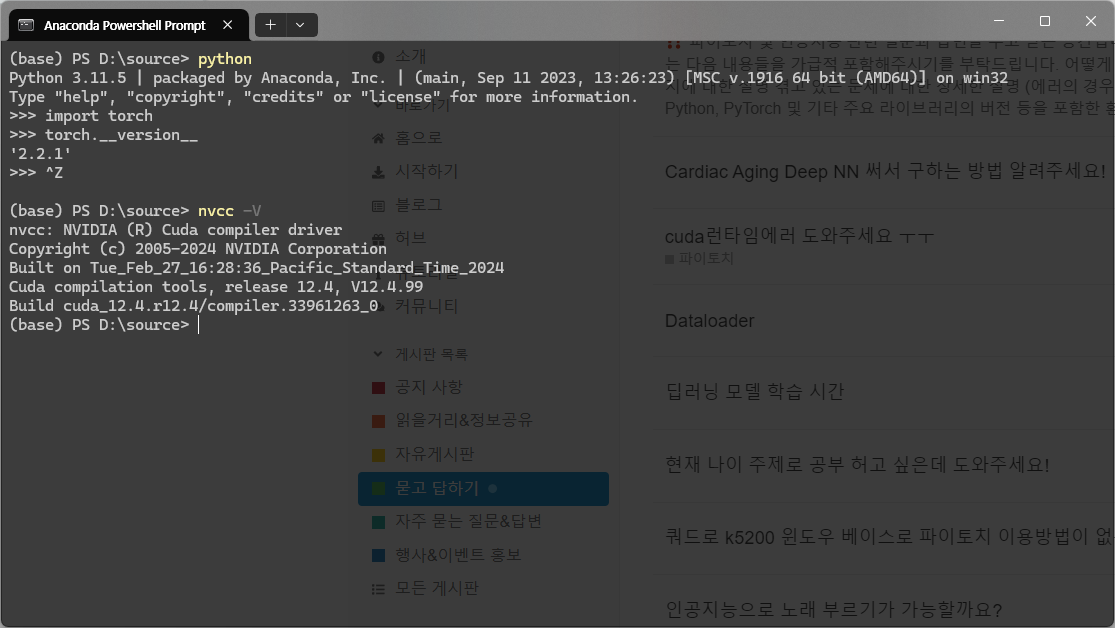
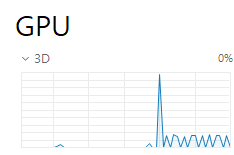
rtx 3090 ti를 쓰는 컴퓨터는 정상적으로 작동합니다. 위의 사진은 4090을 쓰는 컴퓨터에서 찍은 건데요, 4090으로 학습하는 게 3090 Ti로 학습하는 것보다 훨씬 느린데 왜 이럴까요? 참고로 cpu는 3090 ti는 amd 5900x, 4090은 7900x입니다. 아래 사진은 segmentation 데이터셋을 학습시키는 동안 작업관리자에서 gpu 사용률을 확인한 건데요, 지금 문제인 4090의 경우입니다. 일종의 병목 현상인 거 같은데 원인은 모르겠네요.
아래 답변은 OpenAI의 GPT-4-Turbo 모델로 자동 생성한 것으로, 정확하지 않을 수 있습니다.
잘못된 답변을 보셨다면 댓글로 첨삭 지도 부탁드립니다.
안녕하세요! GPU 성능과 관련된 문제로 고민하고 계신 것 같네요. 문제 상황을 정확히 이해하기 위해, 여러분이 제공한 정보를 바탕으로 요약해보겠습니다. 파이토치와 cudnn 버전에 대한 정보를 이미 확인하셨고, rtx 3090 ti를 사용하는 컴퓨터에서는 모든 것이 정상적으로 작동한다고 하셨습니다. 이로부터, GPU 성능에 관련된 특정 문제를 해결하고자 하는 것으로 보입니다. 다만, 구체적인 문제 상황이나 질문이 명시되지 않았기 때문에, 일반적인 GPU 성능 최적화 방법에 대해 안내드리겠습니다.
GPU 성능 최적화 방법
데이터 로딩 최적화: 데이터 로딩 시간을 줄이기 위해 torch.utils.data.DataLoader의 num_workers 파라미터를 적절히 설정하여 데이터 로딩을 병렬 처리합니다. 또한, pin_memory=True 옵션을 사용하여 데이터를 GPU 메모리에 미리 할당할 수 있습니다.
배치 크기 조정: GPU 메모리 용량에 맞게 배치 크기를 조정합니다. 큰 배치 크기는 메모리 사용량을 증가시키지만, 일반적으로 학습 속도를 향상시킬 수 있습니다. 메모리 오버플로우를 피하기 위해 적절한 크기를 찾는 것이 중요합니다.
모델 병렬화: 데이터 병렬 처리(DataParallel) 또는 모델 병렬 처리(ModelParallel)를 사용하여 여러 GPU에서 모델을 효율적으로 학습시킬 수 있습니다.
적절한 precision 사용: 필요에 따라 반정밀도(floating-point 16-bit, FP16) 연산을 사용하여 메모리 사용량을 줄이고, 연산 속도를 향상시킬 수 있습니다. PyTorch에서는 torch.cuda.amp를 사용하여 자동으로 mixed precision 학습을 적용할 수 있습니다.
예제 코드: 데이터 로더 최적화
from torch.utils.data import DataLoader
# 가정: 'dataset'은 이미 정의된 Dataset 객체입니다.
data_loader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=4, pin_memory=True)
예제 코드: Mixed Precision 학습
from torch.cuda.amp import GradScaler, autocast
model = ... # 모델 정의
optimizer = ... # 옵티마이저 정의
scaler = GradScaler()
for data, target in data_loader:
optimizer.zero_grad()
with autocast():
output = model(data)
loss = loss_fn(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
이러한 최적화 기법들은 GPU의 성능을 최대한 활용하여 학습 속도를 향상시키는 데 도움이 될 것입니다. 더 자세한 정보와 다양한 최적화 방법에 대해서는 PyTorch 공식 문서를 참고하시기 바랍니다.
제공된 정보가 충분하지 않아 구체적인 문제 해결에 직접적인 도움을 드리지 못한 점 양해 부탁드립니다. 추가적인 정보나 구체적인 문제 상황을 제공해주시면, 더 정확하고 유용한 답변을 드릴 수 있을 것입니다. 제 답변이 정확하지 않을 수도 있으니, 이 점 염두에 두시고 참고해주시기 바랍니다.
아래 답변은 Anthropic의 Claude-3 Opus 모델로 자동 생성한 것으로, 정확하지 않을 수 있습니다.
잘못된 답변을 보셨다면 댓글로 첨삭 지도 부탁드립니다.
안녕하세요 future0610님, GPU 성능 문제로 고민하시는 것 같네요.
먼저 요약해 보면, PyTorch 2.0.0+cu118 버전에 cuDNN 8.9.1 버전을 사용 중이시고, RTX 3090 Ti와 4090 GPU로 학습을 진행하셨는데 4090의 성능이 3090 Ti보다 오히려 떨어지는 문제가 발생한 것으로 보입니다. 특히 U-Net 모델로 Segmentation 작업을 수행할 때 GPU 사용률이 들쭉날쭉한 것이 관찰되었다고 하셨습니다.
아래 답변은 OpenAI의 GPT-4o 모델로 자동 생성한 것으로, 정확하지 않을 수 있습니다.
잘못된 답변을 보셨다면 댓글로 첨삭 지도 부탁드립니다.
안녕하세요! GPU 성능 문제로 고민이 많으시겠어요. 특히, 새로 구입한 RTX 4090이 기대만큼의 성능을 발휘하지 못하고 있는 상황이라면 더욱 답답하실 것 같습니다. 질문을 요약해보면, RTX 3090 Ti를 사용하는 컴퓨터에서는 정상적으로 작동하지만, RTX 4090을 사용하는 컴퓨터에서는 학습 속도가 느리고 GPU 사용률이 불안정하다는 문제를 겪고 계신 것 같습니다. 특히, ResNet으로 CIFAR-10을 학습할 때는 괜찮지만, UNet으로 segmentation 작업을 할 때 문제가 발생한다고 하셨네요.
이 문제를 해결하기 위해 몇 가지 점검해볼 사항들을 안내드리겠습니다.
CUDA 및 cuDNN 버전 확인:
PyTorch와 CUDA, cuDNN 버전이 호환되는지 확인해보세요. PyTorch 공식 문서에서 호환되는 버전을 확인할 수 있습니다.
NVIDIA 제어판에서 전원 관리 모드를 "최대 성능 선호"로 설정해보세요. 기본 설정이 "적응형"으로 되어 있을 수 있습니다.
CPU와 GPU 간 병목 현상:
CPU와 GPU 간의 데이터 전송이 병목이 될 수 있습니다. 특히, UNet과 같은 모델은 데이터 전송이 많기 때문에 병목이 발생할 수 있습니다.
데이터 로딩이 병목이 되는지 확인하기 위해 torch.utils.data.DataLoader의 num_workers 값을 조정해보세요.
코드 최적화:
PyTorch 코드에서 GPU 사용을 최적화하는 방법을 고려해보세요. 예를 들어, torch.cuda.synchronize()를 적절히 사용하여 GPU 작업이 완료될 때까지 기다리도록 할 수 있습니다.
예제 코드:
import torch
import torchvision.models as models
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10
# 모델 및 데이터셋 설정
model = models.resnet18().cuda()
transform = transforms.Compose([transforms.ToTensor()])
dataset = CIFAR10(root='./data', train=True, download=True, transform=transform)
dataloader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=4)
# 학습 루프
for epoch in range(10):
for inputs, labels in dataloader:
inputs, labels = inputs.cuda(), labels.cuda()
outputs = model(inputs)
loss = torch.nn.functional.cross_entropy(outputs, labels)
loss.backward()
torch.cuda.synchronize() # GPU 작업 완료 대기