
Heretic 소개
최근 대규모 언어 모델(LLM)은 '안전성 얼라인먼트(safety alignment)'라는 과정을 거칩니다. 이는 모델이 일반적으로 사용자 또는 인간에게 유해하거나 부적절할 수 있는 요청에 대해 "도와드릴 수 없습니다"와 같은 거부 응답을 하도록 학습하는 과정을 의미합니다. 이러한 안전 장치는 중요하지만, 때로는 연구나 특정 응용 분야에서 모델의 응답 범위를 제한하는 요소로 작용하기도 합니다. 모델에서 이러한 검열 기능을 제거하려는 시도, 즉 '탈검열(decensoring)'은 일반적으로 상당한 비용이 드는 추가적인 사후 학습(post-training)이나 별도의 미세 조정(fine-tuning) 과정을 필요로 했습니다.
Heretic은 바로 이 지점에서 등장한 도구입니다. Heretic은 값비싼 재학습 과정 없이 트랜스포머(transformer) 기반 언어 모델의 검열, 즉 안전 얼라인먼트를 자동으로 제거하는 도구입니다. 이 도구의 핵심은 Arditi et al. 2024이 제안한 'Abliteration'이라고도 알려진 '방향성 절제(directional ablation)'라는 고급 기술을 구현한 데 있습니다. Heretic은 이 기술을 Optuna에 기반한 TPE(Tree-structured Parzen Estimator) 파라미터 옵티마이저와 결합하여, 탈검열 과정을 완전 자동화했습니다.
Heretic이 작동하는 방식은 매우 지능적입니다. 이 도구는 두 가지 상충될 수 있는 목표, 즉 (1) 모델의 거부 응답 횟수 최소화와 (2) 원본 모델과의 KL 발산(KL divergence) 최소화를 동시에 달성하는 방향으로 최적의 절제(ablation) 파라미터를 탐색합니다. 여기서 KL 발산 값이 낮다는 것은, 탈검열 과정에서 모델이 원래 가지고 있던 지능이나 고유한 능력에 손상이 거의 가지 않았음을 의미합니다.
이러한 자동화 덕분에 Heretic은 트랜스포머 모델의 내부 구조에 대한 깊은 이해가 없는 개발자라도 누구나 커맨드 라인 프로그램을 실행할 수 있다면 사용할 수 있도록 설계되었습니다. 복잡한 설정이나 전문 지식 없이도 고품질의 탈검열 모델을 생성할 수 있다는 것이 Heretic의 가장 큰 장점입니다.
기존 탈검열 모델과의 비교
Heretic의 성능은 단순히 검열을 제거하는 것을 넘어, 원본 모델의 품질을 얼마나 잘 보존하는지로 평가할 수 있습니다. Heretic GitHub 저장소에서는 google/gemma-3-12b-it 모델을 기반으로 한 비교 데이터를 제공합니다.
| 모델 | "유해한" 프롬프트에 대한 거부 응답 | "무해한" 프롬프트에 대한 원본 모델과의 KL 발산 |
|---|---|---|
google/gemma-3-12b-it (원본) |
97/100 | 0 (기준) |
mlabonne/gemma-3-12b-it-abliterated-v2 |
3/100 | 1.04 |
huihui-ai/gemma-3-12b-it-abliterated |
3/100 | 0.45 |
p-e-w/gemma-3-12b-it-heretic (Heretic 적용) |
3/100 | 0.16 |
위 표에서 볼 수 있듯이, Heretic으로 생성된 버전(ours)은 전문가가 수동으로 튜닝한 다른 탈검열 모델들과 동일한 수준의 낮은 거부 응답률(3/100)을 달성했습니다.
가장 주목할 점은 KL 발산(KL divergence) 값입니다. Heretic 버전은 0.16이라는 압도적으로 낮은 KL 발산 값을 기록했습니다. 이는 다른 모델들(1.04, 0.45)에 비해 원본 모델의 지능과 응답 특성을 훨씬 더 잘 보존하고 있다는 것을 의미합니다. 즉, Heretic은 인간의 노력 없이도 더 적은 '손상'으로 더 우수한 품질의 탈검열 모델을 자동으로 생성해냅니다.
Heretic의 동작 원리
Heretic은 '방향성 절제(directional ablation)'의 매개변수화된 변형(parametrized variant)을 구현합니다. 이 과정은 모델의 특정 '생각'이나 '개념'을 나타내는 방향을 찾아 해당 방향을 억제하는 방식으로 작동합니다.
-
"거부 방향"의 계산: Heretic은 먼저 "유해한(harmful)" 예시 프롬프트와 "무해한(harmless)" 예시 프롬프트 각각에 대해 모델의 첫 번째 토큰 잔차(first-token residuals)를 계산합니다. 그리고 이 두 그룹 간의 '평균 차이(difference-of-means)'를 계산하여 각 레이어별로 "거부 방향(refusal direction)"을 식별합니다. 이 벡터가 바로 모델이 "이 요청을 거부해야겠다"고 판단하는 핵심적인 신호가 됩니다.
-
방향성 절제 수행: 거부 방향을 찾은 후, Heretic은 트랜스포머의 특정 구성 요소(현재는 어텐션의 출력 프로젝션과 MLP의 다운 프로젝션)에 접근합니다. 그리고 해당 구성 요소의 가중치 행렬을 식별된 "거부 방향"에 대해 직교화(orthogonalizes)합니다. 이 과정을 통해 해당 행렬이 곱셈 연산을 수행할 때 거부 방향에 해당하는 표현이 결과에 포함되지 않도록 억제합니다.
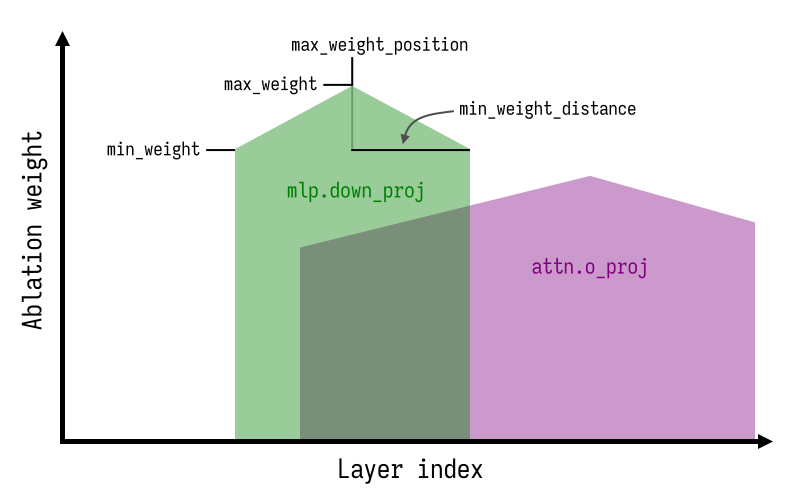
이 절제 과정은direction_index,max_weight,min_weight등 최적화 가능한 여러 매개변수에 의해 제어되며, 이 매개변수들은 레이어 전반에 걸친 '절제 가중치 커널(ablation weight kernel)'의 모양과 위치를 정의합니다.
Heretic의 주요 개선 사항
Heretic은 기존의 다른 'abliteration' 시스템보다 뛰어난 성능을 보이며, 이를 가능케 한 몇 가지 주요 개선 사항들이 있습니다:
-
유연한 절제 가중치 커널 Heretic은 레이어별로 적용되는 절제 가중치의 '모양(shape)'을 매우 유연하게 정의합니다. 이 커널의 형태는 자동 파라미터 최적화(Optuna)에 의해 결정되며, 이를 통해 모델의 응답 순응도(compliance)와 품질(quality) 간의 상충 관계(trade-off)를 최적의 지점으로 개선할 수 있습니다.
-
부동소수점(float) 단위의
direction_index: 기존 방식에서는 특정 레이어 하나에서 계산된 정수(integer) 인덱스의 거부 방향을 사용했습니다. 반면 Heretic은 이 인덱스를 부동소수점(float)으로 처리합니다. 만약 값이 정수가 아니라면, 가장 가까운 두 개의 거부 방향 벡터를 선형 보간(linearly interpolated)하여 사용합니다. 이 접근 방식은 개별 레이어에서 식별된 방향 외에 훨씬 더 방대한 추가 방향 공간을 탐색할 수 있게 하며, 종종 최적화 과정에서 더 나은 방향을 찾는 데 성공합니다. -
컴포넌트별 개별 파라미터 적용: Heretic은 모델의 모든 구성 요소에 동일한 절제 가중치를 적용하지 않습니다. 연구에 따르면, 어텐션(attention) 개입보다 MLP 개입이 모델의 원본 능력에 더 큰 '손상'을 주는 경향이 있습니다. Heretic은 이 점을 인지하고 각 컴포넌트(어텐션, MLP)에 대해 서로 다른 절제 가중치를 개별적으로 최적화하여 적용합니다. 이를 통해 불필요한 성능 저하를 최소화하고 추가적인 성능을 확보합니다.
Heretic 사용 방법
Heretic을 설치하기 위해서는 Python 3.10 이상, PyTorch 2.2 이상이 설치되어 있어야 합니다.
Heretic의 설치는 터미널에서 pip 명령어를 통해 간단히 설치할 수 있습니다.
pip install heretic-llm
설치 후에는 heretic 명령어를 사용하여 원하는 Hugging Face 모델을 지정하기만 하면 됩니다.
heretic Qwen/Qwen3-4B-Instruct-2507
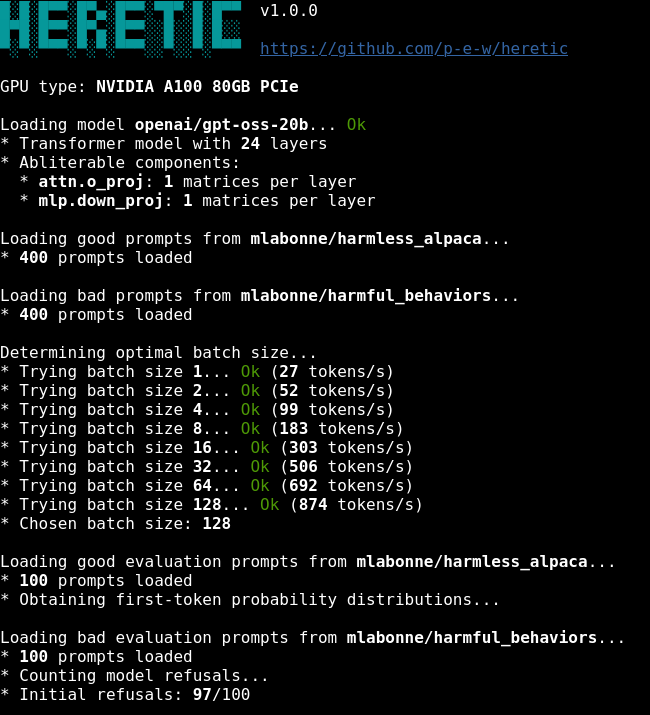
프로그램이 실행되면, Heretic은 먼저 시스템을 벤치마킹하여 사용 가능한 하드웨어를 최대한 활용할 수 있는 최적의 배치 크기를 결정합니다. 예를 들어, RTX 3090에서 기본 구성으로 Llama-3.1-8B 모델의 검열을 제거하는데 약 45분 가량이 소요됩니다.
프로세스가 완료되면, Heretic은 사용자에게 생성된 모델을 로컬에 저장하거나, Hugging Face에 업로드하거나, 혹은 직접 채팅을 통해 탈검열이 잘 되었는지 테스트할 수 있는 옵션을 제공합니다.
지원 모델
Heretic은 대부분의 밀집(dense) 모델, 다수의 멀티모달 모델, 그리고 여러 MoE(Mixture-of-Experts) 아키텍처를 지원합니다. 다만, 아래와 같은 구조의 모델들은 아직 지원하지 않습니다:
- SSM(Mamba 등) 및 하이브리드 모델
- 불균일한 레이어(inhomogeneous layers)를 가진 모델
- 일부 새로운 유형의 어텐션 시스템
라이선스
Heretic 프로젝트는 GNU Affero General Public License v3.0 (AGPL-3.0) 라이선스로 공개 및 배포되고 있습니다. AGPL-3.0은 다소 강력한 카피레프트 조항을 포함하며, 특히 프로그램을 수정하여 네트워크를 통해 서비스할 경우, 해당 수정된 소스 코드 또한 동일한 라이선스로 사용자에게 제공해야 할 의무가 있습니다. 상세한 내용은 라이선스 원문을 참고해주세요.
 Heretic 프로젝트 GitHub 저장소
Heretic 프로젝트 GitHub 저장소
https://github.com/p-e-w/heretic
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()