소개
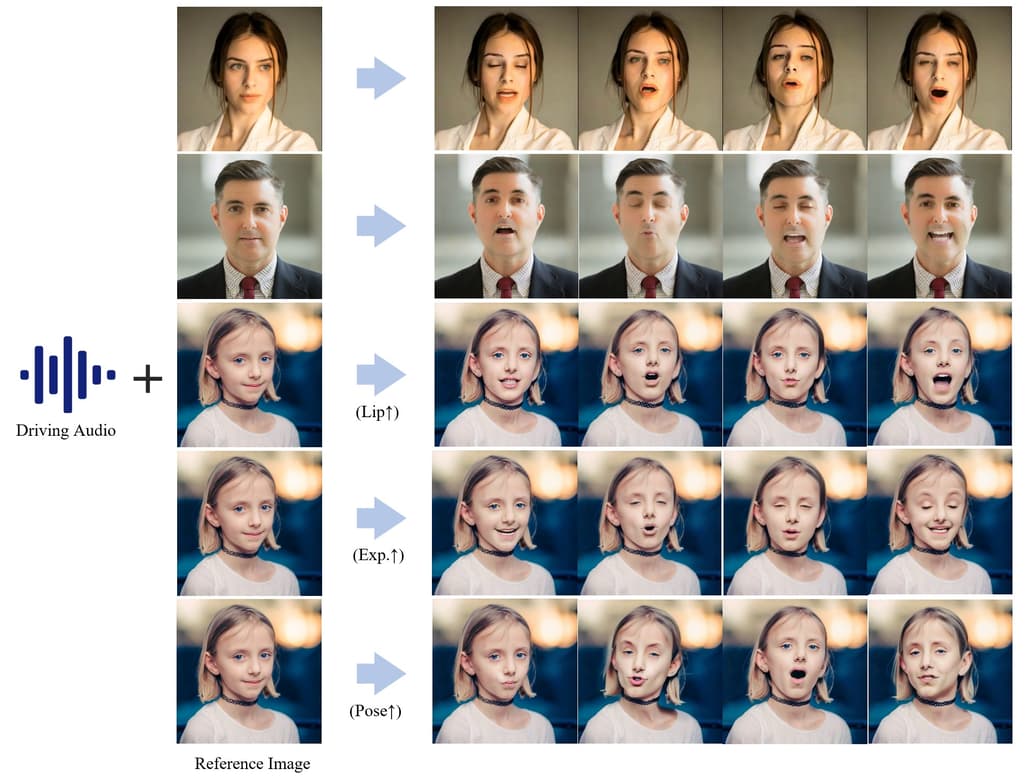
Hallo 프로젝트는 인물 사진을 기반으로 영상을 생성하기 위해 음성 데이터를 활용하는 인공지능 기술입니다. 이 프로젝트는 기존의 이미지 및 비디오 생성 기술과는 차별화된 접근 방식을 채택하고 있습니다. 음성을 이용한 애니메이션 생성 기술은 최근 여러 연구에서 주목받고 있으며, Hallo는 이러한 기술을 더욱 발전시킨 모델을 제공합니다.
특히, Hallo는 다음과 같은 기술적 특징을 가지고 있습니다:
-
계층적 접근 방식: 이미지의 다양한 레벨에서 세밀한 조정을 가능하게 합니다.
-
음성 기반 애니메이션 생성: 음성을 통해 얼굴의 표정과 움직임을 자연스럽게 구현합니다.
-
다양한 프레임워크 지원: 기존의 여러 기술을 통합하여 높은 품질의 애니메이션을 생성합니다.
이 기술은 특히 영화, 게임, 가상 현실 등 다양한 분야에서 응용 가능성이 높아, 향후의 기술 발전에 큰 영향을 미칠 것으로 기대됩니다.
주요 특징
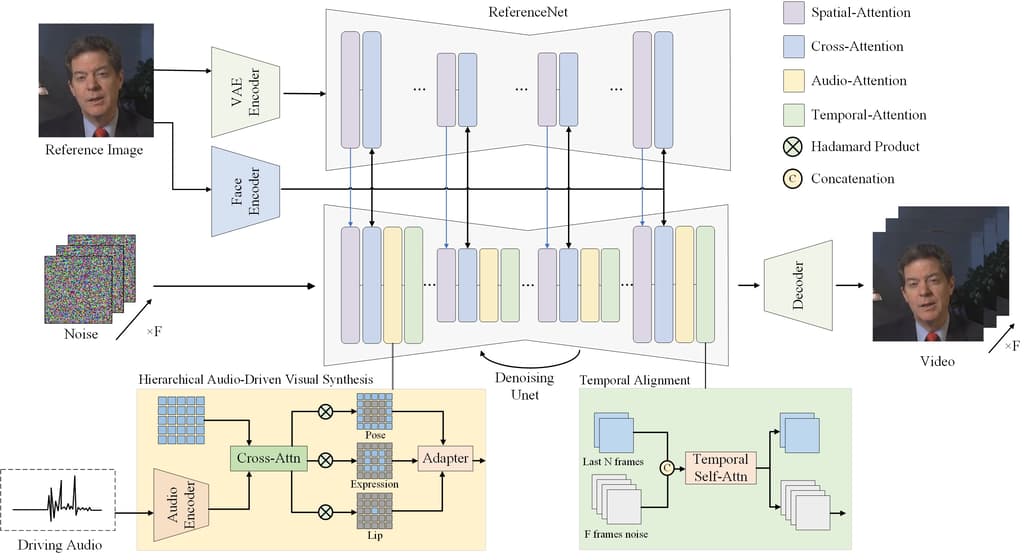
Hallo의 주요 특징을 정리하면 다음과 같습니다:
-
계층적 구조: 얼굴의 세부적인 부분까지 정밀하게 조정할 수 있는 계층적 구조를 채택하였습니다.
-
음성 인식 기술: 음성 데이터를 분석하여 얼굴 애니메이션의 움직임을 자연스럽게 생성합니다.
-
다양한 모델 통합: 여러 사전 학습된 모델을 통합하여, 높은 정확도와 효율성을 자랑합니다. 주요 모델로는 denoising UNet, face locator, image & audio proj 등이 있습니다.
라이선스
이 프로젝트는 MIT License로 공개 및 배포되고 있습니다. 상업적 사용에 대한 제한 사항이 없으므로 자유롭게 사용할 수 있습니다.
 Hallo GitHub 저장소
Hallo GitHub 저장소
 Hallo 모델 다운로드
Hallo 모델 다운로드
 Hallo 논문
Hallo 논문
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()