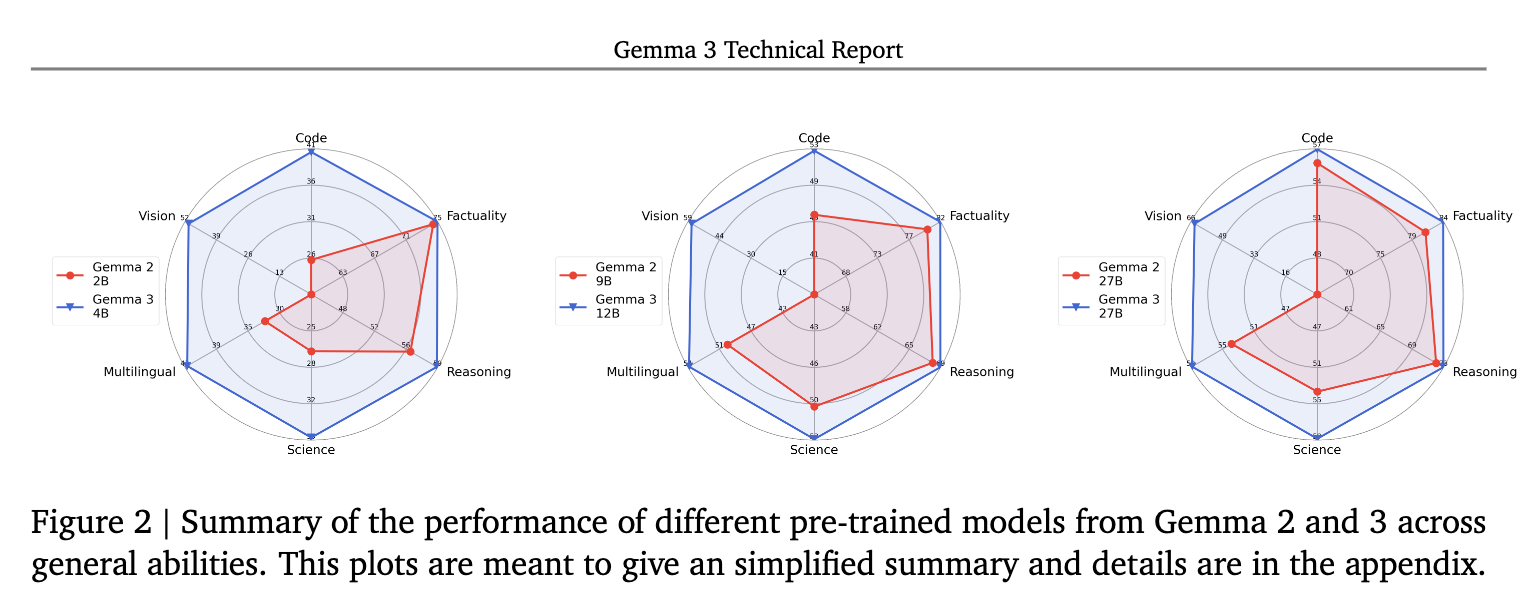
Gemma 3는 MMLU-Pro, LiveCodeBenchBird-SQL, GPQA Diamond, SimpleQA - FACTS Grounding, MATH HiddenMath, MMMU 등의 다양한 벤치마크 등에서 이전 버전의 Gemma 2 대비 향상된 성능을 보였습니다. 또한, 유사한 크기의 모델들을 Code, Factuality, Reasoning, Science, Multilingual, Vision 등의 영역에서 사전 학습 모델의 일반적인 능력을 비교해봤을 때도 Gemma 2 대비 향상된 것을 확인할 수 있었습니다.
Gemma 3 설치 및 활용 예시
Gemma 3 설치 (Hugging Face)
# 최신 버전의 transformers 설치
pip install git+https://github.com/huggingface/transformers@v4.49.0-Gemma-3
from transformers import pipeline
pipe = pipeline("text-generation", model="google/gemma-3-4b-it")
print(pipe("Gemma 3란?", max_length=100))
멀티모달 활용 예시
이미지와 텍스트를 동시에 처리하는 멀티모달 기능은 4B, 12B, 27B 모델에서 지원되며, 아래와 같이 사용 가능합니다:
from transformers import pipeline
pipe = pipeline(
"image-text-to-text",
model="google/gemma-3-4b-it",
device="cuda"
)
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "https://example.com/image.jpg"},
{"type": "text", "text": "이 이미지 속 버튼 중 난방을 켜는 버튼은?"}
]
}
]
output = pipe(text=messages)
print(output[0]["generated_text"])
함수 호출(Function Calling) 지원
Gemma 3는 API 호출 및 자동화된 워크플로우를 구성할 수 있는 함수 호출 기능을 제공합니다. 이 기능을 활용하여 외부 API와 상호작용하여 다양한 작업을 수행하는 AI 에이전트 구축이 가능합니다.
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "내일 서울 날씨 어때?"},
{"type": "function_call", "name": "get_weather", "arguments": {"location": "Seoul", "date": "tomorrow"}}
]
}
]
 Google의 Gemma 3 모델 소개 블로그
Google의 Gemma 3 모델 소개 블로그
Google의 개발자를 위한 Gemma 3 소개 블로그
 Hugging Face의 (사용 예시를 포함한) Gemma 3 모델 소개 블로그
Hugging Face의 (사용 예시를 포함한) Gemma 3 모델 소개 블로그
Gemma 3 모델 다운로드
모델 목록
| Pre Trained | Instruction Tuned | Multimodal | Multilingual | Input Context Window |
|---|---|---|---|---|
| gemma-3-1b-pt | gemma-3-1b-it | English | 32K | |
| gemma-3-4b-pt | gemma-3-4b-it | +140 languages | 128K | |
| gemma-3-12b-pt | gemma-3-12b-it | +140 languages | 128K | |
| gemma-3-27b-pt | gemma-3-27b-it | +140 languages | 128K |
Gemma 3 모델 컬렉션
Gemma 3 기술 리포트(Technical Report)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()