파이토치를 사용하여 Self-Supervised Learning을 공부하고있는 학생입니다.
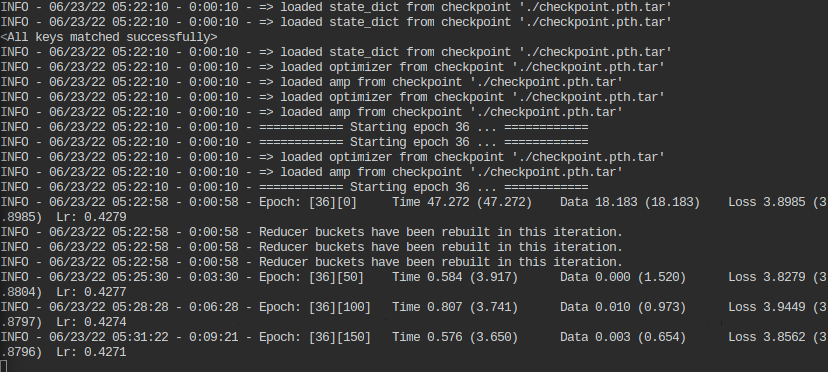
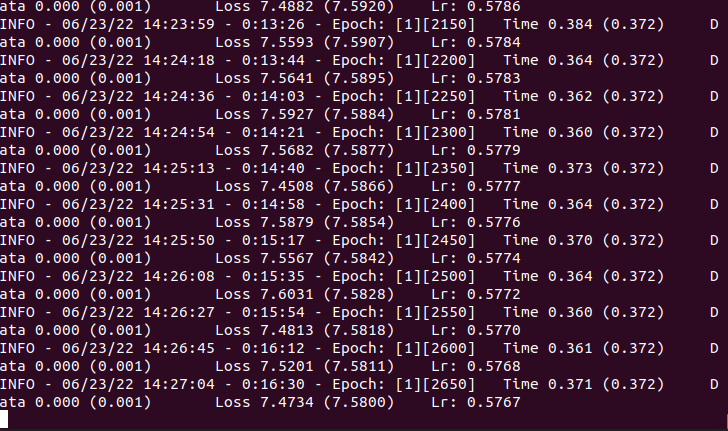
다름이 아니라 저희 서버에서 A100 GPU를 3장사용하여 학습시킬 때보다 로컬에서 3090 한장으로 학습시킬 때가 더 빠른데 왜 이런걸까요?
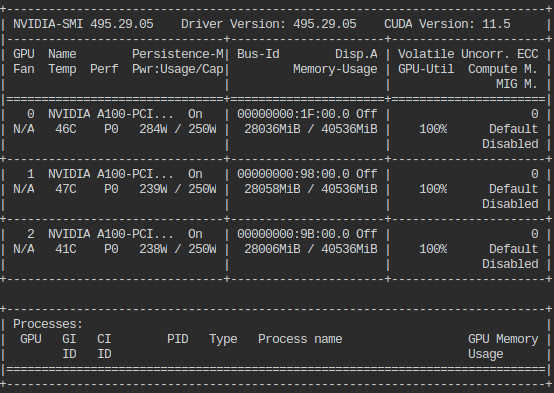
nvidia-smi로 사용상태를 보면 A100 3장 전부 돌아가는 것 같습니다.
차이점은 서버는 배치사이즈가 256이고 로컬은 128입니다만 iteration이 아닌 1epoch자체가 시간차이가 많이 나네요.
2개의 좋아요
여러가지 원인이 있을 수 있어서 확인할 부분 몇가지만 말씀 드리겠습니다.
- 도커의 버전
- 제 경험상 A100이 ngc가 아닌 도커에서 빠르게 동작하지 않는 경우가 있었습니다.
- 도커를 nvidia의 파이토치 빌드된 거로 한번 확인 부탁드립니다.
- Communiation Cost
- 일단 서버가 nvlink 버전인지 잘 모르겠지만 일단 1장에서 먼저 확인을 하시는게 좋을 것 같습니다.
- DDP를 사용하고 계시겠지만 혹시나 아니면 DDP로 하시는게 좋을 것 같습니다
- DDP 에서 worker 때문인지 (너무 많은지 적은지) 확인도 필요하고요
특별한 내용은 없지만 도움이 되셨으면 좋겠네요
3개의 좋아요
와우 A100... 부럽네요 ![]()
답글 감사합니다.
- 말씀하신 도커가 제가 생각하는 도커라면 도커는 사용하지 않고있습니다.
- DDP는 사용중인데 workers는 4로 해놨습니다. 그 이상으로 해보려했는데 '최대 워커는 4이다 그 이상하면 뭐 freeze어쩌구 저쩌구...'라는 경고문구가 뜨더라구요 ㅠ
혹시 최적화 worker 수를 따로 알수있는 방법이 있을까요?
- 암페어가 CUDA , Torch 버전 영향을 받는 경우가 있어서 번거로우시겠지만 NGC로 하는것을 추천드립니다.
- 1장에서 문제가 있나 없나를 먼저 보시고 워커를 1부터 확인 하시면서 올려 나가십시오. 워커가 많아서 병목이 생기는 경우도 있습니다.
- 화면 출력을 보니 amp 관련 내용도 보이는 것 같은데요 이슈가 좀 있는것 같으니 아래 내용도 참고 바랍니다.
torch.cuda.amp cannot speed up on A100 · Issue #57806 · pytorch/pytorch · GitHub
2개의 좋아요