import argparse
import torch
from torch import no_grad, LongTensor
import commons
import utils
import gradio as gr
from models import SynthesizerTrn
from text import text_to_sequence, _clean_text
def get_text(text, hps):
text_norm = text_to_sequence(text, hps.data.text_cleaners)
if hps.data.add_blank:
text_norm = commons.intersperse(text_norm, 0)
text_norm = torch.LongTensor(text_norm)
return text_norm
def create_tts_fn(model, hps, speaker_ids):
def tts_fn(text, speaker, speed, noise_scale, noise_scale_w):
speaker_id = speaker_ids[speaker]
stn_tst = get_text(text, hps)
with no_grad():
x_tst = stn_tst.cuda().unsqueeze(0)
x_tst_lengths = LongTensor([stn_tst.size(0)]).cuda()
sid = LongTensor([speaker_id]).cuda()
audio = model.infer(x_tst, x_tst_lengths, sid=sid, noise_scale=noise_scale,
noise_scale_w=noise_scale_w, length_scale=1.0 / speed)[0][0, 0].data.cpu().float().numpy()
del stn_tst, x_tst, x_tst_lengths, sid
return "Success", (hps.data.sampling_rate, audio)
return tts_fn
def create_to_phoneme_fn(hps):
def to_phoneme_fn(text):
return _clean_text(text, hps.data.text_cleaners) if text != "" else ""
return to_phoneme_fn
css = """
#advanced-btn {
color: white;
border-color: black;
background: black;
font-size: .7rem !important;
line-height: 19px;
margin-top: 24px;
margin-bottom: 12px;
padding: 2px 8px;
border-radius: 14px !important;
}
#advanced-options {
display: none;
margin-bottom: 20px;
}
"""
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--config_path", required=True,
help="path to config file")
parser.add_argument("--model_path", required=True,
help="path to model file")
args = parser.parse_args()
models_tts = []
name = 'VITS-TTS demo v1.01'
example = '학습은 잘 마치셨나요? 좋은 결과가 있길 바래요.'
config_path = args.config_path
model_path = args.model_path
hps = utils.get_hparams_from_file(config_path)
model = SynthesizerTrn(
len(hps.symbols),
hps.data.filter_length // 2 + 1,
hps.train.segment_size // hps.data.hop_length,
n_speakers=hps.data.n_speakers,
**hps.model).cuda()
utils.load_checkpoint(model_path, model, None)
model.eval()
speaker_ids = [sid for sid, name in enumerate(
hps.speakers) if name != "None"]
speakers = [name for sid, name in enumerate(
hps.speakers) if name != "None"]
models_tts.append((name, speakers, example,
hps.symbols, create_tts_fn(model, hps, speaker_ids),
create_to_phoneme_fn(hps)))
app = gr.Blocks(css=css)
with app:
gr.Markdown("Gradio VITS-TTS Inference demo v1.01\n\n")
with gr.Tabs():
for i, (name, speakers, example, symbols, tts_fn,
to_phoneme_fn) in enumerate(models_tts):
with gr.TabItem(f"VITS-TTS_v1.01"):
with gr.Column():
gr.Markdown(f"## {name}\n\n")
tts_input1 = gr.TextArea(label="Text", value=example,
elem_id=f"tts-input{i}")
tts_input2 = gr.Dropdown(label="Speaker", choices=speakers,
type="index", value=speakers[0])
tts_input3 = gr.Slider(label="Speed", value=1, minimum=0.1, maximum=2,
step=0.05)
noise_scale_slider = gr.Slider(label="Noise-scale (defaults = 0.667)",
value=0.667, minimum=0, maximum=1, step=0.01)
noise_scale_w_slider = gr.Slider(label="Noise-width (defaults = 0.8)",
value=0.8, minimum=0, maximum=2, step=0.05)
tts_submit = gr.Button("Generate", variant="primary")
tts_output1 = gr.Textbox(label="Output Message")
tts_output2 = gr.Audio(label="Output Audio")
tts_submit.click(tts_fn, [tts_input1, tts_input2, tts_input3,
noise_scale_slider, noise_scale_w_slider],
[tts_output1, tts_output2])
gr.Markdown(
"Originate from \n\n"
"- [https://github.com/kdrkdrkdr]\n\n"
)
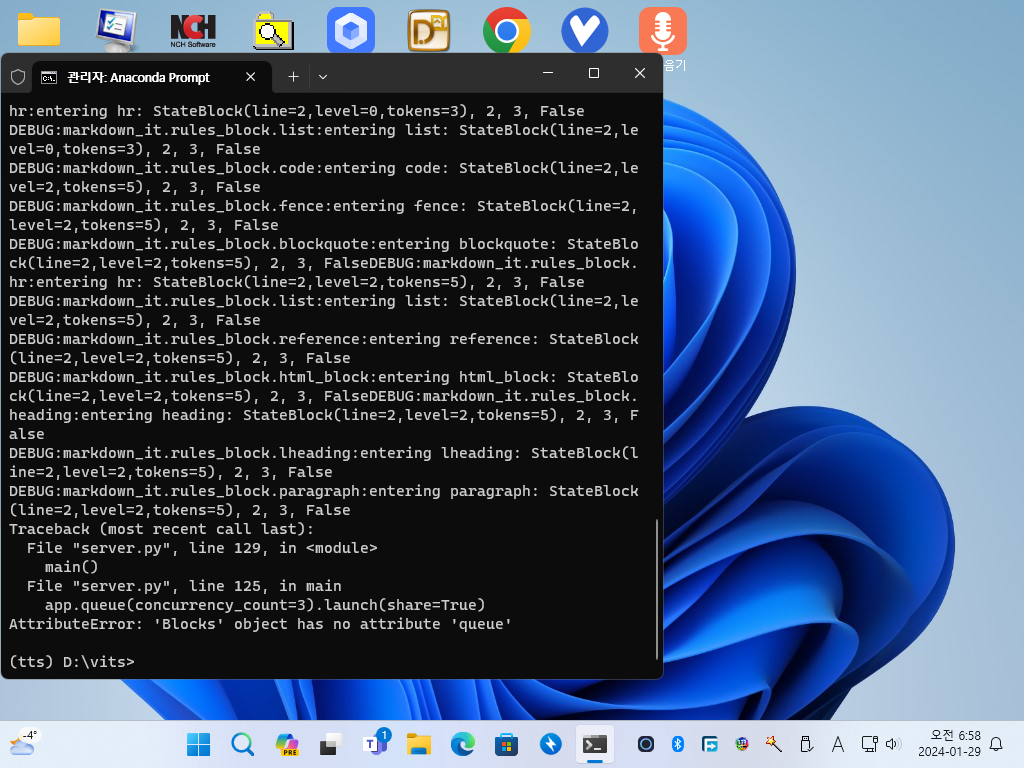
app.queue(concurrency_count=3).launch(share=True)
if name == "main":
main()
몇달전까지만해도 이 코드가 실행이 되었습니다.
명령어는 다음과 같습니다.
python server.py --config_path path/to/config.json --model_path path/to/model.pth
오류 내용을 첨부하고 싶은데 아나콘다가 업데이트 되면서 화면 내용을 복사 붙여넣기하는 기능이 동작을 하지 않아 부득이하게 오류 내용을 첨부하지는 못 하고 있습니다.
몇달 잘 사용했는데 뭐 어쩌다보니 아나콘다를 재 설치 하게 되었습니다.
아나콘다 설치 후 전 python 3.7버전으로 설치했습니다.
vits를 사용할때 3.7을 설치했으니까요.
그런데 python.exe -m pip install --upgrade pip를 입력하라는 오류 메시지가 계속 나오는 겁니다.
당연히 입력했는데 pip 업그레이드에 실패했습니다.
그래서 3.8로 재 설치했습니다.
그런데 이번에는 gradio가 설치는 되는데 이게 실행이 되지 않고 있습니다.
로그 내용 표시하고 거기서 멈춰야하는데 그냥 gradio가 종료되버리고 아나콘다는 폴더 표시를 합니다.
ms 코파일럿에게 요청해 어찌저찌 1버전 부터 2버전 까지 재 설치 해봤지만 전부 무슨 모듈이 없다는 메시지만 출력했습니다.
그리고 최종 4 버전을 설치했는데 gradio가 실행 되기는커녕 오히려 종료되버립니다.
위 코드가 문제가 생긴거 같은데 전 코알못이므로 도움을 요청합니다.
스크린샷을 저장해서 업로드합니다.