model.gradient_checkpointing_enable() 코드가 궁금합니다 메모리적으로 이득이 있다고하는데
정확하게 어떤역할을 하는건지 모르겠네요.
오, Gradient Checkpointing을 처음 들어보았는데, 찾아보니 GPU에 한 번에 안 올라가는 모델을 학습하기 위한 테크닉 중에 하나였군요. (덕분에 하나 배웠습니다! +_+)
일단 설명과 코드와 벤치마크를 포함되어 있는 블로그 글을 발견하였는데, 한 번 읽어보시면 궁금하신 점이 어느정도 해결되시지 않을까 싶습니다. (나중에 여유가 생기면 언젠가 먼 훗날 번역해보겠습니다;; )
https://spell.ml/blog/gradient-checkpointing-pytorch-YGypLBAAACEAefHs
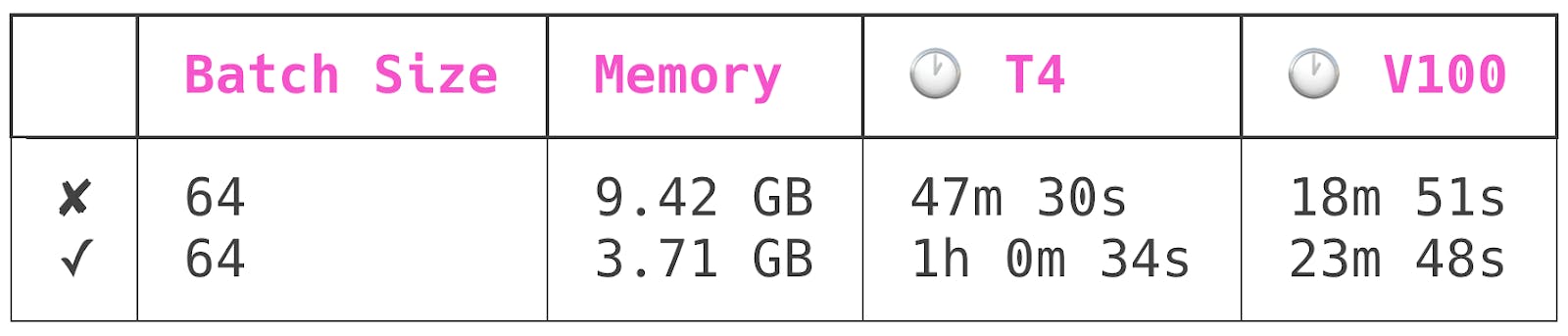
(밤이 늦어서 졸린 관계로 ![]() ) 글 앞 부분과 마지막 부분만 슬쩍 읽어봤는데, 메모리 사용량을 줄이는 대신 연산을 더 하는 테크닉인 것 같습니다. 글 말미에 벤치마크를 돌려봤을 때 연산 시간이 25% 가량 늘어나는 대신 메모리 사용량이 60% 가량 줄었다는 내용이 있네요.
) 글 앞 부분과 마지막 부분만 슬쩍 읽어봤는데, 메모리 사용량을 줄이는 대신 연산을 더 하는 테크닉인 것 같습니다. 글 말미에 벤치마크를 돌려봤을 때 연산 시간이 25% 가량 늘어나는 대신 메모리 사용량이 60% 가량 줄었다는 내용이 있네요.
Various techniques exist to ameliorate one or both of these problems. Gradient checkpointing is one such technique; distributed training, which we'd previously covered on this blog, is another.
Gradient checkpointing works by omitting some of the activation values from the computational graph. This reduces the memory used by the computational graph, reducing memory pressure overall (and allowing larger batch sizes in the process).
However, the reason that the activations are stored in the first place is that they are needed when calculating the gradient during backpropagation. Omitting them from the computational graph forces PyTorch to recalculate these values wherever they appear, slowing down computation overall.
Thus, gradient checkpointing is an example of one of the classic tradeoffs in computer science— that which exists between memory and compute.
I used Spell Runs to train this model four times: once each on an NVIDIA T4 and NVIDIA V100 GPU, and once each in checkpointed and uncheckpointed modes. All runs had a batch size of 64. Here are the results:
The first row has training runs conducted with model checkpointing off, the second with it on.
Model checkpointing reduced peak model memory usage by ~60%, while increasing model training time by ~25%.
혹시나 자세히 살펴보시게 된다면, 정보 공유 게시판에도 글 한 번 부탁드립니다. ![]()
2개의 좋아요
저도 새로운 정보 하나 알아갑니다!
옹 감사합니다! 저도 많이 배우고 갑니다
이 글은 마지막 댓글이 달린지 오래(30일)되어 자동으로 닫혔습니다. 댓글 대신 새로운 글을 작성해주세요! ![]()